基于深度学习的狗鼻纹身份识别
基于深度学习的狗鼻纹身份识别
1. 技术背景
根据GMI报告,2020年全球宠物护理市场规模超过2320亿美元。随着宠物经济的快速发展,宠物福利问题日益突出。在宠物管理、交易、保险、医疗等许多场景中,宠物识别是一个具有挑战性的问题,目前还没有一个很好地平衡准确性、成本和可用性的解决方案。相比之下,基于视觉的模式识别(如人脸、指纹、虹膜等)在人类生物识别中已经成功应用了很长时间。一个有趣的问题是:我们能否将这些技术转移到宠物生物识别技术上?
研究表明,狗可以通过鼻子上面的纹路来辨别是不是同一只狗,每一只狗鼻子上面的编号都是独一无二的,因此可以使用它们来作为识别狗的一种方式,它的作用等同于人类手指上的指纹。
基于此,我们可以采取基于深度学习的图像识别技术,对包含狗鼻子的图像一一比对,判断是否为同一只狗。
2. 数据集
https://aistudio.baidu.com/aistudio/datasetdetail/151224
其中,有6000个狗狗id,20000个狗狗鼻纹图像

3. 狗鼻纹身份识别实现思路
3.1 模型选择
由于数据集给出了每只狗的鼻纹图像数据,而每只狗的鼻纹数据都是独一无二的,这点类似于人脸以及人的指纹,于是我们可以借鉴人脸识别模型来训练狗鼻纹的识别。常见的人脸识别模型有Facenet和Arcface等。
由于在精度上,Arcface效果比Facenet好,如下表Arcface与Facenet,为在狗鼻纹数据集上的效果对比,其中:
Accuracy:表示为(两只狗是同一只狗预测正确的数量+两只狗不是同一只狗预测正确的数量)/总数
Validation rate:表示为两只狗是同一只狗预测正确的数量/两只狗是同一只狗实际数量
FAR:表示为两只狗不是同一只狗预测错误的数量/两只狗不是同一只狗实际数量
| Arcface | Facenet | |
|---|---|---|
| Accuracy | 99.988% | 77.379%+ |
| Validation rate | 99.971% | 31.951% |
| FAR | 0.00099 | 0.00120 |
所以我们选择Arcface。
3.2 模型预测
3.2.1 主干网络介绍
Arcface的主干网络有特征提取的作用,原版论文中使用的主干网络是iresnet。
由于设备资源有限,本项目使用的是Mobilenetv1作为主干网络。MobilenetV1模型是Google针对手机等嵌入式设备提出的一种轻量级的深层神经网络,其使用的核心思想便是depthwise separable convolution(深度可分离卷积块)。
深度可分离卷积块由两个部分组成,分别是深度可分离卷积和1x1普通卷积,深度可分离卷积的卷积核大小一般是3x3的。
下图为深度可分离卷积块的结构示意图:
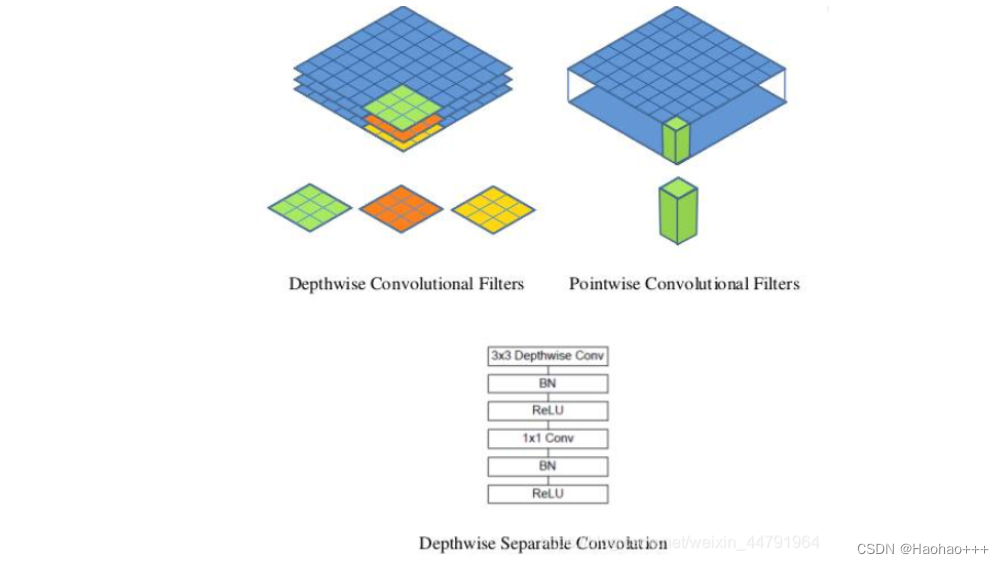
深度可分离卷积块的目的是使用更少的参数来代替普通的3x3卷积。
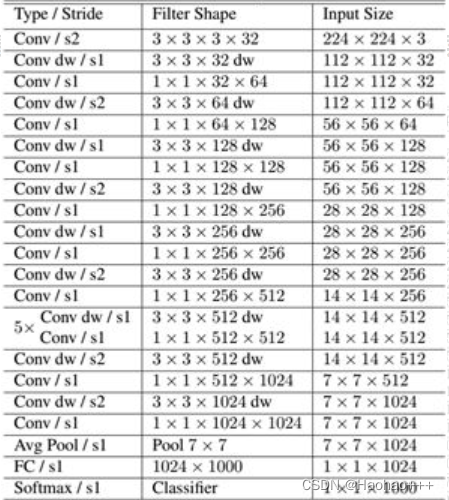
其MobileNet的结构如下,其中Conv dw就是深度可分离卷积块。
3.2.2 特征向量的处理
利用主干特征提取网络我们可以获得一个特征层,将这个特征层平铺,之后与一个神经元个数为512进行全连接。此时我们相当于利用了一个长度为128的特征向量代替输入进来的图片,这个长度为128的特征向量就是输入图片的特征浓缩。
在获得一个长度为128的特征向量后,我们还需要进行l2标准化的处理。这个L2标准化是为了使得不同人脸的特征向量可以属于同一数量级,方便比较。L2标准化就是每个元素除以L2范数。
到这里,我们输入进来的图片,已经变成了一个经过l2标准化的长度为512的特征向量了!
3.2.3 预测
当我们完成特征向量的处理后,我们已经可以利用这个预测结果进行预测了。
1. 狗狗一对一身份验证
我们可以利用两张狗狗图片分别输入网络,得到两种图片的特征向量,再通过设定一个阈值,计算两张特征向量的欧式距离,若欧式距离大于设定的阈值,则不为同一只狗;若欧式距离小于设定的阈值,则为同一只狗。
如下图,第一张图片为同一只狗的鼻纹,第二张图片为不同狗的鼻纹,欧式距离可以设置为1,进行区分。
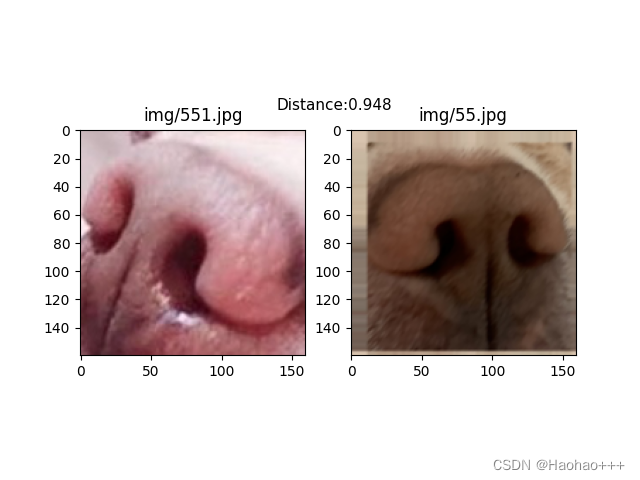
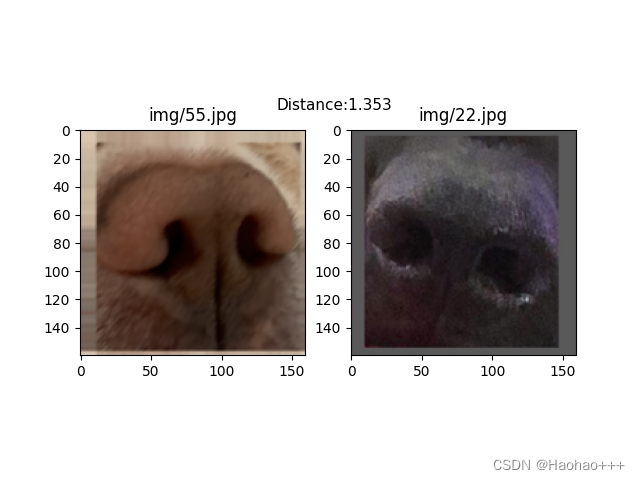
2. 狗狗一对多身份验证
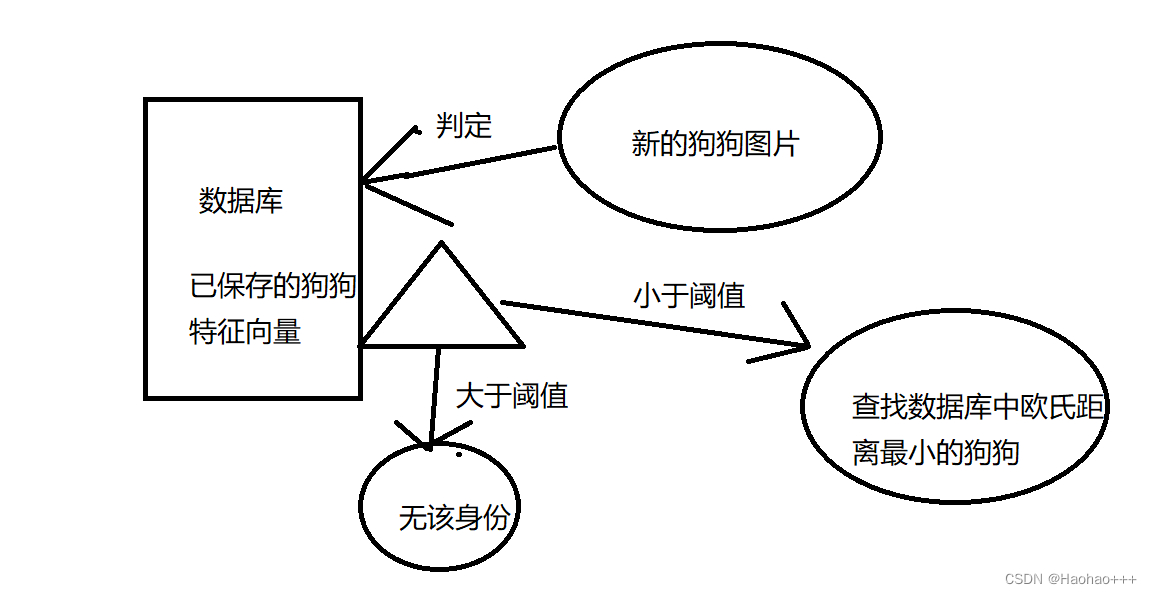
我们可以先将要保存狗狗身份的图片通过模型提取出特征向量进行保存,对于之后要识别的狗,先通过模型提取出特征向量,再将该特征向量与数据库中保存的特征向量计算欧式距离,然后设定一个阈值用于判断狗的身份,若该特征向量与数据库中保存的特征向量计算的欧式距离小于设定的阈值,则再从数据库中找到与该特征向量欧氏距离最小的特征向量,该最小特征向量对应的狗狗就是要识别狗狗的身份;若该特征向量与数据库中保存的特征向量计算的欧式距离大于设定的阈值,则该特征向量对应的狗狗不在要查询的数据库中。
流程图如下:郑智雄在制作PPT时,请重新画,需要美观。
3.3 模型训练
3.3.1 训练的损失函数
利用3.2.2最终的特征向量来训练得到分类损失。
Arcface中使用的LOSS为Additive Angular Margin Loss。
公式如下:
其中 θ \theta θ代表处理后的特征向量与权重的夹角。
下列公式就是将 c o s ( θ y i + m ) cos(\theta_{y_i} + m) cos(θyi+m)应用到Softmax损失函数中, θ y i \theta_{y_i} θyi为当处理后的特征向量与该特征向量相同种类的权重的夹角; θ j \theta_{j} θj为当处理后的特征向量与该特征向量其它种类的权重的夹角。 m m m为惩罚项,用来调整相同种类的 θ \theta θ,使得相同种类的 θ \theta θ更小。

分析:通过公式可以看出,不同种类的 θ \theta θ越大,相同种类的 θ \theta θ越小时,整体损失值就会下降,就代表着相同种类输出的特征向量更加聚合,不同种类输出的特征向量差异就会更大,最后模型训练出来的分类效果就更好了。
训练策略
| 训练轮次 | 优化器 | 主干网络 | 网络输入图片大小 | 学习率调整策略 | 数据预处理 |
|---|---|---|---|---|---|
| 100 | SGD | mobilenetv1 | 160x160 | 余弦退火 | 随机图像翻转 |