2025年MathorCup数学应用挑战赛D题问题一求解与整体思路分析
D题 短途运输货量预测及车辆调度
问题背景
问题分析:四个问题需要建立数学模型解决就业状态分析与预测,旨在通过数学建模对宜昌地区的就业数据进行深入分析,并基于此预测就业状态。提供的数据涵盖了被调查者的个人信息、就业信息、失业信息等,数据较为复杂且涉及多个因素。此问题的核心是通过特征分析识别就业状态的影响因素,并构建预测模型来预测就业状态。
附件1 提供了每个车队负责的线路及相关信息,包括每条线路的发运时间、在途时长、变动成本等。
附件2 提供了历史15天的实际包裹量数据,可以用于验证模型的准确性。
附件3 提供了预测货量数据,可以作为模型的输入。
附件4 提供了可串点的站点集合,能够帮助优化串点任务。
附件5 提供了每个车队的自有车数量,用于计算车辆的调度能力和优化。
问题1分析:货量预测问题
思路分析:需要预测未来1天各条短途线路的货量,并将预测的货量拆解到10分钟颗粒度。建立一个货量预测模型,解决三大挑战:计划线路可能与实际不符,未涵盖部分未下单的货量,已下单的货量可能取消,预测的结果将用于后续的车辆调度。
1、数据预处理
需要对附件3中的“预知货量”数据进行清洗和归一化处理。对于数据中的异常值(如发运异常或包裹取消),可以使用滑动窗口法或者数据平滑技术来降低其影响。
拆解至10分钟颗粒度:将每日的货量预测结果按时间段拆解,可以使用线性插值法或者根据历史数据的时段分布,使用加权平均法进行拆分。
| 字段名称 | 附件1缺失值 | 附件2缺失值 | 附件3缺失值 |
| 线路编码 | 0 | 0 | 0 |
| 起始场地 | 0 | — | — |
| 目的场地 | 0 | — | — |
| 发运节点 | 0 | — | — |
| 车队编码 | 0 | — | — |
| 在途时长 | 0 | — | — |
| 自有变动成本 | 0 | — | — |
| 外部承运商成本 | 0 | — | — |
| 日期 | — | 0 | 0 |
| 分钟起始 | — | 0 | — |
| 包裹量 | — | 0 | 0 |
数据清洗前后对比:
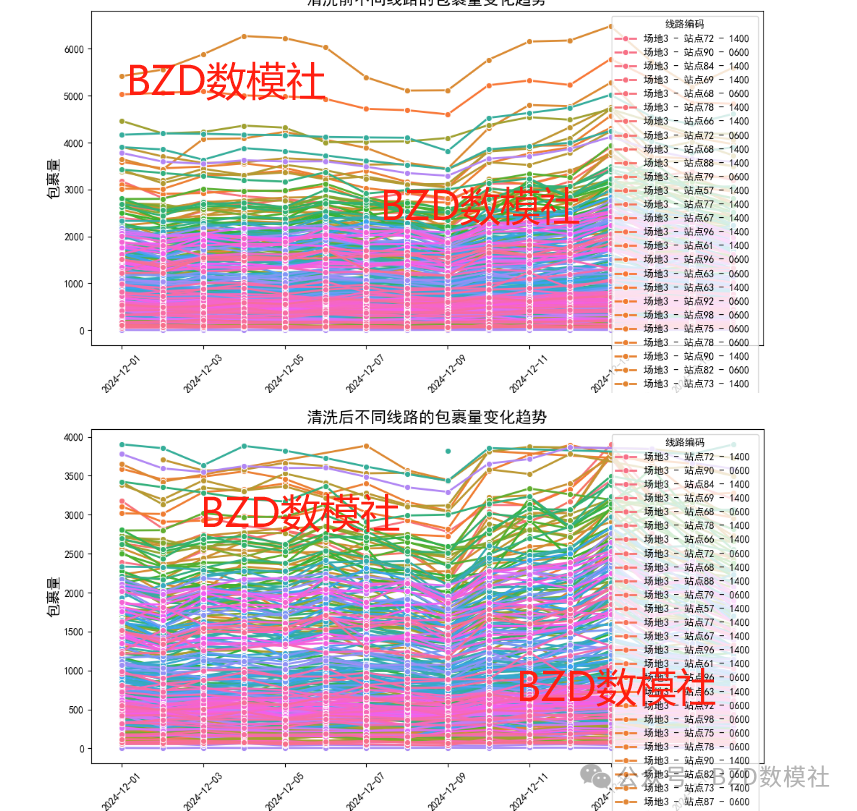
2、模型选择
由于数据是时序性的,对比LSTM和XGboost的误差与运行效率,选择机器学习模型XGboost作为货量预测模型。
约束与关键条件:
(1)时间范围:货量预测需要拆解到10分钟颗粒度,预测的时间范围为12月15日14:00至12月16日14:00,共144个10分钟间隔。
(2)预测数据处理:使用历史数据(附件2)来训练货量预测模型(如XGBoost)。未来1天的预知货量(附件3)应作为模型的输入数据,预测出未来货量。
(3)拆解总货量:将每条线路的总货量拆解到10分钟的颗粒度。预测结果需要拆解到10分钟间隔的数据;
(4)预测结果填充:填充结果表1和结果表2中的货量数据,并确保对于线路编码为“场地3 - 站点83 – 0600”和“场地3 - 站点83 – 1400”的线路给出具体的预测结果。
对每个时间点进行多步预测:我们应该根据历史数据为每条线路生成144个时间点的预测结果,而不仅仅是一个值。使用滑动窗口的方法,通过时间序列的特性,逐步预测未来的每个时间点的货量,而不是一次性预测一个值。
问题2分析:运输需求分析
根据问题 1 输出的结果,确定运输需求,包括每条线路的发运车辆数、预计发运时间及串点方案,其中每个需求的发运时间不能晚于线路的发运节点。基于以上结果,确定每个需求的承运车辆;要求自有车的周转率尽可能高,以及所有车辆均包裹尽可能高、总成本尽可能低。请将结果写入结果表 3中,结果需包含:线路编码、预计发运时间、承运车辆。其中串点方案可将多条线路编码合并在“线路 ”一列展示,无法使用自有车满足时注明为“外部 ” ,并在论文中给出线路编码为“场地3- 站点83- 0600”和“场地3- 站点83- 1400”的调度结果。
思路分析:根据问题1的货量预测,确定每条线路的运输需求,包括发运车辆数、预计发运时间以及串点方案。尽量提高自有车辆的周转率,确保车辆均包裹数尽可能高,总成本尽可能低。
1、运输需求计算
根据每条线路的包裹量和车辆的载运能力,计算出每条线路的需求车次。对于“串点”场景,选择合适的线路进行合并,根据包裹量是否达到满载来判断是否合并。
2、车辆调度优化
用整数规划(Integer Programming)或者线性规划(Linear Programming)方法来确定每条线路的发运时间和车辆调度方案,确保自有车的周转率最大化,并尽量减少外部承运商的使用。
目标函数:需要优化自有车的使用率、车辆包裹数,并最小化总成本(自有车成本 + 外部承运商成本)。对于需要使用外部车辆的情况,可以通过设置约束条件来确保这些车辆的使用最小化。
1、数据准备:使用问题1中得出的10分钟颗粒度的货量数据,作为各条线路的运输需求基础。根据每条线路的预计包裹量和每车次的装载量(1000个包裹),计算需要的发运车辆数。
2、串点方案:对于临近的线路(包裹量较少的情况),可以进行串点发运,即多个线路的货量合并为一车发运。使用附件4(可串点的站点集合)来确定哪些线路可以串点。对于每个串点任务,若合并后的包裹量超过车辆的容量(1000个包裹),则可以安排一辆车进行运输。
3、优化目标:
自有车周转率:计算自有车的周转率,尽量使用自有车辆,以降低成本。自有车周转率= 自有车承运总需求数 / 车队自有车辆数。
车辆均包裹:每辆车的承运包裹量,尽量确保每辆车满载。车辆均包裹= 总承运包裹量 / (自有车辆数 + 外部承运商车辆数)。
成本最小化:结合附件1中的成本信息(如固定成本、变动成本等),尽量减少使用外部承运商的情况。
4、输出:根据这些计算结果,确定每条线路的发运时间、承运车辆以及串点方案,并输出到结果表3中。
1. 运输需求计算
对于每条线路,我们首先基于问题1中预测的货量数据,计算每条线路的需求车次。每个车次的包裹量上限为1000个包裹,因此可以通过以下公式计算每条线路的需求车次:
其中,包裹量为每条线路在10分钟颗粒度下的总货量。
2.车辆调度优化
车辆调度目标是通过最大化自有车的周转率,最小化外部承运商的使用量,并确保每辆车的载运能力尽可能高。为了实现这一目标,我们可以使用整数规划或线性规划来进行优化。目标函数和约束条件如下。
目标函数:
1.自有车周转率最大化:自有车的周转率反映了自有车辆的使用效率,公式为:
2.车辆均包裏数最大化:每辆车的承运包裹量尽可能高,公式为:
3.最小化总成本:成本包括自有车辆的固定成本,变动成本,以及外部承运商的成本。公式为:
总成本
自有固定成本 + 自有变动成本 + 外部承运商总成本
约束条件:
3.优化目标
(1)自有车周转率最大化:目标是最大化自有车的周转率,保证每辆自有车的高效使用。
(2)车辆均包裹数最大化:目标是确保每辆车都尽可能满载,减少空车运行,优化资源使用。
(3)最小化总成本:通过优化车辆调度,最小化总成本,尤其是外部承运商的成本。
4.输出结果
最终的调度结果应包括:每条线路的发运时间;每条线路的承运车辆数,包括自有车和外部承运商车辆;串点方案,标明哪些线路可以合并发运,以及合并后的包裹量;对于每条运输需求,是否使用了外部承运商。
问题3分析:
当前存在一种标准容器,使用该容器可以进一步提升自有车辆利用率,将装车及卸车时长显著缩短至 10 分钟;但缺点是会降低车辆的装载量,其装载包裹量下降至 800 个。假设这种容器数量是无限的。请根据问题 1 输出的结果,重新确定运输需求,优化目标与问题 2 相同。在问题 2 所需输出结果的基础上,需另外输出各运输需求是否使用该标准容器。请将结果写入结果表 4 中,并在论文中给出线路编码为“场地3- 站点83- 0600”和“场地3- 站点83- 1400”的调度结果。
思路分析:假设存在标准容器,能减少装卸时间,但会降低单车载量。需要基于问题1的预测结果,重新评估运输需求,优化自有车辆的调度,并决定哪些需求会使用标准容器。优化算法、模拟退火、容器选择策略。
模型修改:当使用标准容器后,调整车辆的装载量和装卸时间。容器减少装卸时间,但会影响车辆的承载能力,因此需要重新计算运输需求,优化车辆调度。
标准容器的使用会影响装载量,降低为800个包裹/车。容器的使用会减少装车和卸车时长(从45分钟缩短至10分钟),但可能导致每辆车的装载量不足。根据问题2中的需求和时间安排,重新计算每条线路的运输需求。如果某些线路的包裹量不足1000个包裹,可以考虑使用标准容器来提高车辆利用率。
优化目标:除了车辆周转率和总成本外,还需要在目标函数中加入是否使用标准容器的判断,并调整车辆调度策略。
车辆利用率:结合标准容器使用,调整自有车辆和外部车辆的分配,使得车辆的装载量尽可能接近最大容量。
时效性:考虑容器影响后的装车时间,确保车辆能够按时发运。
问题4分析:
当问题1的货量预测结果出现偏差时,基于问题3,评估对你们的调度模型优化结果的影响。
思路分析:评估货量预测出现偏差时,对调度模型优化结果的影响。敏感性分析、蒙特卡洛模拟。
对货量预测误差进行敏感性分析,使用蒙特卡洛模拟或者其他敏感性分析方法,评估预测误差对运输调度结果的影响。基于偏差,可以调整调度策略,例如增加车辆调度的灵活性或使用更多外部承运商。
1、模拟货量预测偏差:对问题1中得出的货量预测结果进行扰动,模拟不同程度的偏差(例如±10%、±20%等),观察调度结果的变化。通过比较实际调度结果与预测偏差后的调度结果,评估偏差对车效、成本、车辆调度等的影响。
2、评估标准:
车效:观察自有车辆的周转率和车辆均包裹的变化。
成本:评估预测偏差对总成本的影响,特别是外部承运商成本的变化。
调度时效性:检查预测偏差是否导致发运延迟。
注:该问题只是一个简单的思路,目前正在代码的优化以及全篇论文的写作。具体完整代码与完整论文稍后全部完成会进行发布。
后续方法和思路持续更新中,会对方法进行优化操作ing。