表格RAG技术实战指南
表格RAG技术实战指南:从理论到应用

在数据驱动的时代,表格数据作为一种高效的信息组织形式,广泛应用于财务报表、科研数据和统计资料等领域。然而,如何让大型语言模型(LLMs)有效理解和处理这些结构化数据,是自然语言处理(NLP)领域的难题。Retrieval-Augmented Generation(RAG)技术的出现为这一挑战提供了解决方案,尤其在表格数据处理中展现出潜力。本文基于论文《Large Language Models(LLMs) on Tabular Data: Prediction, Generation, and Understanding – A Survey》(arXiv: 2402.17944),结合用户提供的总结、RAG竞赛冠军的解决方案(TableSerialization类)以及实战经验,深入探讨表格RAG的实现方法,重点分析表格序列化的技术细节,并提供一份实用的技术指南。
什么是表格RAG?
表格RAG(Retrieval-Augmented Generation)是一种结合检索和生成能力的框架,旨在增强LLMs对表格数据的理解和处理能力。其核心在于通过检索与用户查询相关的表格内容,并将这些内容输入LLM生成准确回答。与传统RAG聚焦于非结构化文本不同,表格RAG处理结构化表格数据,因此表格序列化是关键技术环节。
表格RAG的目标可以用公式表示:
Answer = LLM(Serialize(Table), Query)
其中,Serialize 是将表格数据(Table)转换为文本的过程,Query 是用户查询,LLM 是大型语言模型。序列化的质量直接影响检索和生成的准确性。例如,在回答“2021年公司股东权益是多少?”时,只需提供相关表格片段(如某一行或某几列),而非整个表格,从而减少“噪音”和上下文窗口压力。
表格序列化的核心技术
表格序列化的本质是将二维表格数据转换为一维文本格式,适配LLMs的输入需求。论文指出,序列化方法的选择对任务性能(如表格问答、值预测)有显著影响。以下结合用户总结、论文实验和RAG竞赛冠军方案,分析常见序列化格式及其优缺点:
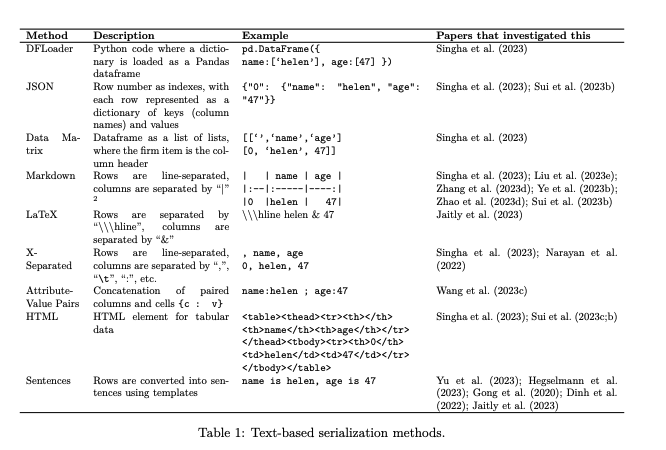
1. Markdown格式
- 描述:使用竖线(
|)分隔行列,例如:-
| 年份 | 股东权益 | |------|----------| | 2021 | 5000 |
-
- 优点:人类可读性强,适合调试。
- 缺点:冗余信息多,上下文窗口利用率低。
- 适用场景:展示小型表格,生产环境中效率较低。
2. LaTeX格式
- 描述:使用双反斜杠和竖线,例如:
-
\begin{tabular}{|c|c|} \hline 年份 & 股东权益 \\ \hline 2021 & 5000 \\ \hline \end{tabular}
-
- 优点:格式严谨,适合复杂表格。
- 缺点:可读性差,LLMs需额外适应。
- 适用场景:学术场景或高精度排版。
3. X-Separated格式(CSV)
- 描述:以逗号分隔,例如:
-
年份,股东权益 2021,5000
-
- 优点:紧凑,易于自动化解析。
- 缺点:难以表达合并单元格等复杂结构。
- 适用场景:简单表格,需搭配上下文。
4. Attribute-Value Pairs
- 描述:键值对格式,例如:
-
年份: 2021, 股东权益: 5000
-
- 优点:简单直接。
- 缺点:难以表达多维数据。
- 适用场景:单行查询或小型表格。
5. HTML格式
- 描述:使用
<table>、<tr>、<td>标签,例如:-
<table><tr><th>年份</th><th>股东权益</th></tr><tr><td>2021</td><td>5000</td></tr></table>
-
- 优点:结构丰富,适合复杂表格(合并单元格、子标题),LLMs因网络数据训练而擅长解析。
- 缺点:标记开销大,需优化。
- 适用场景:复杂表格问答,论文实验表明其在GPT-4上表现最佳。
6. 自然语言格式(Sentences)
- 描述:转换为句子,例如:
-
在2021年,公司的股东权益为5000。
-
- 优点:语义丰富,LLMs易理解。
- 缺点:冗长,易超上下文窗口。
- 适用场景:解释性任务或小型表格。
如何选择格式?
- 论文洞察:HTML和XML在表格问答(TableQA)和值预测任务中优于其他格式,尤其在GPT-3.5和GPT-4上,因LLMs预训练中接触大量HTML表格数据。
- 用户经验:HTML在GPT-4o-mini上几乎无损序列化大型表格,优于Markdown。JSON和DFLoader适合事实查找,但HTML更通用。
- RAG竞赛方案:
TableSerialization类强调上下文独立的信息块,HTML格式可承载其要求的丰富上下文(如单位、货币、脚注)。 - 推荐:优先选择HTML,平衡结构完整性和模型兼容性。简单任务可用CSV加上下文提示。
表格序列化的实战策略
1. 行列扫描法
行列扫描法是表格RAG的核心,通过分解表格为独立行或列文本块,降低上下文压力。论文、用户总结和RAG竞赛方案均强调其重要性。
-
按行扫描:
- 实现:每行序列化为单独字符串。例如,查询“2021年股东权益”只需:
-
<tr><td>2021</td><td>5000</td></tr>
-
- 适用场景:行间关联性弱,如时间序列。
- 代码:
-
def row_scan(table):return [f"<tr>{''.join(f'<td>{cell}</td>' for cell in row)}</tr>" for row in table]
-
- 实现:每行序列化为单独字符串。例如,查询“2021年股东权益”只需:
-
按列扫描:
- 实现:每列序列化为单独字符串。例如:
-
<td>年份</td><td>2021</td> <td>股东权益</td><td>5000</td>
-
- 适用场景:列间关联性弱,如属性列表。
- 代码:
-
def col_scan(table):return [f"<td>{header}</td><td>{value}</td>" for header, value in zip(table[0], table[1])]
-
- 实现:每列序列化为单独字符串。例如:
-
RAG竞赛优化:
TableSerialization类通过SerializedInformationBlock生成上下文独立块,核心实体(通常行标题)和相关表头(列标题)明确定义。例如:-
from pydantic import BaseModel, Fieldclass SerializedInformationBlock(BaseModel):subject_core_entity: strinformation_block: str -
每个块包含表名、单位、货币等,确保独立性,适合数据库存储和检索。
-
-
用户实现:参考GitHub - tables_serialization.py,展示了行列扫描的实用性。
-
优化建议:动态选择扫描方向(行/列),结合查询关键词提高效率。
2. 处理大型表格的召回问题
大型表格(数百行/列)受限于LLMs上下文窗口(如GPT-4的128k token)。论文、用户总结和RAG竞赛方案提出以下解决方案:
-
分块序列化:
- 将表格按固定大小(如10行)分割为子表,独立序列化。
- 实现:
-
def split_table(table, chunk_size=10):return [table[i:i+chunk_size] for i in range(0, len(table), chunk_size)]
-
- 优点:降低单次输入长度。
- 用户经验:结合BM25检索提升召回精度约15%。
-
HTML桥梁:
- 召回整表HTML格式,再后处理提取相关部分。例如:
- 召回:
-
<table>...</table>
-
- 提取目标行。
- 召回:
- 优点:保留完整结构,解决“爆炸问题”。
- RAG竞赛洞察:
TableBlocksCollection将表分解为独立块(information_blocks),每个块自包含上下文,适合HTML桥梁后处理。
- 召回整表HTML格式,再后处理提取相关部分。例如:
-
向量检索增强:
- 论文建议使用表格嵌入(Table Embedding),如TableBERT生成行/列向量,余弦相似度召回。
- 实现:
-
from sentence_transformers import SentenceTransformer model = SentenceTransformer('all-MiniLM-L6-v2') embeddings = model.encode([row_to_text(row) for row in table])
-
-
竞赛方案优化:
-
subject_core_entities_list和relevant_headers_list明确核心实体和表头关系,减少无关信息召回。 -
外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
-
代码示例:
-
class TableBlocksCollection(BaseModel):subject_core_entities_list: List[str]relevant_headers_list: List[str]information_blocks: List[SerializedInformationBlock]
-
-
3. 复杂表格处理
- 合并单元格:HTML支持
rowspan和colspan,优于CSV/Markdown。 - 嵌套表格:论文建议递归序列化子表。
- 上下文丰富:竞赛方案要求信息块包含表名、单位、货币、脚注等。例如:
-
block = SerializedInformationBlock(subject_core_entity="2021",information_block="In 2021, shareholder equity was 5000 USD, as reported in the Annual Financial Table. Total represents net equity after liabilities." )
-
4. 大表召回的“爆炸问题”
- 问题:行列扫描的
n x m方法在大表中导致块数激增。 - 竞赛解法:通过
TableSerialization生成少量高上下文块,存入数据库,结合HTML桥梁召回整表后精炼。 - 用户解法:HTML桥梁后处理,提取查询相关行/列。
表格RAG的完整流程
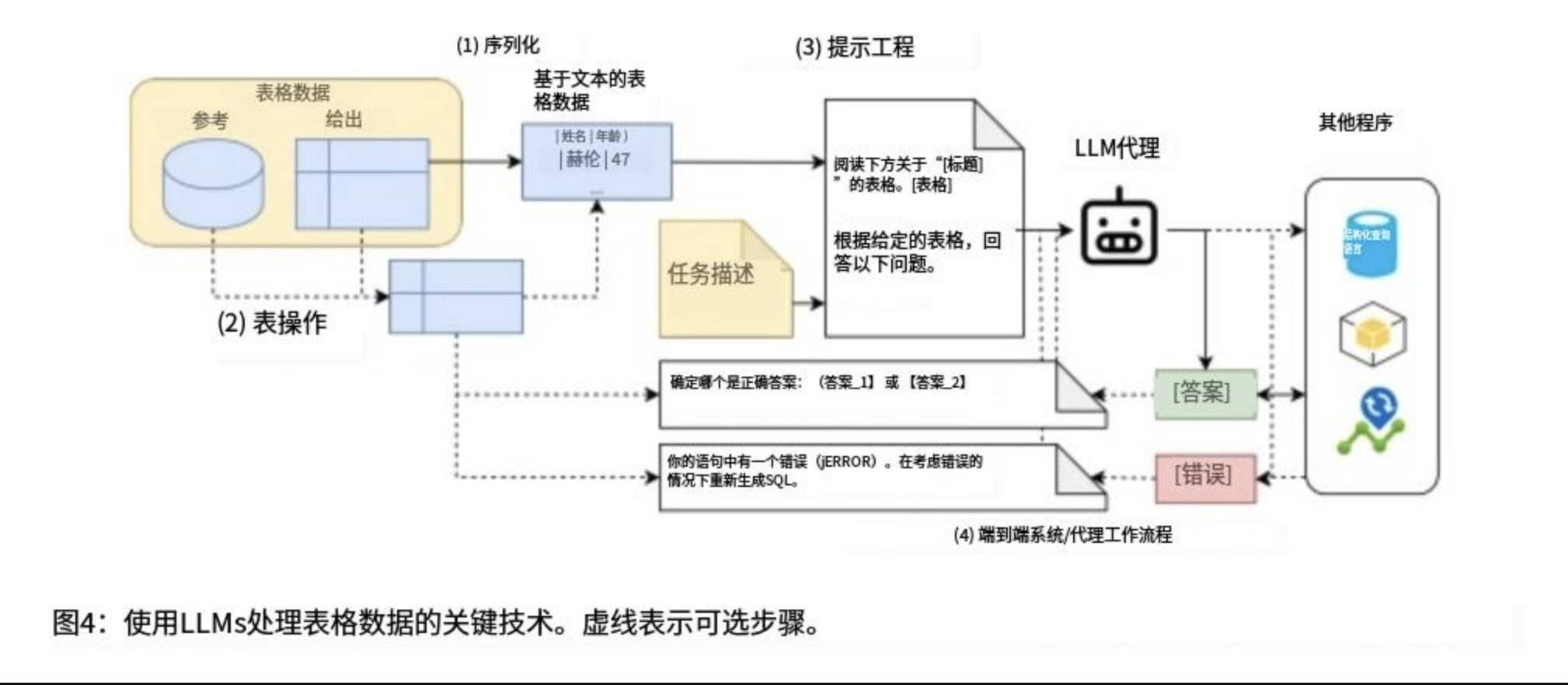
-
数据准备:
- 获取表格(CSV、Excel、数据库),清洗缺失值。
- 代码:
-
import pandas as pd df = pd.read_csv("data.csv") df.dropna(inplace=True)
-
-
序列化:
- 使用HTML格式,行列扫描生成文本块。
- 竞赛优化:生成
SerializedInformationBlock,确保上下文独立。 - 代码:
-
html_table = df.to_html(index=False) blocks = [SerializedInformationBlock(subject_core_entity=row[0], information_block=row_to_text(row)) for row in df.values]
-
-
检索:
- 使用BM25、向量检索或关键词匹配召回相关块。
- 代码:
-
from rank_bm25 import BM25Okapi tokenized_corpus = [block.information_block.split() for block in blocks] bm25 = BM25Okapi(tokenized_corpus) top_k = bm25.get_top_n(query.split(), blocks, n=5)
-
-
生成:
- 召回块输入LLM,生成答案。
- 提示:
-
用户查询:2021年股东权益是多少? 输入表格:<tr><td>年份</td><td>股东权益</td></tr><tr><td>2021</td><td>5000</td></tr>
-
-
后处理:
- 精炼大表召回结果。
- 代码:
-
def refine_results(blocks, query):return [block for block in blocks if query_keyword in block.information_block]
-
技术细节与优化建议
- 格式选择:HTML为首选,竞赛方案验证其承载丰富上下文的能力。CSV适合简单任务。
- 上下文管理:使用
TableSerialization生成独立块,存入向量数据库(如FAISS)。 - 模型选择:GPT-4o-mini性价比高,适合资源受限场景。
- 性能优化:
- 预计算嵌入,缓存序列化结果。
- 剔除无关列,减少20% token。
- 错误处理:规范化日期格式,填充缺失值标记“未知”。
未来研究方向
论文指出以下方向:
- 多模态融合:结合表格、文本、图像,如PDF报表。
- 动态表格:处理实时更新数据,如股票交易。
- 跨语言:支持多语言表格。
结语
表格RAG通过检索和生成结合,为LLMs处理表格数据开辟新路径。HTML格式、行列扫描法和TableSerialization的上下文独立块设计,使得大型表格也能高效处理。结合论文洞察、用户经验和竞赛方案,优化序列化策略、检索流程和向量嵌入,可显著提升性能。未来,多模态和动态处理将进一步扩展其应用。
参考文献
[2402.17944] Large Language Models(LLMs) on Tabular Data - arxiv.org
GitHub - tables_serialization.py