深度学习语音识别
目录
主流算法解析与联系
核心算法概览
算法演进与联系
当前主流应用
算法对比与选择建议
主流算法解析与联系
核心算法概览
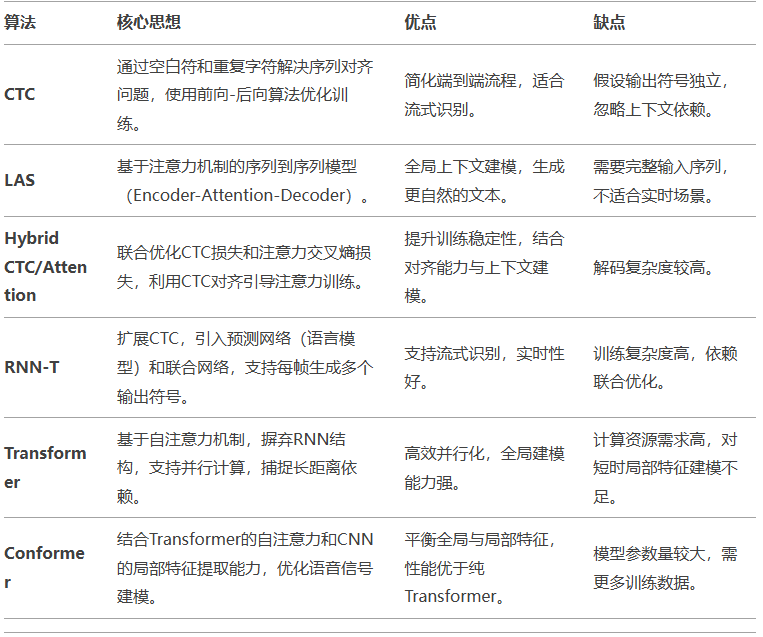
关键算法及其核心思想:
算法演进与联系
从CTC到RNN-T:流式识别的进化
CTC:早期端到端模型的代表,解决了输入输出序列对齐问题,但缺乏语言模型支持。
RNN-T:在CTC基础上引入预测网络(语言模型)和联合网络,允许每帧生成多个符号,支持实时流式识别(如语音助手)。
联系:RNN-T可视为CTC的扩展,通过联合建模声学与语言模型,提升流式场景下的准确率。
注意力机制的引入与优化
LAS:首次将注意力机制引入语音识别,通过Encoder-Attention-Decoder结构捕捉全局上下文,但需完整输入序列。
Hybrid CTC/Attention:结合CTC的对齐能力与注意力的上下文建模,通过多任务学习加速训练并提升鲁棒性。
Transformer:完全基于自注意力,替代RNN结构,提升并行效率,但需解决局部特征建模问题。
局部与全局特征的平衡:Conformer
Conformer:在Transformer中嵌入卷积模块(如Convolution Module),利用CNN提取局部声学特征,同时保留自注意力的全局建模能力。
优势:在LibriSpeech等数据集上达到SOTA(词错误率低于2%),成为工业界主流选择。
当前主流应用
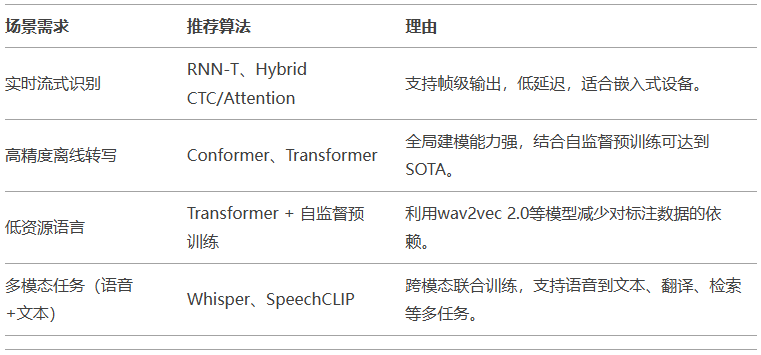
流式识别场景(如实时字幕、语音助手)
RNN-T:因其帧级预测和低延迟特性,被Google Duplex等产品采用。
Hybrid CTC/Attention:结合流式编码器(如单向LSTM)与注意力解码,平衡实时性与准确性。
非流式高精度场景(如录音转写)
Conformer:凭借全局-局部特征融合能力,成为主流编码器架构(如NVIDIA NeMo、ESPnet)。
Transformer-based模型:结合自监督预训练(如wav2vec 2.0),在低资源场景表现优异。
多模态融合
Whisper(OpenAI):基于Transformer,支持多语言语音识别与翻译,利用大规模弱监督数据提升泛化性。
算法对比与选择建议
小结
技术演进主线:从CTC的序列对齐,到注意力机制的上下文建模,再到Conformer的全局-局部特征融合,语音识别逐步向高效、高精度、低延迟方向发展。
未来趋势
轻量化与实时性:模型压缩(如知识蒸馏)与流式架构优化。
多模态统一:融合语音、文本、视觉的通用模型(如Meta的CM3leon)。
自监督学习:减少对标注数据的依赖,提升低资源场景表现。