【人工智能】再谈探索AI幻觉及其解决方案(进一步整理)
摘要
我是田辛老师。今天我们将聚焦大模型应用中一个关键痛点——AI幻觉现象,并深入解析其解决方案RAG技术的实现原理与工程实践。通过本文,你将掌握:
- AI幻觉的典型表现与行业影响
- RAG技术的三阶段实现流程
- Embedding模型的核心作用原理
- 三类模型的协同工作机制
- 实战代码示例与模型选型建议
一、AI幻觉:大模型的"认知失调"综合症
1.1 现象观察
自2024年大模型广泛应用以来,我们发现一个有趣现象:当处理超出训练数据范围的问题时,模型会产生事实性错误或逻辑混乱的回答。这种现象被称作"AI幻觉",如同人类在陌生领域的认知失调。
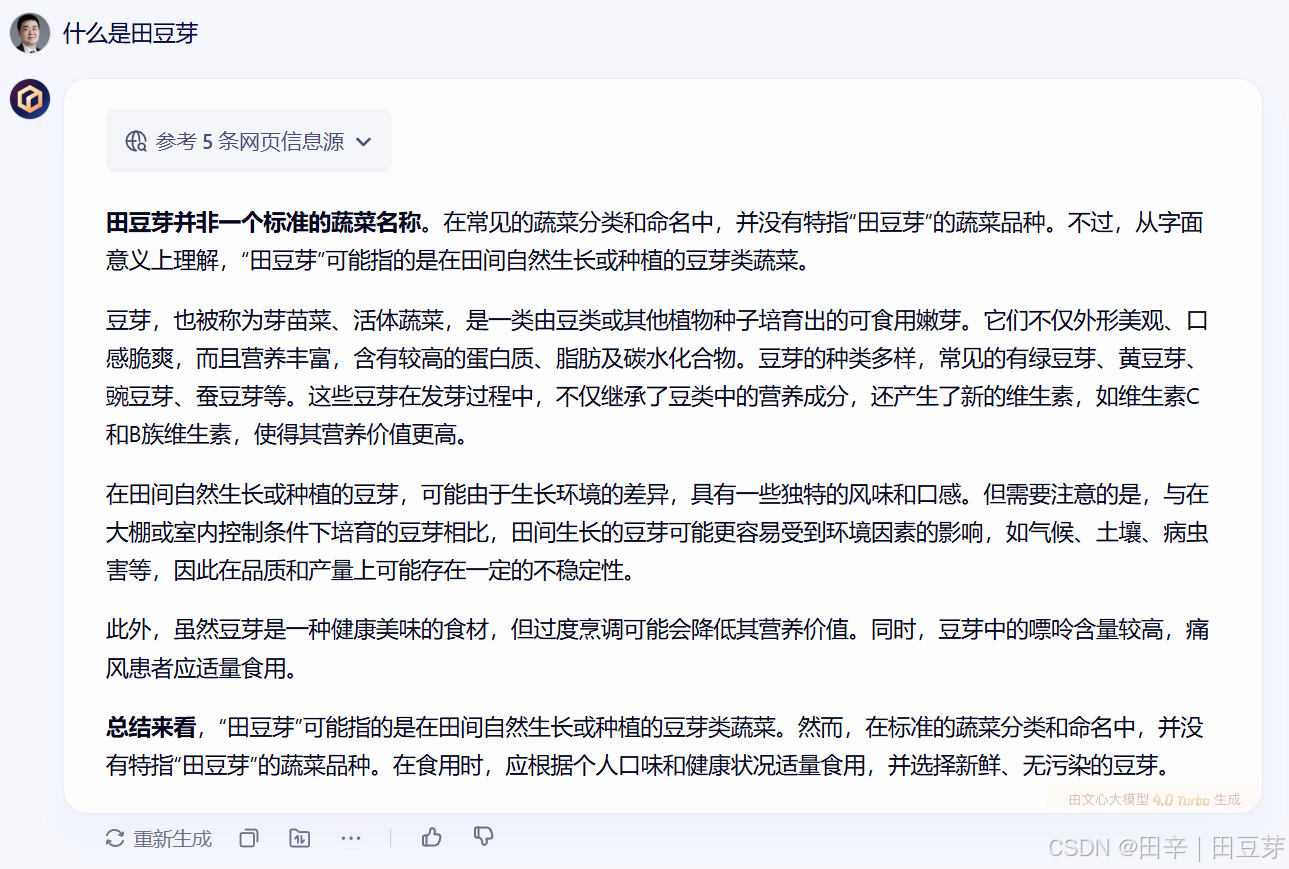
(示例:某模型对"田豆芽"品牌的错误解读)
1.2 风险等级
| 风险领域 | 潜在后果 | 紧急程度 |
|---|---|---|
| 医疗诊断 | 误诊风险 | ⭐⭐⭐⭐⭐ |
| 法律咨询 | 条款误读 | ⭐⭐⭐⭐ |
| 金融分析 | 投资误导 | ⭐⭐⭐⭐ |
二、技术解决方案全景图
2.1 双轨制解决方案
# 解决方案选择决策树
def select_solution(problem_type):if problem_type == "领域专业化":return "模型微调"elif problem_type == "实时知识更新": return "RAG技术"else:return "混合策略"
2.1.1 模型微调
- 类比:考前专题特训
- 优势:领域精度优化
- 局限:静态知识固化
2.1.2 RAG技术
- 类比:开卷考试机制
- 优势:动态知识融合
- 特点:实时性+可解释性
三、RAG技术实现全解析
3.1 三阶段处理流程
# RAG核心处理流程
def rag_pipeline(query, knowledge_base):# 阶段一:检索retrieved_docs = retrieve(query, knowledge_base)# 阶段二:增强augmented_context = augment(query, retrieved_docs)# 阶段三:生成return generate(augmented_context)
3.2 关键技术组件
四、Embedding模型的核心作用
4.1 语义映射原理
# 文本向量化示例
from sentence_transformers import SentenceTransformermodel = SentenceTransformer('BAAI/bge-m3')
texts = ["田辛老师", "AI工程化"]
embeddings = model.encode(texts) # 输出1024维向量# 计算相似度
cos_sim = util.cos_sim(embeddings[0], embeddings[1])
print(f"语义相似度:{cos_sim.item():.2f}")
4.2 检索优化策略
# 多线程向量化加速
import concurrent.futuresdef batch_embedding(texts, model):with concurrent.futures.ThreadPoolExecutor() as executor:return list(executor.map(model.encode, texts))
五、模型协同工作机制
5.1 三大模型分工
| 模型类型 | 功能定位 | 性能要求 |
|---|---|---|
| Chat模型 | 自然语言交互 | 高生成质量 |
| 推理模型 | 逻辑决策 | 高计算精度 |
| Embedding模型 | 语义理解 | 高处理速度 |
5.2 协同流程示例
# 完整RAG系统实现
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.retrievers import ContextualCompressionRetriever# 初始化组件
embedder = HuggingFaceEmbeddings(model_name="BAAI/bge-m3")
reranker = CohereRerank(api_key="your_key")# 构建检索链
retriever = VectorStoreRetriever(vectorstore=knowledge_base)
compression_retriever = ContextualCompressionRetriever(base_compressor=reranker,base_retriever=retriever
)# 执行查询
results = compression_retriever.get_relevant_documents("如何预防AI幻觉?")
六、总结与展望
6.1 技术选型建议
| 场景特征 | 推荐方案 | 延迟预算 |
|---|---|---|
| 实时性要求高 | Embedding+BM25 | <100ms |
| 精准度要求高 | Embedding+Rerank | 200-500ms |
| 领域知识复杂 | 微调+RAG混合 | >500ms |
6.2 未来演进方向
- 多模态RAG:融合文本/图像/视频检索
- 动态Embedding:自适应领域特征
- 认知增强架构:结合知识图谱推理
我是田辛老师,希望本文能帮助大家在AI工程化的道路上少走弯路。欢迎在评论区交流实战中遇到的挑战,我们共同探讨解决方案!