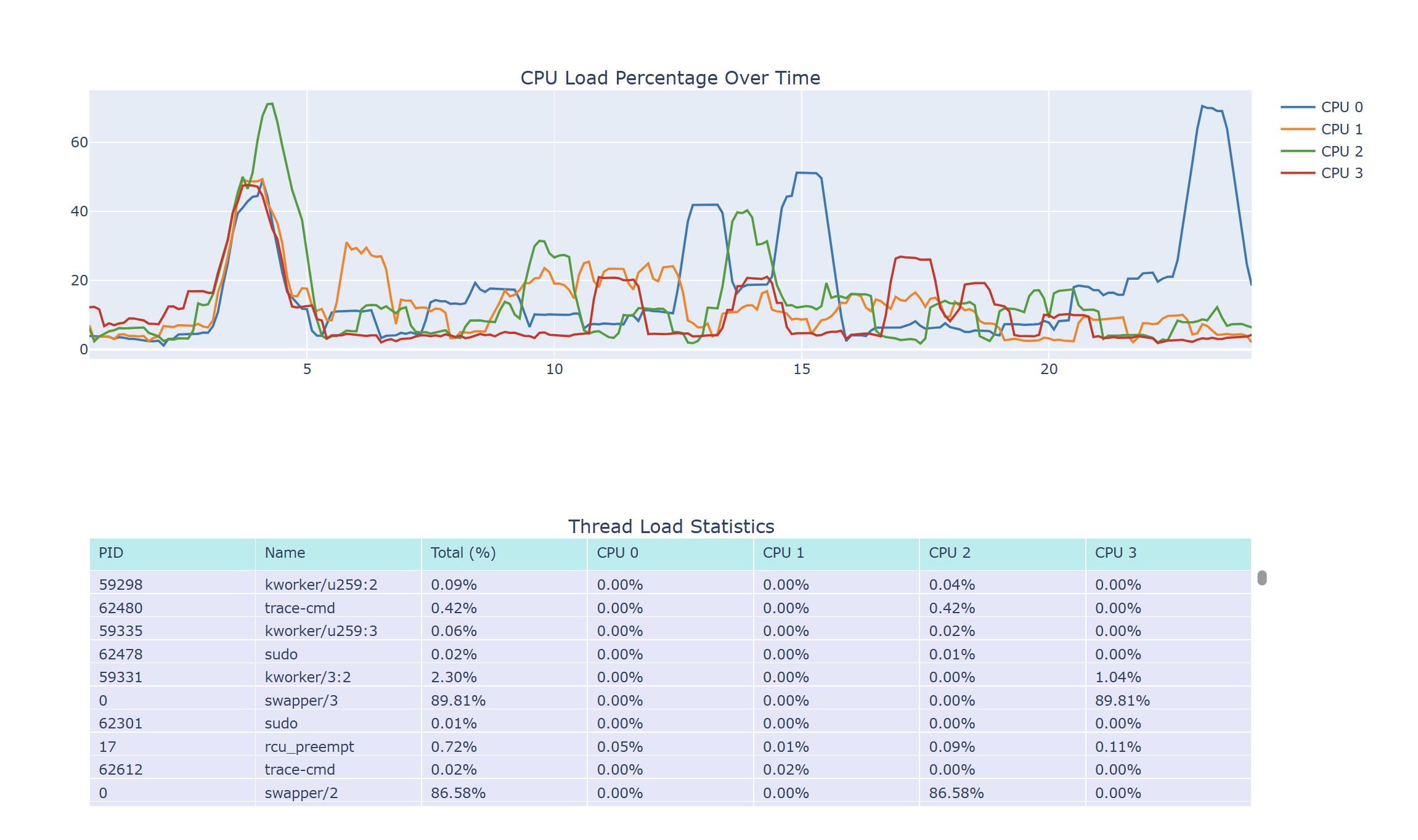
CPU Loading and Task Loading Visualization Tool
用LLM AI完成tool开发。
利用ftrace的调度trace event (sched_switch 和 sched_stat_runtime) 进行cpu loading和task loading的统计分析,以及可视化展示。
项目名称
Ftrace 日志分析器
项目概述
此项目是一个用于分析 Ftrace 日志的 Python 脚本,它能够解析 Ftrace 日志文件,统计每个线程和 CPU 的使用情况,并生成包含 CPU 负载曲线和线程使用情况表格的 HTML 报告。
功能特性
- 日志解析:解析 Ftrace 日志文件,提取关键信息,如线程名、进程 ID、CPU 编号、时间戳和事件类型。
- 统计信息:统计每个线程在各个 CPU 上的运行时间,以及每个 CPU 的总活跃时间和空闲时间。
- 可视化报告:生成 HTML 报告,包含 CPU 负载曲线和线程使用情况表格,方便用户直观地查看系统的 CPU 使用情况。
安装依赖
运行此脚本前,需要安装以下 Python 库:
numpybokeh可以使用以下命令进行安装:pip install numpy bokeh
使用的 Ftrace 事件
本工具主要使用以下两个 Ftrace 事件进行分析:
- sched_switch:该事件在进程切换时触发,记录了从一个进程切换到另一个进程的相关信息。通过解析这个事件,可以追踪每个线程在不同 CPU 上的运行时间,以及 CPU 的空闲时间。
- sched_stat_runtime:该事件用于统计进程的运行时间。通过这个事件,可以获取每个线程的运行时长,进一步完善线程的统计信息。
使用 trace-cmd 抓取 Ftrace 日志
trace-cmd是一个用于控制 Ftrace 功能的命令行工具,以下是使用trace-cmd抓取所需 Ftrace 日志的步骤:1. 安装 trace-cmd
如果你还没有安装
trace-cmd,可以使用包管理器进行安装。例如,在 Ubuntu 上可以使用以下命令:sudo apt-get install trace-cmd2. 配置跟踪事件
此脚本需要跟踪
sched_switch和sched_stat_runtime事件,你可以使用以下命令启用这些事件:sudo trace-cmd record -e sched_switch -e sched_stat_runtime3. 开始记录日志
运行上述命令后,
trace-cmd会开始记录指定事件的日志。你可以让系统运行一段时间,以收集足够的日志数据。4. 停止记录日志
当你认为已经收集到足够的日志数据时,可以按下
Ctrl + C停止记录。trace-cmd会将日志保存到一个文件中,默认文件名是trace.dat。5. 转换日志文件格式
由于脚本需要的是文本格式的日志文件,你可以使用以下命令将
trace.dat转换为文本格式:sudo trace-cmd report -i trace.dat > ftrace.log使用方法
- 确保已经安装了所需的依赖库。
- 使用
trace-cmd抓取 Ftrace 日志,并将其保存为文本文件(如ftrace.log)。- 运行脚本,命令如下:python ftrace_analyzer.py <ftrace.log>其中
<ftrace.log>是你要分析的 Ftrace 日志文件的路径。- 脚本运行完成后,会在当前目录下生成一个名为
report.html的 HTML 报告文件,打开该文件即可查看分析结果。代码结构
- 类型定义:定义了一些数据类型,如
Timestamp、CPUID和PID,用于明确代码中变量的含义。- 日志解析模块:
FtraceParser类负责解析 Ftrace 日志文件的每一行,将其转换为结构化的数据。- 事件处理模块:
EventProcessor类处理sched_switch和sched_stat_runtime两种事件,统计线程和 CPU 的使用情况。- 报告生成模块:
ReportGenerator类生成 HTML 报告,包含 CPU 负载曲线和线程使用情况表格。- 主流程:
analyze_ftrace函数是主分析流程,读取日志文件,调用解析和处理函数,最后生成报告。代码优化
在
ReportGenerator.generate_html_report方法中,使用了滑动窗口算法来计算 CPU 负载曲线,使曲线更加平滑,粒度更细致。注意事项
- 确保输入的 Ftrace 日志文件格式正确,否则可能会导致解析失败。
- 报告文件
report.html会覆盖当前目录下已有的同名文件,请谨慎操作。- 使用
trace-cmd抓取日志需要 root 权限,请确保你有足够的权限执行相关命令。贡献与反馈
如果你发现任何问题或有改进建议,欢迎提交 issue 或 pull request。
1.Bokeh
import re
import datetime
import numpy as np
import logging
from collections import defaultdict
from typing import Dict, Tuple, Optional, Listfrom bokeh.plotting import figure, output_file, save
from bokeh.models import ColumnDataSource, DataTable, TableColumn, HoverTool
from bokeh.layouts import column# 配置日志
logging.basicConfig(level=logging.INFO,format='%(asctime)s - %(levelname)s - %(message)s',handlers=[logging.StreamHandler()]
)
logger = logging.getLogger(__name__)# ----------------------
# 类型定义
# ----------------------
Timestamp = float # 时间戳(秒)
CPUID = int # CPU标识符
PID = int # 进程IDclass ThreadStats:"""线程统计数据结构"""def __init__(self):self.name: str = "" # 线程名self.cpu_time: Dict[CPUID, float] = defaultdict(float) # 各CPU累计时间self.total_time: float = 0.0 # 总运行时间class CPUStats:"""CPU统计数据结构"""def __init__(self):self.total_active: float = 0.0 # 总活跃时间(非swapper线程)self.total_idle: float = 0.0 # 总空闲时间(swapper线程)self.time_periods: List[Tuple[float, float, bool]] = [] # 时间段记录(开始时间,结束时间,是否活跃)class GlobalState:"""全局状态容器"""def __init__(self):self.threads: Dict[Tuple[str, PID], ThreadStats] = defaultdict(ThreadStats) # (线程名, PID) -> 线程统计self.cpus: Dict[CPUID, CPUStats] = defaultdict(CPUStats) # CPU -> 统计信息self.current_pid: Dict[CPUID, Tuple[Tuple[str, PID], Timestamp]] = {} # CPU当前运行的(线程名, PID)及开始时间self.pid_to_name: Dict[PID, str] = {} # PID到线程名的映射# ----------------------
# 日志解析模块
# ----------------------
class FtraceParser:"""Ftrace日志解析器"""LOG_REGEX = re.compile(r'^(?P<comm>[^-]+)-(?P<pid>\d+)\s+\[(?P<cpu>\d+)\]\s+'r'(?P<timestamp>\d+\.\d+):\s+'r'(?P<event>\w+):\s+(?P<details>.*)$')@classmethoddef parse_line(cls, line: str) -> Optional[dict]:"""解析单行日志,返回结构化数据"""start_time = datetime.datetime.now()match = cls.LOG_REGEX.match(line.strip())if not match:logger.debug(f"无法解析的行: {line.strip()}")return Noneparsed_data = {'comm': match.group('comm'),'pid': int(match.group('pid')),'cpu': int(match.group('cpu')),'timestamp': float(match.group('timestamp')),'event': match.group('event'),'details': match.group('details')}duration = (datetime.datetime.now() - start_time).total_seconds() * 1000logger.debug(f"解析成功: {parsed_data}, 耗时: {duration:.2f}ms")return parsed_data# ----------------------
# 事件处理模块
# ----------------------
class EventProcessor:"""事件处理器"""SWAPPER_NAMES = ('swapper', 'swapper/') # 空闲线程名称特征@classmethoddef _is_swapper(cls, comm: str, pid: int) -> bool:"""判断是否为表示空闲的swapper线程"""return pid == 0 or comm.startswith(cls.SWAPPER_NAMES)@classmethoddef handle_sched_switch(cls, state: GlobalState, entry: dict):"""处理进程切换事件"""start_time = datetime.datetime.now()details = entry['details']match = re.match(r'(?P<prev_comm>[^:]+(?::[^:]+)*):(?P<prev_pid>\d+).*?==>\s+'r'(?P<next_comm>[^:]+(?::[^:]+)*):(?P<next_pid>\d+)',details)if not match:logger.warning(f"无法解析的sched_switch事件: {details}")returnlogger.debug(f"开始处理sched_switch事件: CPU={entry['cpu']}, 从 {match.group('prev_comm')}:{match.group('prev_pid')} 切换到 {match.group('next_comm')}:{match.group('next_pid')}")cpu = entry['cpu']ts = entry['timestamp']# 提取 prev 线程信息prev_comm = match.group('prev_comm')prev_pid = int(match.group('prev_pid'))prev_key = (prev_comm, prev_pid)# 提取 next 线程信息next_comm = match.group('next_comm')next_pid = int(match.group('next_pid'))next_key = (next_comm, next_pid)# 结束前一个线程的时间统计if cpu in state.current_pid:(running_comm, running_pid), start_ts = state.current_pid[cpu]running_key = (running_comm, running_pid)duration = ts - start_tsprev_running_comm = running_comm# 记录时间段is_active = not cls._is_swapper(prev_running_comm, running_pid)state.cpus[cpu].time_periods.append((start_ts, ts, is_active))# 根据线程类型统计时间if cls._is_swapper(prev_running_comm, running_pid):state.cpus[cpu].total_idle += durationstate.threads[running_key].cpu_time[cpu] += durationstate.threads[running_key].total_time += durationelse:state.cpus[cpu].total_active += durationstate.threads[running_key].cpu_time[cpu] += durationstate.threads[running_key].total_time += duration# 记录新线程信息state.current_pid[cpu] = (next_key, ts)state.pid_to_name[prev_pid] = prev_commstate.pid_to_name[next_pid] = next_commstate.threads[prev_key].name = prev_commstate.threads[next_key].name = next_comm@classmethoddef handle_sched_stat_runtime(cls, state: GlobalState, entry: dict):"""处理运行时统计事件"""start_time = datetime.datetime.now()details = entry['details']comm = re.search(r'comm=([^\s]+)', details).group(1)pid = int(re.search(r'pid=(\d+)', details).group(1))runtime_ns = int(re.search(r'runtime=(\d+)', details).group(1))cpu = entry['cpu']runtime = runtime_ns / 1e9 # 转换为秒key = (comm, pid)logger.debug(f"开始处理sched_stat_runtime: CPU={cpu}, {comm}:{pid}, 运行时间={runtime:.6f}s")if cls._is_swapper(comm, pid):state.cpus[cpu].total_idle += runtimestate.threads[key].cpu_time[cpu] += runtimestate.threads[key].total_time += runtimestate.threads[key].name = commstate.pid_to_name[pid] = commelse:state.cpus[cpu].total_active += runtimestate.threads[key].total_time += runtimestate.threads[key].name = commstate.pid_to_name[pid] = comm# ----------------------
# 报告生成模块
# ----------------------
class ReportGenerator:"""统计报告生成器"""@staticmethoddef generate_html_report(state: GlobalState, start_ts: float, end_ts: float, output_filename: str = "report.html"):"""生成HTML可视化报告"""report_start = datetime.datetime.now()logger.info(f"start generate report, duration:{start_ts:.2f}s-{end_ts:.2f}s, output file: {output_filename}")# 生成CPU负载曲线数据window_size = 1.0 # 滑动窗口大小(秒)interval = 0.1 # 采样间隔(秒)time_points = np.arange(start_ts, end_ts, interval)cpu_load_data = defaultdict(list)logger.info(f"start analysis cpu loading, cpu number: {len(state.cpus)}")for cpu in state.cpus:periods = state.cpus[cpu].time_periodsfor t in time_points:window_start = t - window_size / 2window_end = t + window_size / 2if window_start < start_ts or window_end > end_ts:continuetotal_active_time = 0.0for (p_start, p_end, is_active) in periods:if p_end <= window_start or p_start >= window_end:continueoverlap_start = max(p_start, window_start)overlap_end = min(p_end, window_end)if is_active:total_active_time += overlap_end - overlap_startload_pct = (total_active_time / window_size) * 100 if window_size > 0 else 0cpu_load_data[cpu].append((t - start_ts, load_pct))logger.info(f"create chart...")# 创建图表output_file(output_filename)p = figure(title="CPU Load Percentage Over Time",x_axis_label='Time (s from start)',y_axis_label='Load (%)',width=1200,height=400,tools="pan,wheel_zoom,box_zoom,reset")colors = ['#1f77b4', '#ff7f0e', '#2ca02c', '#d62728','#9467bd', '#8c564b', '#e377c2', '#7f7f7f']# 为每个CPU添加折线for idx, cpu in enumerate(sorted(cpu_load_data.keys())):data = cpu_load_data[cpu]if not data:continuetimes, loads = zip(*data)source = ColumnDataSource(data={'time': times,'load': loads,'cpu': [f'CPU {cpu}'] * len(times)})p.line('time', 'load',source=source,legend_label=f'CPU {cpu}',line_width=1.5,color=colors[idx % len(colors)])# 配置悬停工具hover = HoverTool(tooltips=[('CPU', '@cpu'),('Time', '@time{0.2f} s'),('Load', '@load{0.2f}%'),])p.add_tools(hover)p.legend.location = "top_left"p.legend.click_policy = "hide"# 生成线程表格数据cpus = sorted(state.cpus.keys())thread_data = []for (name, pid), stats in state.threads.items():total_time = stats.total_timetotal_percent = total_time / (end_ts - start_ts) * 100 if (end_ts - start_ts) > 0 else 0row = {'PID': pid, 'Name': name, 'Total (%)': f"{total_percent:.2f}%"}for cpu in cpus:cpu_time = stats.cpu_time.get(cpu, 0.0)cpu_percent = cpu_time / (end_ts - start_ts) * 100 if (end_ts - start_ts) > 0 else 0row[f'CPU {cpu}'] = f"{cpu_percent:.2f}%"thread_data.append(row)# 将 thread_data 转换为字典形式column_data = defaultdict(list)for row in thread_data:for key, value in row.items():column_data[key].append(value)# 创建数据表格columns = [TableColumn(field="PID", title="PID", width=80),TableColumn(field="Name", title="Thread Name", width=200),TableColumn(field="Total (%)", title="Total Load (%)", width=100),]for cpu in cpus:columns.append(TableColumn(field=f'CPU {cpu}', title=f'CPU {cpu} (%)', width=100))source = ColumnDataSource(column_data)data_table = DataTable(source=source,columns=columns,width=1200,height=400,editable=False,index_position=None,autosize_mode="none")# 组合布局并保存layout = column(p, data_table)save(layout)report_duration = (datetime.datetime.now() - report_start).total_seconds()logger.info(f"end report, {output_filename}, consume duration: {report_duration:.2f}s")# ----------------------
# 主流程
# ----------------------
def analyze_ftrace(log_path: str):"""主分析流程"""state = GlobalState()first_ts = Nonelast_ts = 0.0parse_start = datetime.datetime.now()logger.info("start parse ftrace log...")with open(log_path) as f:line_count = sum(1 for _ in f)logger.info(f"ftrace log file contains {line_count} lines")f.seek(0)for line in f:entry = FtraceParser.parse_line(line)if not entry:continuets = entry['timestamp']if first_ts is None:first_ts = tslast_ts = tsif entry['event'] == 'sched_switch':EventProcessor.handle_sched_switch(state, entry)elif entry['event'] == 'sched_stat_runtime':EventProcessor.handle_sched_stat_runtime(state, entry)# 处理最后未结束的时间段for cpu in state.current_pid:(running_comm, running_pid), start_ts = state.current_pid[cpu]running_key = (running_comm, running_pid)comm = running_commis_active = not EventProcessor._is_swapper(comm, running_pid)state.cpus[cpu].time_periods.append((start_ts, last_ts, is_active))duration = last_ts - start_tsif is_active:state.cpus[cpu].total_active += durationstate.threads[running_key].cpu_time[cpu] += durationstate.threads[running_key].total_time += durationelse:state.cpus[cpu].total_idle += durationstate.threads[running_key].cpu_time[cpu] += durationstate.threads[running_key].total_time += durationduration = (datetime.datetime.now() - parse_start).total_seconds()logger.info(f"end parse ftrace log, duration:{duration:.2f}s")# 生成报告if first_ts is not None:ReportGenerator.generate_html_report(state, first_ts, last_ts)if __name__ == "__main__":import sysif len(sys.argv) != 2:print("Usage: python ftrace_analyzer.py <ftrace.log>")sys.exit(1)analyze_ftrace(sys.argv[1])
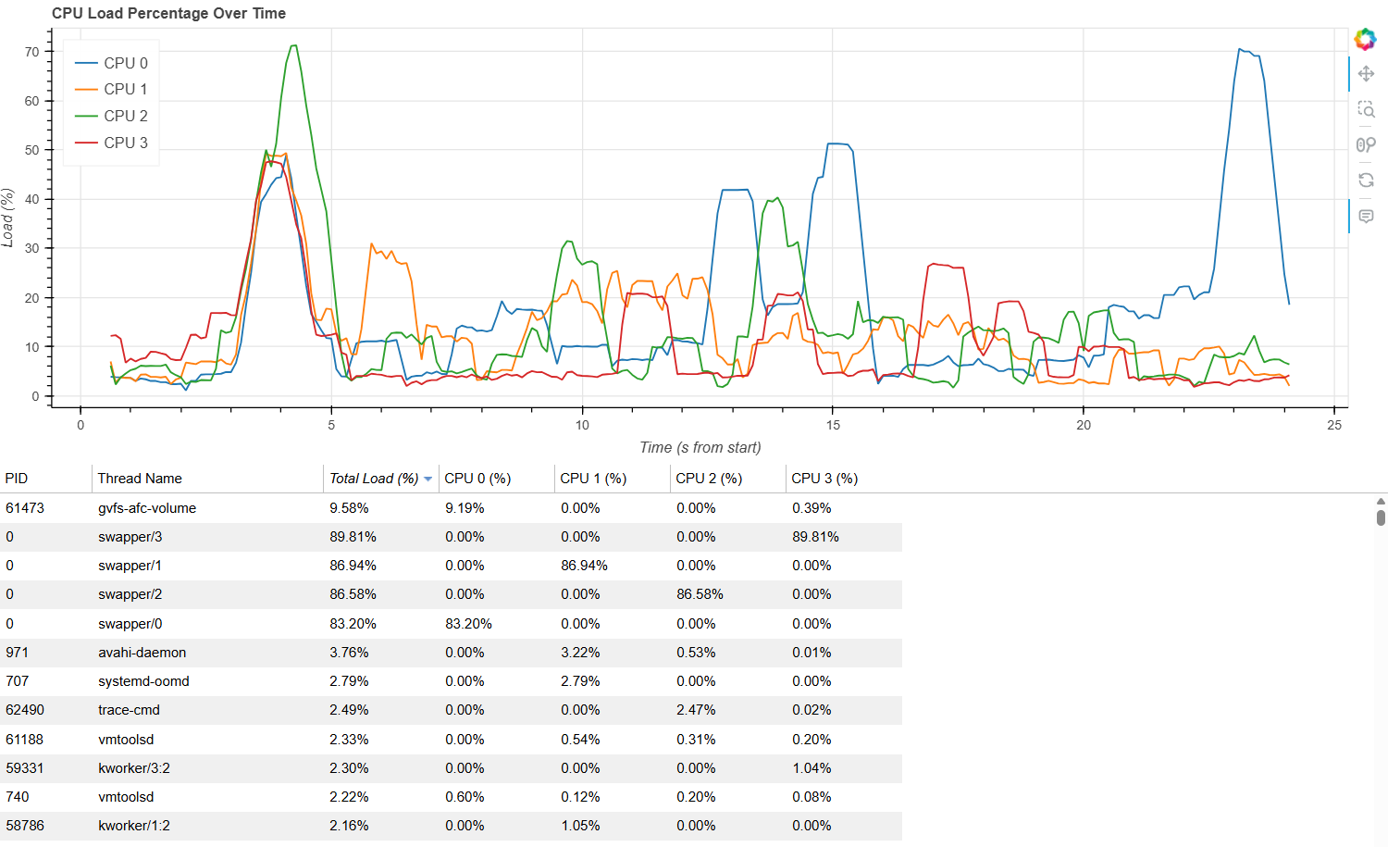
2.Plotly
import re
import datetime
import numpy as np
import logging
from collections import defaultdict
from typing import Dict, Tuple, Optional, List
import plotly.graph_objects as go
import pandas as pd# 配置日志
logging.basicConfig(level=logging.INFO,format='%(asctime)s - %(levelname)s - %(message)s',handlers=[logging.StreamHandler()]
)
logger = logging.getLogger(__name__)# ----------------------
# 类型定义
# ----------------------
Timestamp = float # 时间戳(秒)
CPUID = int # CPU标识符
PID = int # 进程IDclass ThreadStats:"""线程统计数据结构"""def __init__(self):self.name: str = "" # 线程名self.cpu_time: Dict[CPUID, float] = defaultdict(float) # 各CPU累计时间self.total_time: float = 0.0 # 总运行时间class CPUStats:"""CPU统计数据结构"""def __init__(self):self.total_active: float = 0.0 # 总活跃时间(非swapper线程)self.total_idle: float = 0.0 # 总空闲时间(swapper线程)self.time_periods: List[Tuple[float, float, bool]] = [] # 时间段记录(开始时间,结束时间,是否活跃)class GlobalState:"""全局状态容器"""def __init__(self):self.threads: Dict[Tuple[str, PID], ThreadStats] = defaultdict(ThreadStats) # (线程名, PID) -> 线程统计self.cpus: Dict[CPUID, CPUStats] = defaultdict(CPUStats) # CPU -> 统计信息self.current_pid: Dict[CPUID, Tuple[Tuple[str, PID], Timestamp]] = {} # CPU当前运行的(线程名, PID)及开始时间self.pid_to_name: Dict[PID, str] = {} # PID到线程名的映射# ----------------------
# 日志解析模块
# ----------------------
class FtraceParser:"""Ftrace日志解析器"""LOG_REGEX = re.compile(r'^(?P<comm>[^-]+)-(?P<pid>\d+)\s+\[(?P<cpu>\d+)\]\s+'r'(?P<timestamp>\d+\.\d+):\s+'r'(?P<event>\w+):\s+(?P<details>.*)$')@classmethoddef parse_line(cls, line: str) -> Optional[dict]:"""解析单行日志,返回结构化数据"""start_time = datetime.datetime.now()match = cls.LOG_REGEX.match(line.strip())if not match:logger.debug(f"无法解析的行: {line.strip()}")return Noneparsed_data = {'comm': match.group('comm'),'pid': int(match.group('pid')),'cpu': int(match.group('cpu')),'timestamp': float(match.group('timestamp')),'event': match.group('event'),'details': match.group('details')}duration = (datetime.datetime.now() - start_time).total_seconds() * 1000logger.debug(f"解析成功: {parsed_data}, 耗时: {duration:.2f}ms")return parsed_data# ----------------------
# 事件处理模块
# ----------------------
class EventProcessor:"""事件处理器"""SWAPPER_NAMES = ('swapper', 'swapper/') # 空闲线程名称特征@classmethoddef _is_swapper(cls, comm: str, pid: int) -> bool:"""判断是否为表示空闲的swapper线程"""return pid == 0 or comm.startswith(cls.SWAPPER_NAMES)@classmethoddef handle_sched_switch(cls, state: GlobalState, entry: dict):"""处理进程切换事件"""start_time = datetime.datetime.now()details = entry['details']match = re.match(r'(?P<prev_comm>[^:]+(?::[^:]+)*):(?P<prev_pid>\d+).*?==>\s+'r'(?P<next_comm>[^:]+(?::[^:]+)*):(?P<next_pid>\d+)',details)if not match:logger.warning(f"无法解析的sched_switch事件: {details}")returnlogger.debug(f"开始处理sched_switch事件: CPU={entry['cpu']}, 从 {match.group('prev_comm')}:{match.group('prev_pid')} 切换到 {match.group('next_comm')}:{match.group('next_pid')}")cpu = entry['cpu']ts = entry['timestamp']# 提取 prev 线程信息prev_comm = match.group('prev_comm')prev_pid = int(match.group('prev_pid'))prev_key = (prev_comm, prev_pid)# 提取 next 线程信息next_comm = match.group('next_comm')next_pid = int(match.group('next_pid'))next_key = (next_comm, next_pid)# 结束前一个线程的时间统计if cpu in state.current_pid:(running_comm, running_pid), start_ts = state.current_pid[cpu]running_key = (running_comm, running_pid)duration = ts - start_tsprev_running_comm = running_comm# 记录时间段is_active = not cls._is_swapper(prev_running_comm, running_pid)state.cpus[cpu].time_periods.append((start_ts, ts, is_active))# 根据线程类型统计时间if cls._is_swapper(prev_running_comm, running_pid):state.cpus[cpu].total_idle += durationstate.threads[running_key].cpu_time[cpu] += durationstate.threads[running_key].total_time += durationelse:state.cpus[cpu].total_active += durationstate.threads[running_key].cpu_time[cpu] += durationstate.threads[running_key].total_time += duration# 记录新线程信息state.current_pid[cpu] = (next_key, ts)state.pid_to_name[prev_pid] = prev_commstate.pid_to_name[next_pid] = next_commstate.threads[prev_key].name = prev_commstate.threads[next_key].name = next_comm@classmethoddef handle_sched_stat_runtime(cls, state: GlobalState, entry: dict):"""处理运行时统计事件"""start_time = datetime.datetime.now()details = entry['details']comm = re.search(r'comm=([^\s]+)', details).group(1)pid = int(re.search(r'pid=(\d+)', details).group(1))runtime_ns = int(re.search(r'runtime=(\d+)', details).group(1))cpu = entry['cpu']runtime = runtime_ns / 1e9 # 转换为秒key = (comm, pid)logger.debug(f"开始处理sched_stat_runtime: CPU={cpu}, {comm}:{pid}, 运行时间={runtime:.6f}s")if cls._is_swapper(comm, pid):state.cpus[cpu].total_idle += runtimestate.threads[key].cpu_time[cpu] += runtimestate.threads[key].total_time += runtimestate.threads[key].name = commstate.pid_to_name[pid] = commelse:state.cpus[cpu].total_active += runtimestate.threads[key].total_time += runtimestate.threads[key].name = commstate.pid_to_name[pid] = comm# ----------------------
# 报告生成模块
# ----------------------
class ReportGenerator:"""统计报告生成器"""@staticmethoddef generate_html_report(state: GlobalState, start_ts: float, end_ts: float, output_filename: str = "report.html"):"""生成HTML可视化报告"""report_start = datetime.datetime.now()logger.info(f"start generate report, duration:{start_ts:.2f}s-{end_ts:.2f}s, output file: {output_filename}")# 生成CPU负载曲线数据window_size = 1.0 # 滑动窗口大小(秒)interval = 0.1 # 采样间隔(秒)time_points = np.arange(start_ts, end_ts, interval)cpu_load_data = defaultdict(list)logger.info(f"start analysis cpu loading, cpu number: {len(state.cpus)}")for cpu in state.cpus:periods = state.cpus[cpu].time_periodsfor t in time_points:window_start = t - window_size / 2window_end = t + window_size / 2if window_start < start_ts or window_end > end_ts:continuetotal_active_time = 0.0for (p_start, p_end, is_active) in periods:if p_end <= window_start or p_start >= window_end:continueoverlap_start = max(p_start, window_start)overlap_end = min(p_end, window_end)if is_active:total_active_time += overlap_end - overlap_startload_pct = (total_active_time / window_size) * 100 if window_size > 0 else 0cpu_load_data[cpu].append((t - start_ts, load_pct))logger.info(f"create chart...")# 创建图表fig = go.Figure()colors = ['#1f77b4', '#ff7f0e', '#2ca02c', '#d62728','#9467bd', '#8c564b', '#e377c2', '#7f7f7f']# 为每个CPU添加折线for idx, cpu in enumerate(sorted(cpu_load_data.keys())):data = cpu_load_data[cpu]if not data:continuetimes, loads = zip(*data)fig.add_trace(go.Scatter(x=list(times),y=list(loads),mode='lines',name=f'CPU {cpu}',line=dict(color=colors[idx % len(colors)]),hovertemplate='CPU: %{name}<br>Time: %{x:.2f} s<br>Load: %{y:.2f}%'))fig.update_layout(title="CPU Load Percentage Over Time",xaxis_title='Time (s from start)',yaxis_title='Load (%)',legend=dict(orientation="h",yanchor="bottom",y=1.02,xanchor="right",x=1),hovermode='x unified')# 生成线程表格数据cpus = sorted(state.cpus.keys())thread_data = []for (name, pid), stats in state.threads.items():total_time = stats.total_timetotal_percent = total_time / (end_ts - start_ts) * 100 if (end_ts - start_ts) > 0 else 0row = {'PID': pid, 'Name': name, 'Total (%)': f"{total_percent:.2f}%"}for cpu in cpus:cpu_time = stats.cpu_time.get(cpu, 0.0)cpu_percent = cpu_time / (end_ts - start_ts) * 100 if (end_ts - start_ts) > 0 else 0row[f'CPU {cpu}'] = f"{cpu_percent:.2f}%"thread_data.append(row)# 创建数据表格df = pd.DataFrame(thread_data)table = go.Table(header=dict(values=list(df.columns),fill_color='paleturquoise',align='left'),cells=dict(values=[df[col] for col in df.columns],fill_color='lavender',align='left'))# 创建布局fig2 = go.Figure(data=[table])fig2.update_layout(title="Thread Load Statistics")# 组合布局并保存from plotly.subplots import make_subplotscombined_fig = make_subplots(rows=2, cols=1,subplot_titles=("CPU Load Percentage Over Time", "Thread Load Statistics"),specs=[[{'type': 'xy'}], [{'type': 'domain'}]])for trace in fig.data:combined_fig.add_trace(trace, row=1, col=1)for trace in fig2.data:combined_fig.add_trace(trace, row=2, col=1)combined_fig.update_layout(height=800, width=1200)combined_fig.write_html(output_filename)report_duration = (datetime.datetime.now() - report_start).total_seconds()logger.info(f"end report, {output_filename}, consume duration: {report_duration:.2f}s")# ----------------------
# 主流程
# ----------------------
def analyze_ftrace(log_path: str):"""主分析流程"""state = GlobalState()first_ts = Nonelast_ts = 0.0parse_start = datetime.datetime.now()logger.info("start parse ftrace log...")with open(log_path) as f:line_count = sum(1 for _ in f)logger.info(f"ftrace log file contains {line_count} lines")f.seek(0)for line in f:entry = FtraceParser.parse_line(line)if not entry:continuets = entry['timestamp']if first_ts is None:first_ts = tslast_ts = tsif entry['event'] == 'sched_switch':EventProcessor.handle_sched_switch(state, entry)elif entry['event'] == 'sched_stat_runtime':EventProcessor.handle_sched_stat_runtime(state, entry)# 处理最后未结束的时间段for cpu in state.current_pid:(running_comm, running_pid), start_ts = state.current_pid[cpu]running_key = (running_comm, running_pid)comm = running_commis_active = not EventProcessor._is_swapper(comm, running_pid)state.cpus[cpu].time_periods.append((start_ts, last_ts, is_active))duration = last_ts - start_tsif is_active:state.cpus[cpu].total_active += durationstate.threads[running_key].cpu_time[cpu] += durationstate.threads[running_key].total_time += durationelse:state.cpus[cpu].total_idle += durationstate.threads[running_key].cpu_time[cpu] += durationstate.threads[running_key].total_time += durationduration = (datetime.datetime.now() - parse_start).total_seconds()logger.info(f"end parse ftrace log, duration:{duration:.2f}s")# 生成报告if first_ts is not None:ReportGenerator.generate_html_report(state, first_ts, last_ts)if __name__ == "__main__":import sysif len(sys.argv) != 2:print("Usage: python ftrace_analyzer.py <ftrace.log>")sys.exit(1)analyze_ftrace(sys.argv[1])