小样本学习和元学习
一、小样本学习
1、小样本学习介绍
小样本学习(Few-Shot Learning, FSL)是机器学习的一个分支,旨在解决模型在极少量标注样本(甚至单样本)下快速学习和泛化的问题。其核心目标是让模型具备类似人类的“举一反三”能力,通过少量示例就能识别或处理新任务。
传统深度学习需要大量标注数据,但在现实场景中(如医疗、罕见物体识别),标注数据可能极其稀缺。
2、小样本学习的的关键方法
小样本学习的实现通常依赖以下技术:
元学习(Meta-Learning):训练模型掌握“如何学习”,而非直接学习特定任务。
数据增强与生成:利用生成对抗网络(GAN)或变分自编码器(VAE)生成合成样本,扩充训练数据。
度量学习(Metric Learning)学习一个嵌入空间,使得相似样本靠近、不相似样本远离。
迁移学习(Transfer Learning)在大规模数据集(如ImageNet)上预训练模型,再微调少量新数据。例如:冻结底层特征提取层,仅调整分类头。
3、学习框架
首先使用一个较大的数据集作为训练集training set,这个训练集是有标签的,每个标签下有充足的样本,使用合适的网络模型进行训练,使模型学会区分每一类数据的差别,即训练出一个相似度函数。训练后,给模型一个query,这个query没有出现在原始训练集中,同时提供一个支持集supprot set,支持集中有小样本数据,这些数据也有标签。通过对比query和support set中照片的相似度,找到与query最相似的照片,进而得到query的标注数据。


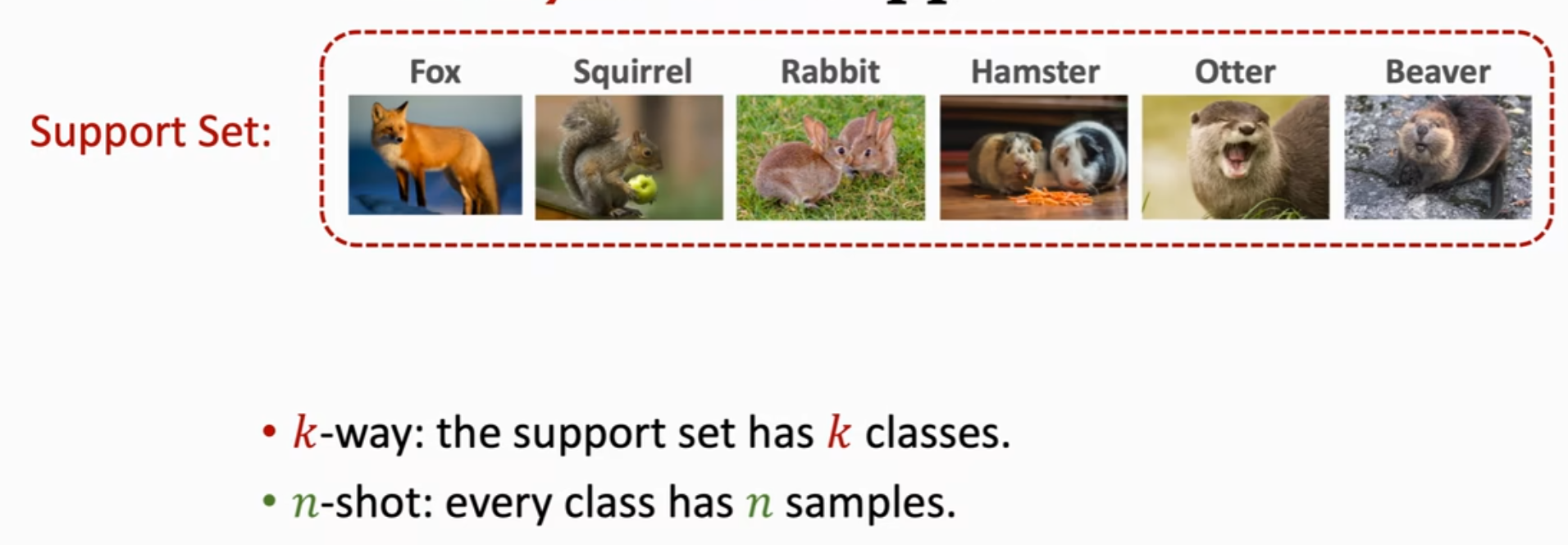
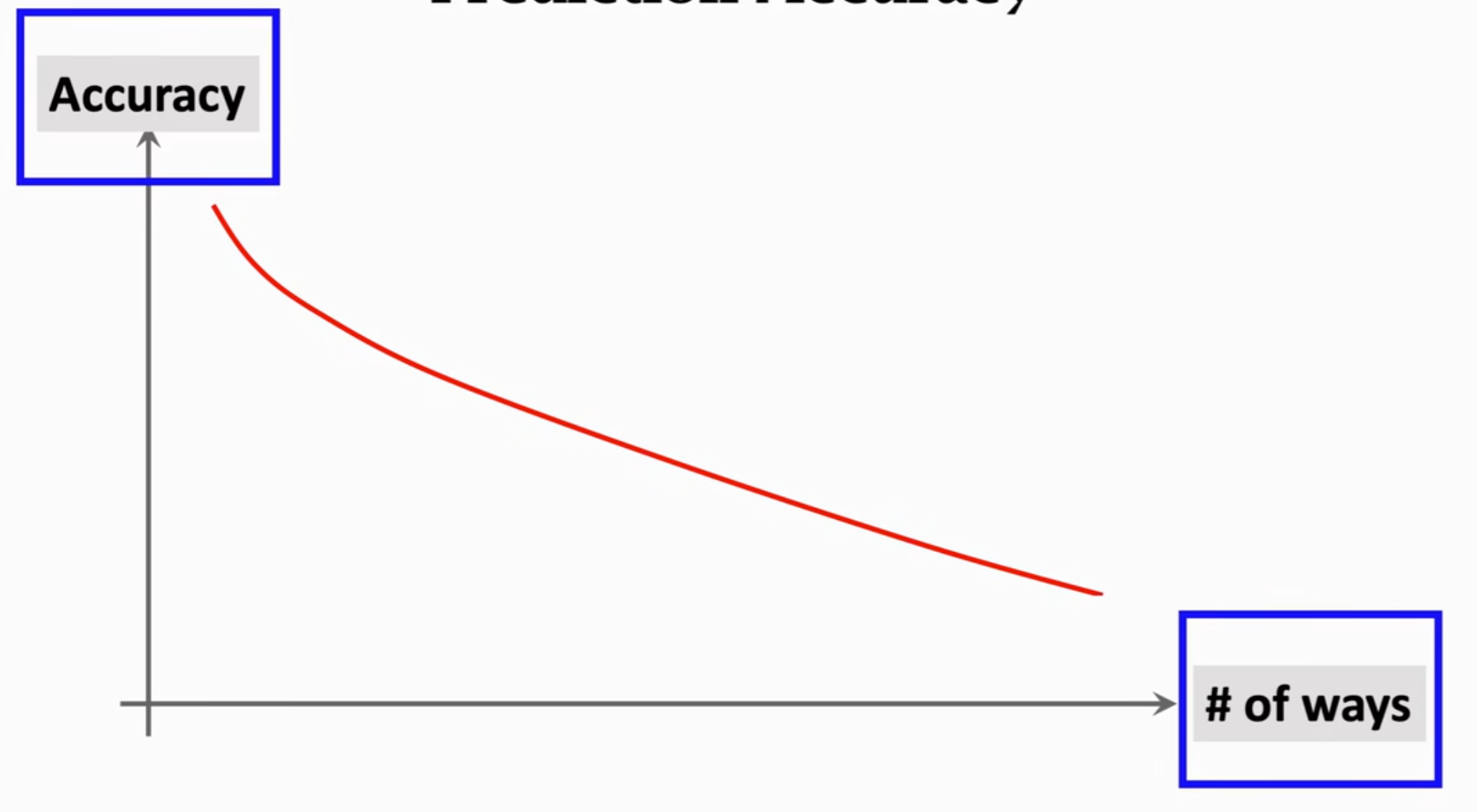
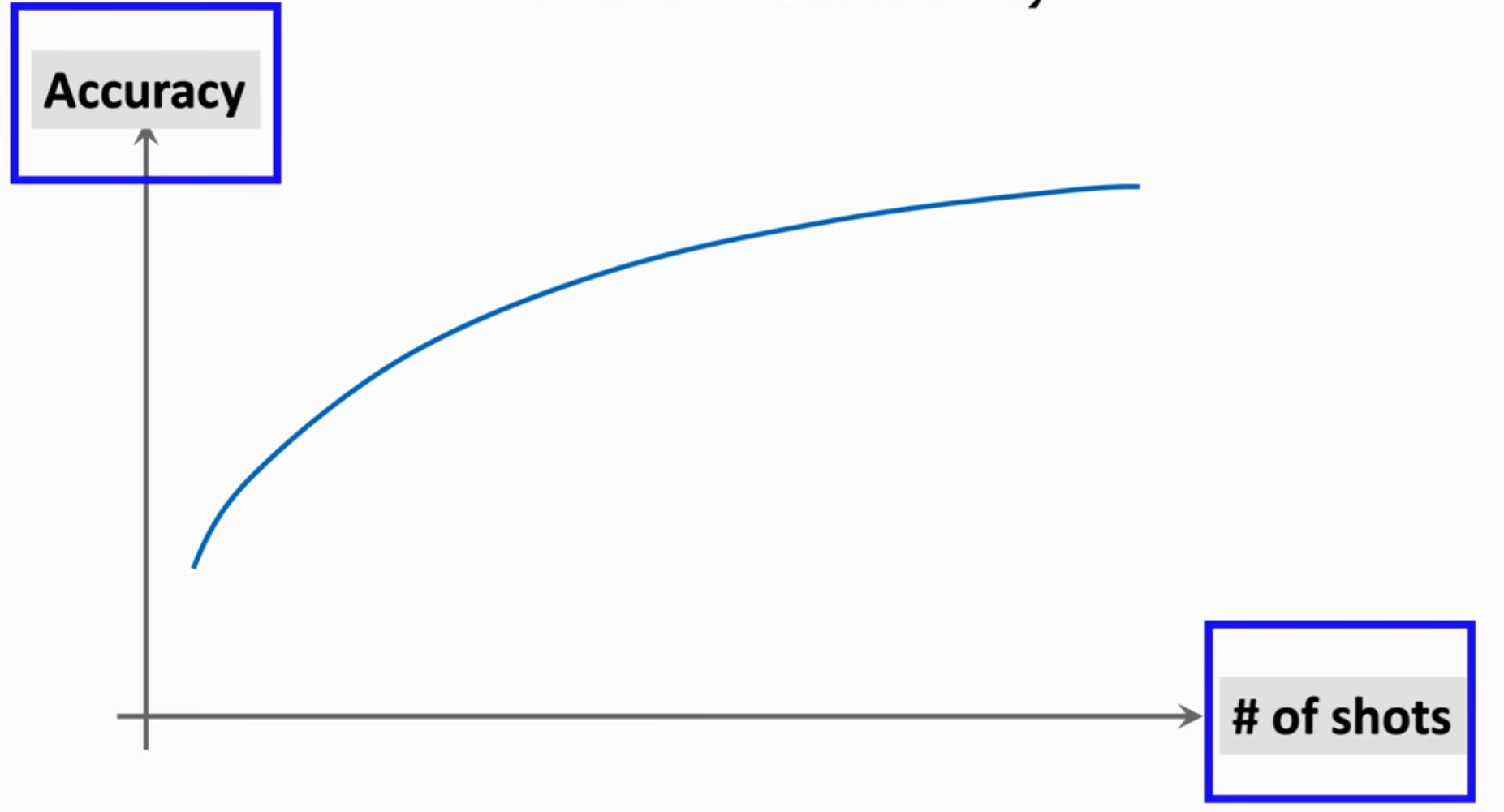
对于support set中的一些概念:给出k个类别就是k-way,每个类别有n个样本就是one-shot,下图所示的支持集是six-way one-shot。不难理解,如果支持集中分类的类别数越多,则模型想要挑选出最合适的类别会更难,accuracy会下降;如果支持集中每个类别提供的样本数越多,则越容易捕捉到共同特征,找到正确分类,accuracy会更高。如下图所示。
小样本学习与传统监督学习的区别:传统的监督学习要求模型学习训练数据,并将其泛化到测试数据,而few-shot learning或者meta learning是让模型自己学会学习。
二、训练相似度函数的方法:孪生神经网络(siamese network)
1、对比损失优化
①数据标记:从原始数据集中生成正负样本对。正样本对是从同一类别中随机选取两个样本(例如同一人的不同人脸图像),负样本对是从不同类别中各选一个样本(例如不同人的图像),形成如下图所示的样本对。

②模型构建:使用同一个卷积神经网络提取图片特征,得到表征图片的特征向量。使用度量两个特征向量之间的差异,后接全连接层得到一个标量,使用sigmoid函数将标量值映射到-1~1之间,输出值越接近target说明分类越准确。损失函数是target和output的差异,通过反向传播更新模型参数,使输出更接近target。
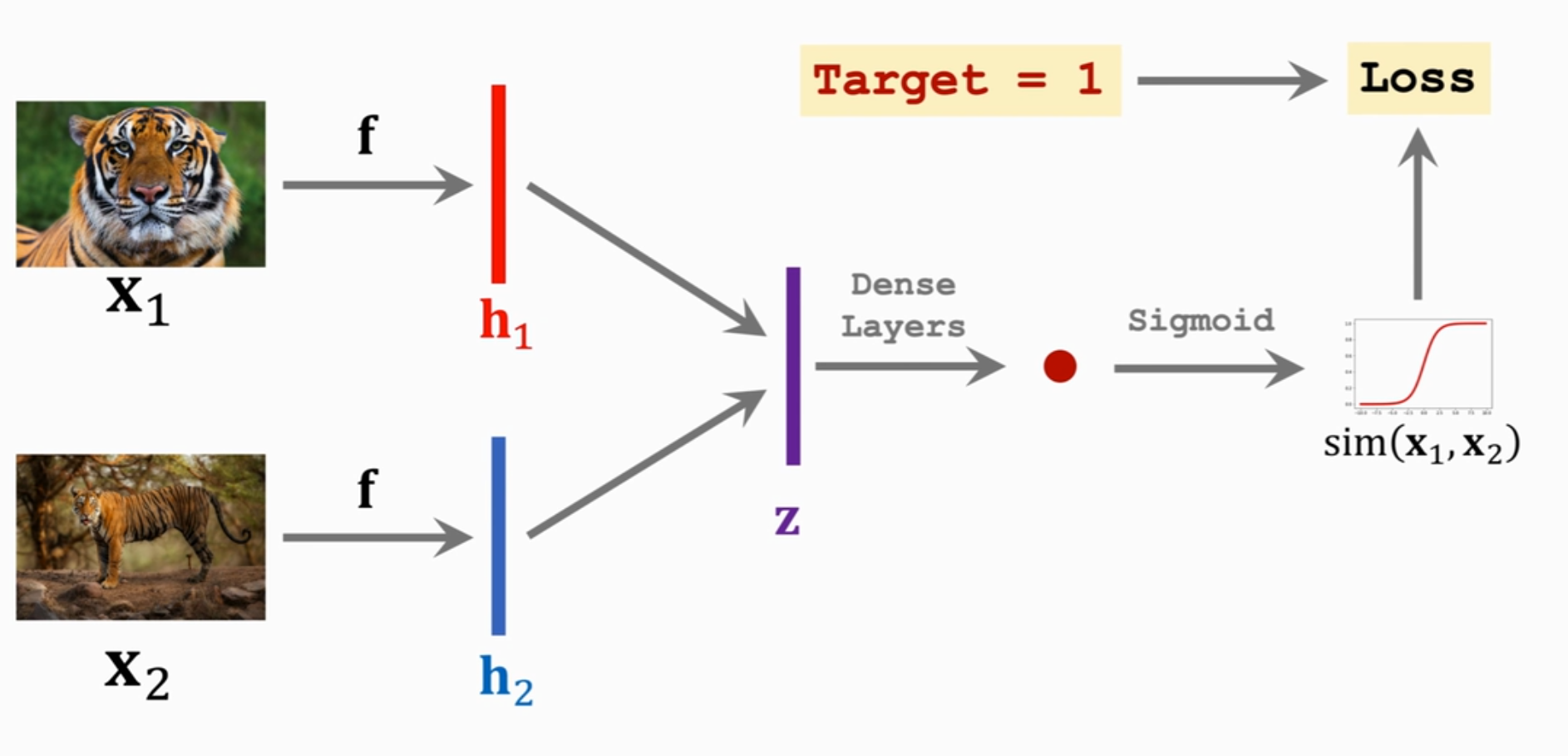
③模型应用:给定一个query和一组支持集,将query和支持集中的每个样本组队输入到模型中,得到一个相似度输出,输出值最大的pair的支持集中样本标注即是该query的标注。
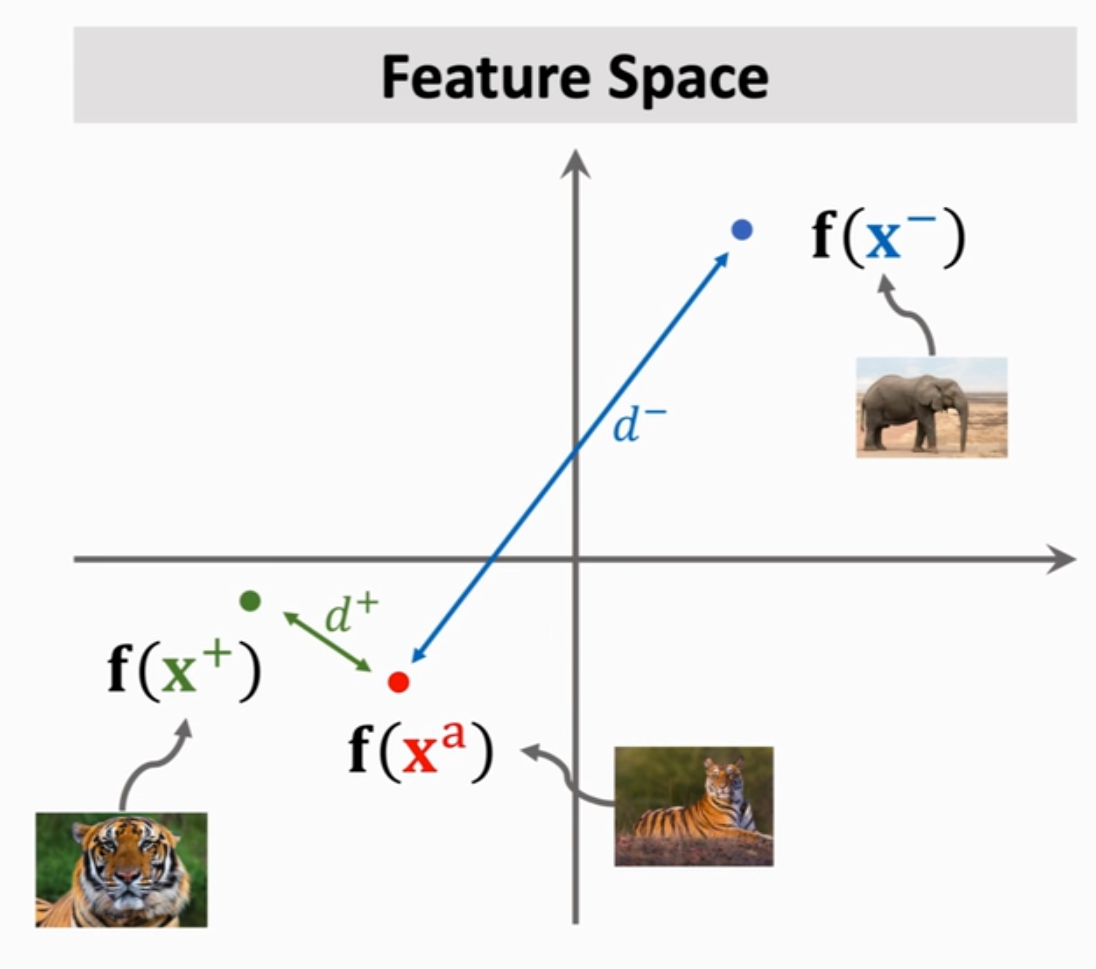
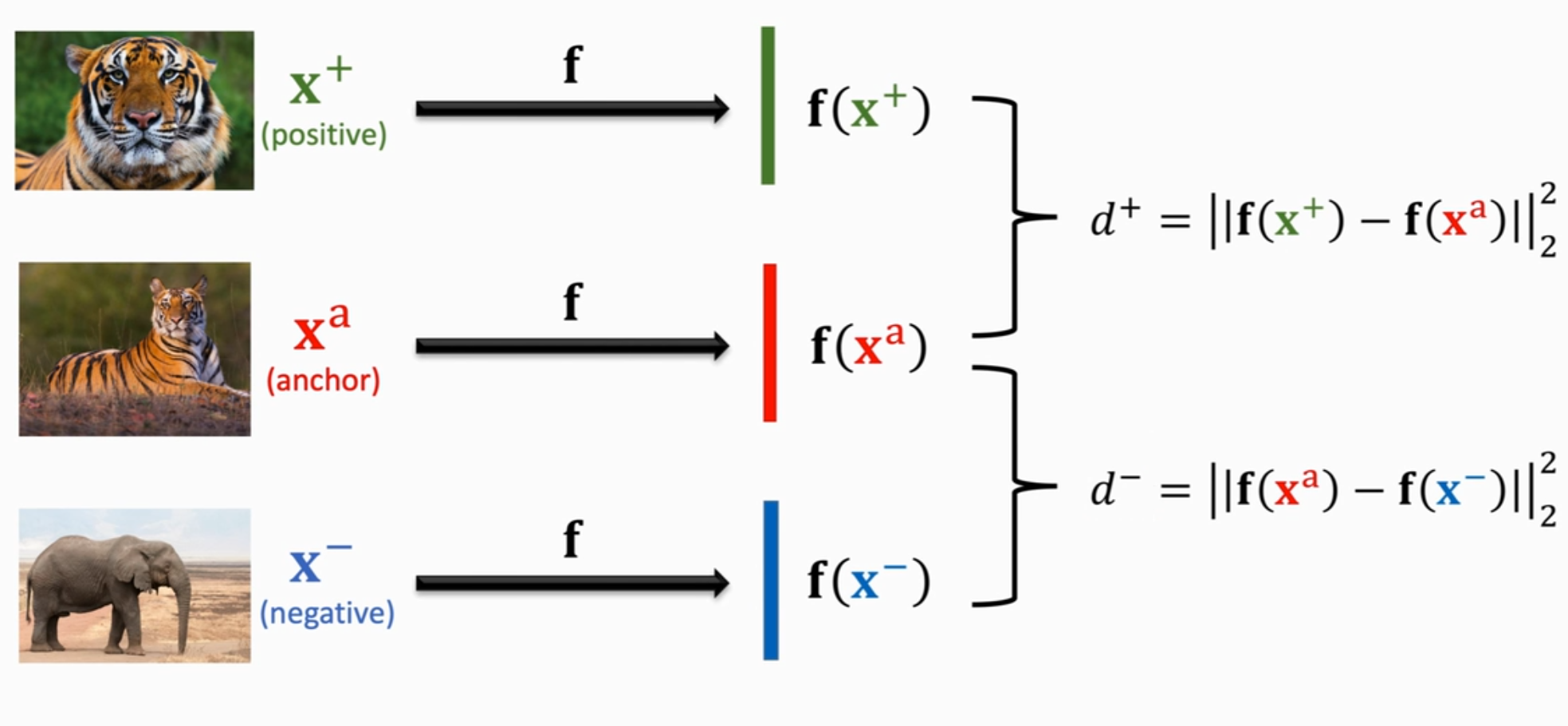
2、三元组损失优化(triplet loss)
三元组损失(Triplet Loss) 是深度学习中的一种损失函数,专门用于训练模型学习区分性特征表示(即让相似样本在特征空间中靠近,不相似样本远离)。
①数据标记:三元组损失通过同时比较一个锚点样本(Anchor)、一个正样本(Positive)和一个负样本(Negative)。
Anchor(A):选定的基准样本。
Positive(P):与 Anchor 同类的另一个样本。
Negative(N):与 Anchor 不同类的样本。
②模型构建:同样可以使用同一个卷积神经网络得到图片的特征向量,优化模型使得:锚点与正样本的距离 d(A,P) 尽可能小(同类更接近)。锚点与负样本的距离 d(A,N) 尽可能大(异类更远离)。并且要求 d(A,P)d(A,P) 至少比 d(A,N) 小一个边际值(Margin)α。
loss的数学表达式:
其中:d(A,P)是锚点与正样本的特征距离。d(A,N):锚点与负样本的特征距离。α:超参数,控制正负样本对的区分强度。
③模型应用:给定一个query和一组支持集,将query和支持集中的每个样本组队输入到模型中,得到一个距离输出,输出值最小的pair的支持集中样本标注即是该query的标注。
三、小样本预测方法
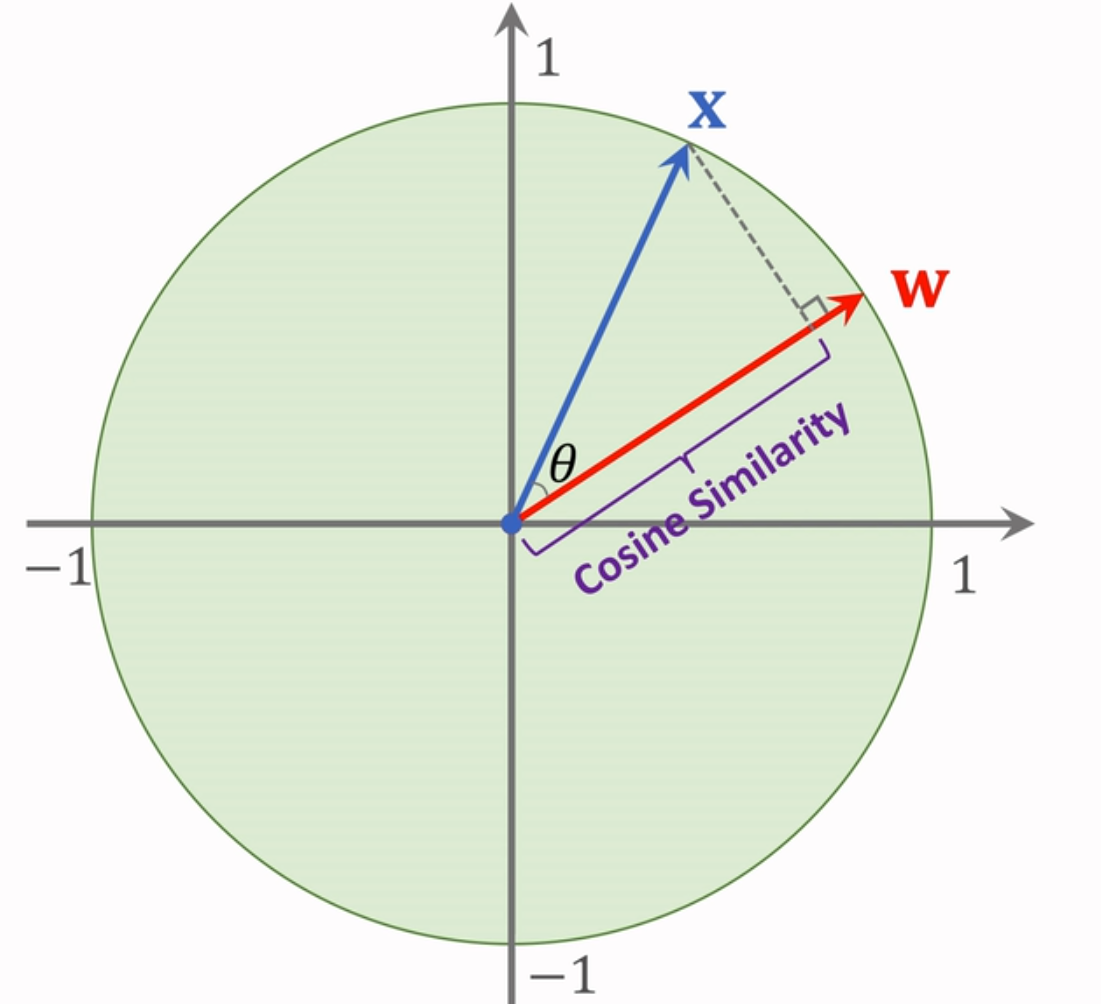
1、使用余弦相似度来代替第二节提到的2种相似度和距离的计算方法
余弦相似度(Cosine Similarity) 是一种衡量两个向量方向相似程度的指标,通过计算它们夹角的余弦值来评估相似性。当两个向量的模长是1时,余弦相似度就为他们的内积;若不为1,则需要归一化到1,再做内积。
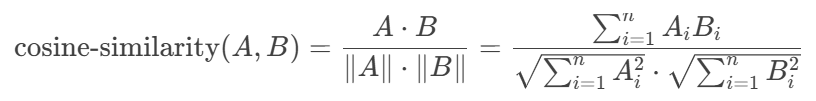
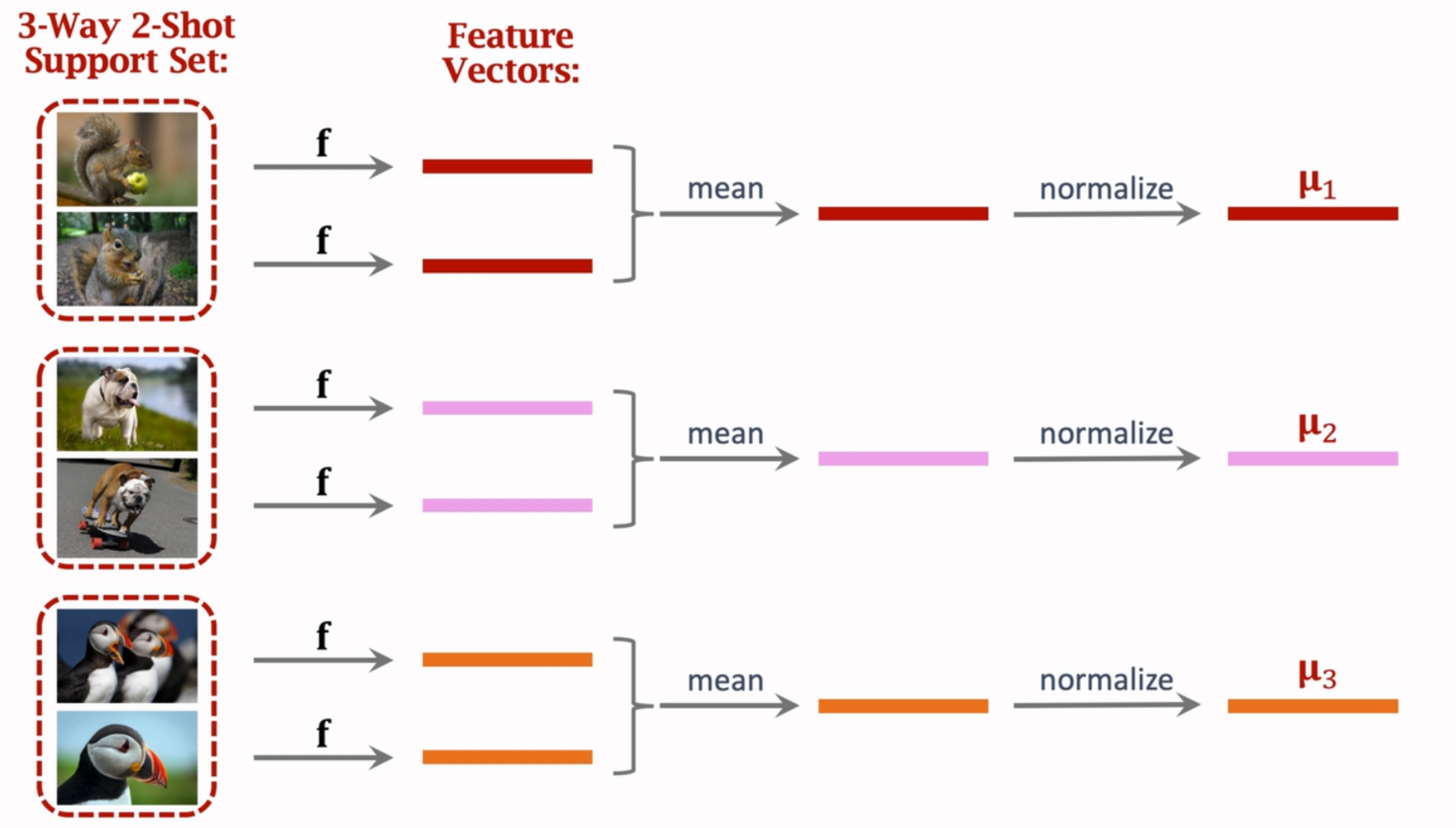
这种方法使用的场景一般是:support set是3-way 2-shot的情况,对于每一类中的两个shot经过网络得到特征向量,再计算均值和归一化得到μ,这里的M是
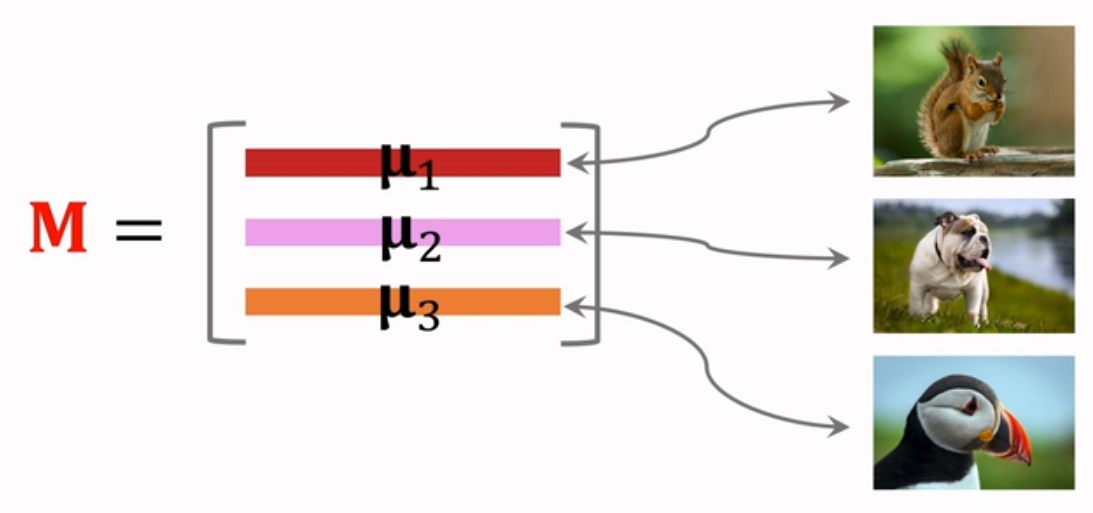
预测时,query的特征向量与三个support set的特征向量做内积,即余弦相似度,得到最终的预测概率,概率最大的即为正确分类的标签。

2、使用支持集进行微调
①合理初始化:前面直接将M与q做内积得到余弦相似度,在这里,添加两个可训练参数,相当于一个全连接层,权重W初始化为M,偏差b初始化为0,进行训练。损失函数是支持集预测类别和真实类别的交叉熵损失。

②在query预测时,增加entropy regularization。每次预测会有很多个query,对每一个query计算熵值,再求所有熵值的平均,这个值应该越小越好
