线性回归之归一化(normalization)
文章目录
- 归一化与梯度下降
- 归一化的必要性:从特征量纲到梯度下降
- 问题背景
- 矛盾与低效
- 归一化的作用
- 归一化提高模型精度的原因
- 归一化的本质
- 常见归一化方法
- 最大值最小值归一化
- 示例说明
- 优缺点分析
- 标准归一化
- 具体机制
- 示例说明
- 强调
归一化与梯度下降
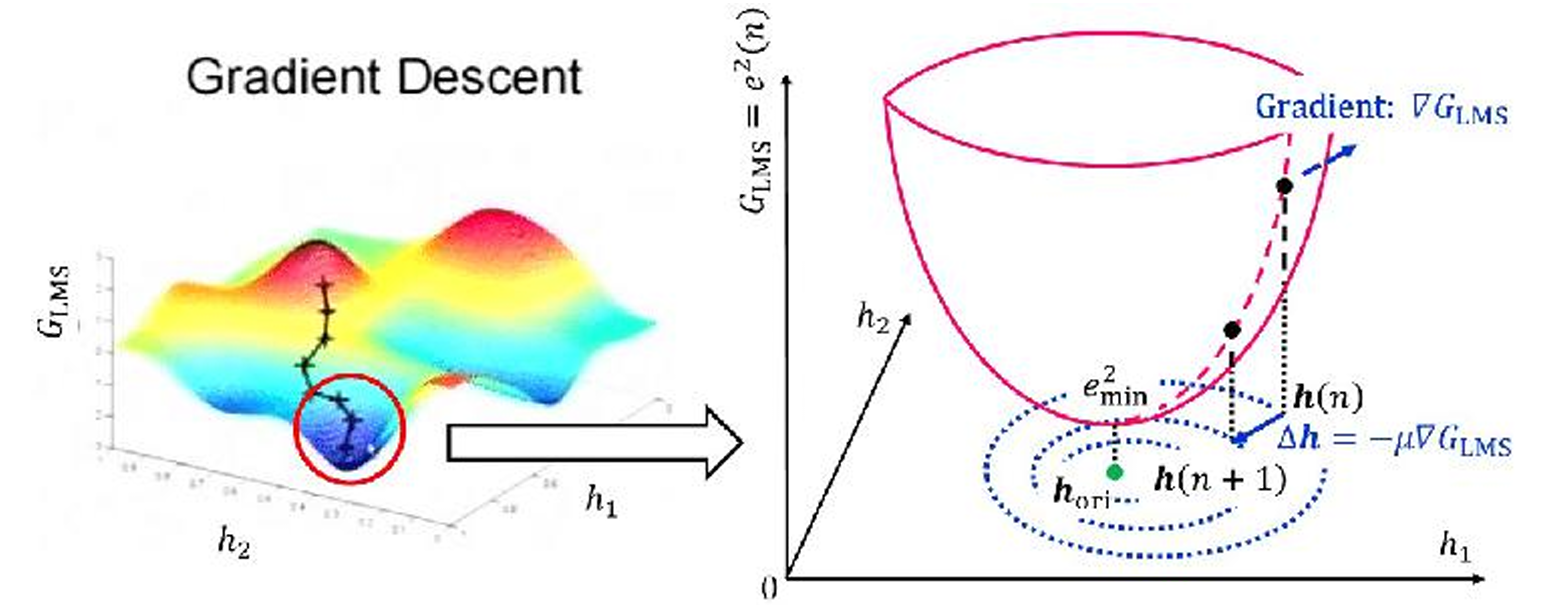
- 归一化与梯度下降 :在多元线性回归中,损失函数(MSE)是凸函数,可类比为碗状曲面。梯度下降的目标是找到碗底(损失最小点)。
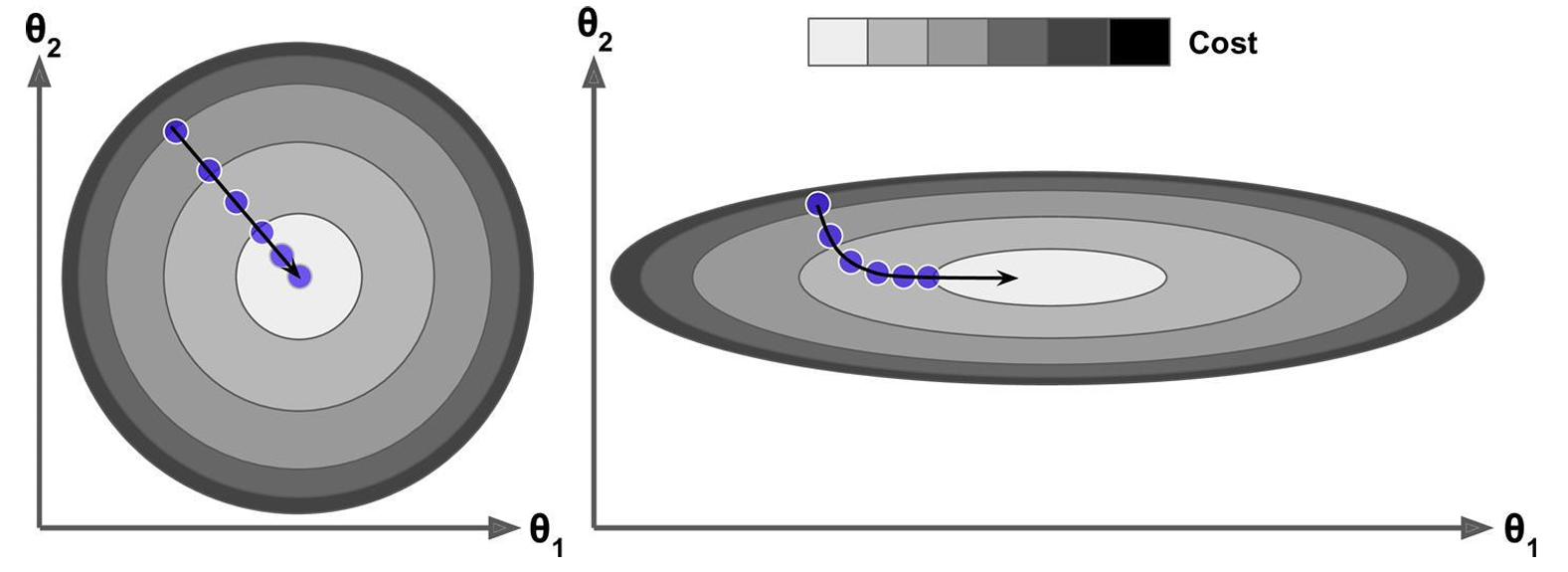
可视化说明
-
左图:归一化后的损失函数(等高线均匀,利于梯度下降)
-
右图:未归一化的损失函数(等高线狭长,收敛困难)
-
关键结论:归一化能优化损失函数的几何形态,使梯度下降更高效。
归一化的必要性:从特征量纲到梯度下降
问题背景
假设我们有两个特征:
- 年龄(X₁):数值较小(如 25、36、49)
- 收入(X₂):数值较大(如 10,000、50,000、30,000)
| name | age | income |
|---|---|---|
| 张三 | 25 | 10000 |
| 李四 | 36 | 50000 |
| 王五 | 49 | 30000 |
- 在多元线性回归中,模型方程为: y = θ 1 X 1 + θ 2 X 2 y = \theta_1 X_1 + \theta_2 X_2 y=θ1X1+θ2X2
计算机无法理解特征的物理含义,仅视作数值计算。若未归一化:
- 初始参数(θ₁, θ₂):通常随机初始化,数值相近(如 ~0.01)。
- 特征量级差异:由于 X 2 ≫ X 1 X_2 \gg X_1 X2≫X1,梯度更新时:
- 梯度公式 ∇ θ j = ( h θ ( X ) − y ) X j \nabla_{\theta_j} = (h_\theta(X)-y)X_j ∇θj=(hθ(X)−y)Xj⇒ ∇ θ 2 ≫ ∇ θ 1 \nabla_{\theta_2} \gg \nabla_{\theta_1} ∇θ2≫∇θ1
- 参数更新幅度: Δ θ 2 ≫ Δ θ 1 \Delta \theta_2 \gg \Delta \theta_1 Δθ2≫Δθ1
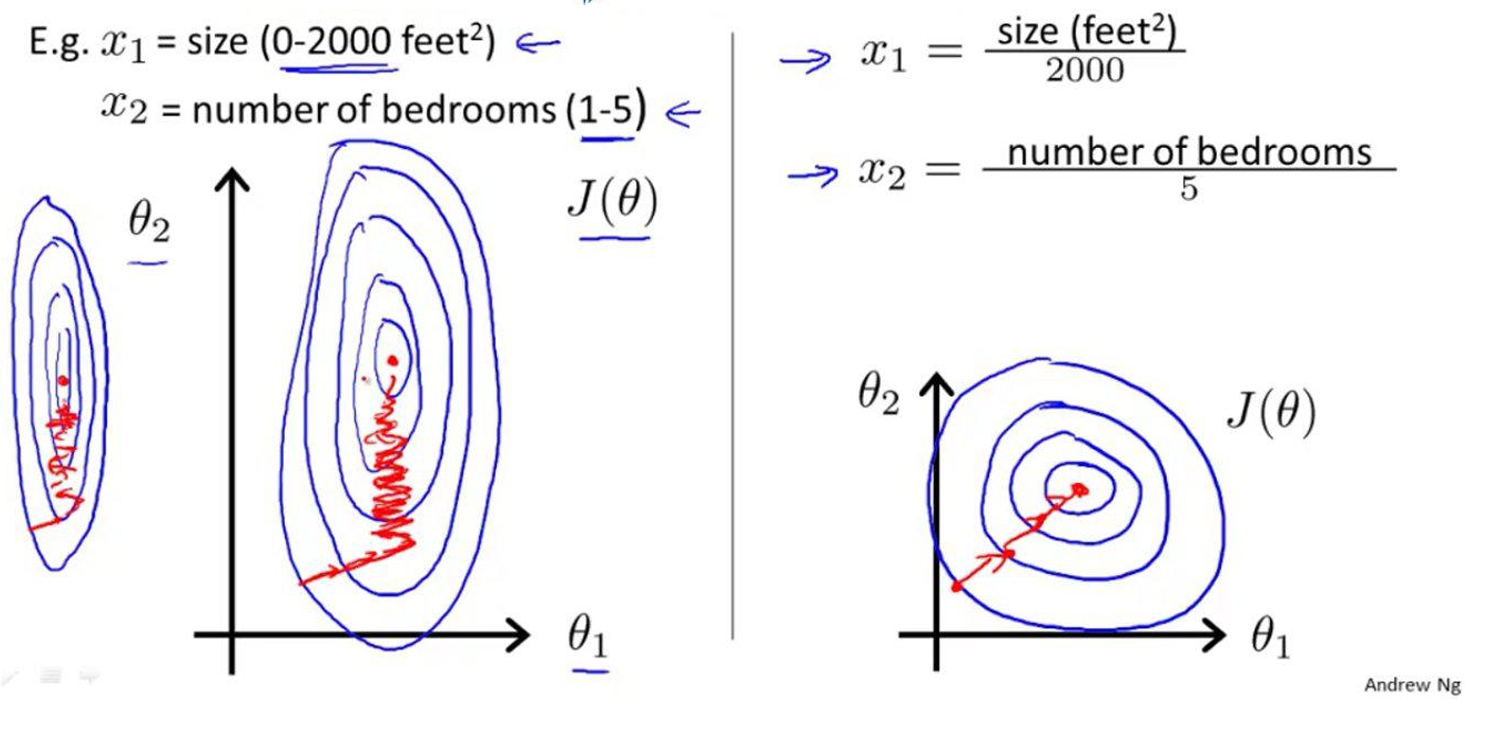
矛盾与低效
- 收敛速度不一致:
- θ 2 \theta_2 θ2 因梯度大,快速收敛;
- θ 1 \theta_1 θ1因梯度小,收敛缓慢,拖慢整体优化。
- 优化路径曲折:如右图所示,梯度下降会先沿 θ 2 \theta_2 θ2 轴快速下降,再缓慢调整 θ 1 \theta_1 θ1,形成“之字形”路径。
归一化的作用
通过归一化(如 Z-score),使所有特征处于相近量级(如 μ=0, σ=1),从而:
- 梯度均衡化:各维度参数的更新幅度相近。
- 同步收敛:避免部分参数等待,提升优化效率。
- 类比说明 :未归一化(如“部分人先富”,导致优化不均衡);归一化(如“共同富裕”,所有参数同步优化,步伐一致)。
归一化提高模型精度的原因
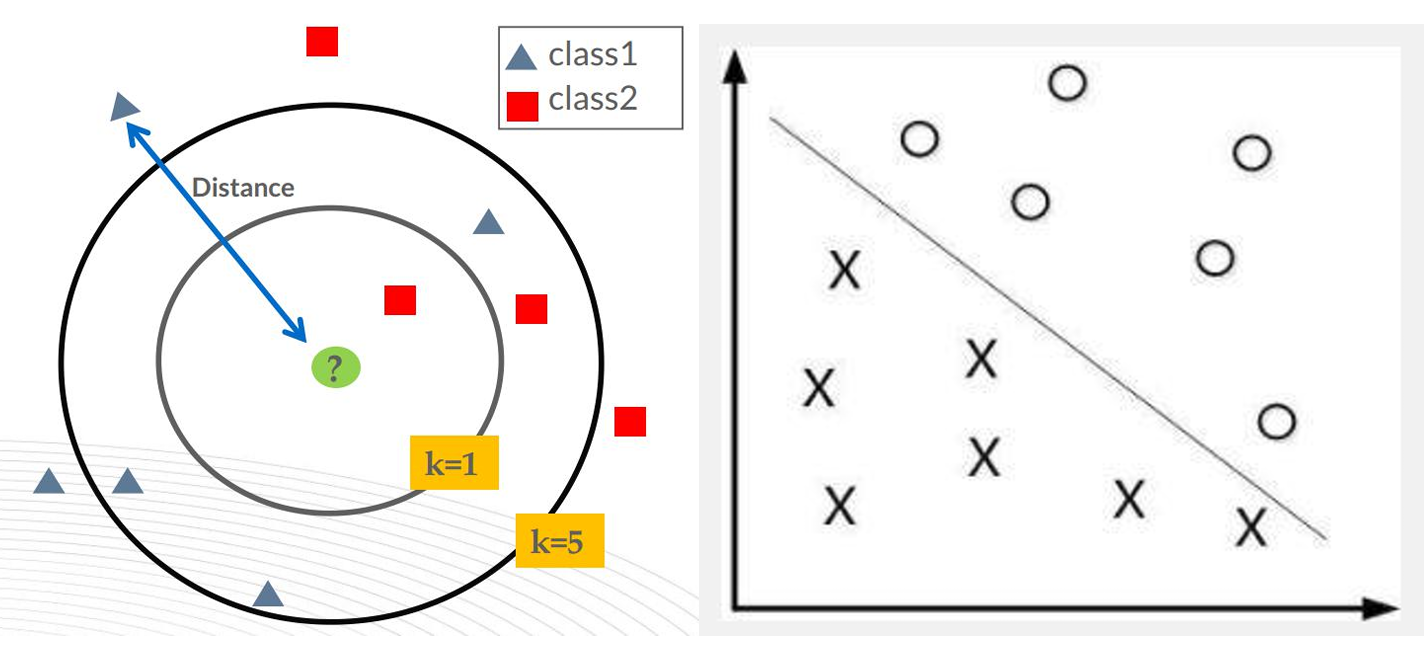
- 保证距离计算的合理性
- 问题:在KNN等依赖距离的算法中,若某一特征数值过大(如收入 X 1 = 10 , 000 20 , 000 X₁=10,000~20,000 X1=10,000 20,000),而另一特征过小(如年龄 X 2 = 1 2 X₂=1~2 X2=1 2),距离计算会被大数值特征主导,导致结果失真。
- 解决:归一化后,所有特征处于相近范围(如0~1),模型能更合理地综合各维度信息。
- 避免分类失效
- 问题:若特征量纲差异极大(如X₁范围 1 万 2 万 1万~2万 1万 2万,X₂范围 1 2 1~2 1 2),数据点可能近似分布在一条直线上,导致分类器(如SVM、逻辑回归)无法找到有效的分界超平面。
- 解决:归一化消除量纲影响,使分类边界更准确。
归一化的本质
- 归一化作用:将所有特征统一到相同数量级,实现“无量纲化”,使模型能公平对待每个特征。
- 归一化通过数学变换消除特征间的量纲差异,是数据预处理中的“公平调节器”。
常见归一化方法
最大值最小值归一化
对每个特征 X i X_i Xi进行数学变换,常见方法包括:
- Min-Max归一化:压缩到 [0, 1] 区间
X i , j ∗ = X i , j − X j m i n X j m a x − X j m i n X_{i,j}^* = \frac{X_{i,j} - X_{j}^{min}}{X_{j}^{max} - X_{j}^{min}} Xi,j∗=Xjmax−XjminXi,j−Xjmin- x j m i n x_{j}^{min} xjmin是对应X矩阵中第 j j j列特征值的最小值
- x j m a x x_{j}^{max} xjmax是对应 X X X矩阵中第 j j j列特征值的最大值
- x i , j x_{i,j} xi,j是X矩阵中第 i i i行第 j j j列的数值
- X i , j ∗ X_{i,j}^* Xi,j∗是归一化之后的 X X X矩阵中第 i i i行第 j j j列的数值
示例说明
正常数据归一化
- 原始数据:
[1, 2, 3, 5, 5] - 计算参数:
- 最小值 x j m i n = 1 x_j^{min}=1 xjmin=1
- 最大值 x j m a x = 5 x_j^{max}=5 xjmax=5
- 归一化结果:
[0, 0.25, 0.5, 1, 1]
from sklearn.preprocessing import MinMaxScaler
import numpy as npdata = np.array([[1], [2], [3], [5], [5]]) # 注意需要二维数组
scaler = MinMaxScaler()
normalized = scaler.fit_transform(data)
print(normalized.flatten()) # 输出: [0. 0.25 0.5 1. 1. ]
含离群值数据归一化
- 原始数据:
[1, 2, 3, 5, 50001] - 归一化结果:
[0, 0.00002, 0.00004, 0.00008, 1]
from sklearn.preprocessing import MinMaxScaler
import numpy as np
outlier_data = np.array([[1], [2], [3], [5], [50001]])
scaler = MinMaxScaler()
outlier_normalized = scaler.fit_transform(outlier_data)
print(outlier_normalized.flatten()) # 输出: [0. 0.00002 0.00004 0.00008 1. ]
优缺点分析
| 特性 | 说明 |
|---|---|
| ✅ 优点 | 保证所有数值严格落在[0,1]区间 |
| ❌ 缺点 | 对离群值敏感,会导致正常数据分布失衡 |
标准归一化
- 标准归一化通常包含均值归一化和方差归一化。。经过处理的数据符合标准正态分
布,即均值为0,标准差为1。
X n e w = X i − 1 n ∑ i = 1 k f i x i 1 n ∑ i = 1 k f i ( x i − μ ) 2 X_{new}=\frac{X_i- \frac{1}{n}\sum_{i=1}^{k} f_i x_i}{\sqrt{\frac{1}{n}\sum_{i=1}^{k} f_i (x_i - \mu)^2} } Xnew=n1∑i=1kfi(xi−μ)2Xi−n1∑i=1kfixi
X new = X i − μ σ X_{\text{new}} = \frac{X_i - \mu}{\sigma} Xnew=σXi−μ
将原始数据转换为均值为0、标准差为1的标准正态分布
均值计算(μ):
μ = 1 n ∑ i = 1 k f i x i \mu = \frac{1}{n}\sum_{i=1}^{k} f_i x_i μ=n1i=1∑kfixi
方差计算(σ²):
σ 2 = 1 n ∑ i = 1 k f i ( x i − μ ) 2 \sigma^2 = \frac{1}{n}\sum_{i=1}^{k} f_i (x_i - \mu)^2 σ2=n1i=1∑kfi(xi−μ)2
标准差计算(σ):
σ = σ 2 = 1 n ∑ i = 1 k f i ( x i − μ ) 2 \sigma = \sqrt{\sigma^2} =\sqrt{\frac{1}{n}\sum_{i=1}^{k} f_i (x_i - \mu)^2} σ=σ2=n1i=1∑kfi(xi−μ)2
- 除以方差的好处:标准归一化是除以的是标准差,而标准差的计算会考虑到所有样本数据,所以受到离群值的影响会小一些。但使用标准归一化不一定会把数据缩放到0到1之间。
- 标准归一化减去均值的原因:减去均值(均值归一化)使数据分布中心移至原点(μ=0),打破特征同符号限制,为梯度下降提供更灵活的优化路径。 减去均值不仅使数据符合标准正态分布,更通过引入特征符号多样性,解决梯度下降的方向耦合问题,提升优化效率。
具体机制
- 问题根源:
- 若特征均为正数(如年龄、收入),梯度公式中的 X j X_j Xj 始终为正,导致参数更新方向被锁定:
Δ w j = − α ⋅ ( h w ( X ) − y ) ⋅ X j \Delta w_j = -\alpha \cdot (h_w(X)-y) \cdot X_j Δwj=−α⋅(hw(X)−y)⋅Xj
- 若特征均为正数(如年龄、收入),梯度公式中的 X j X_j Xj 始终为正,导致参数更新方向被锁定:
- 当所有 X j > 0 X_j > 0 Xj>0时,梯度方向仅由残差 ( h w ( X ) − y ) (h_w(X)-y) (hw(X)−y)决定,所有 ( w_j ) 更新方向一致(同时增或减),无法高效逼近最优解。
- 均值归一化的改进:
- 通过 X new = X − μ σ X_{\text{new}} = \frac{X - \mu}{\sigma} Xnew=σX−μ,特征值围绕0对称分布(有正有负)。
- 梯度方向多样化:不同样本的 X j X_j Xj可能为正或负,使 w j w_j wj更新方向可独立变化(如 w 1 w_1 w1增、 w 2 w_2 w2 减),优化路径更接近直线(如蓝色最优路径),加速收敛。
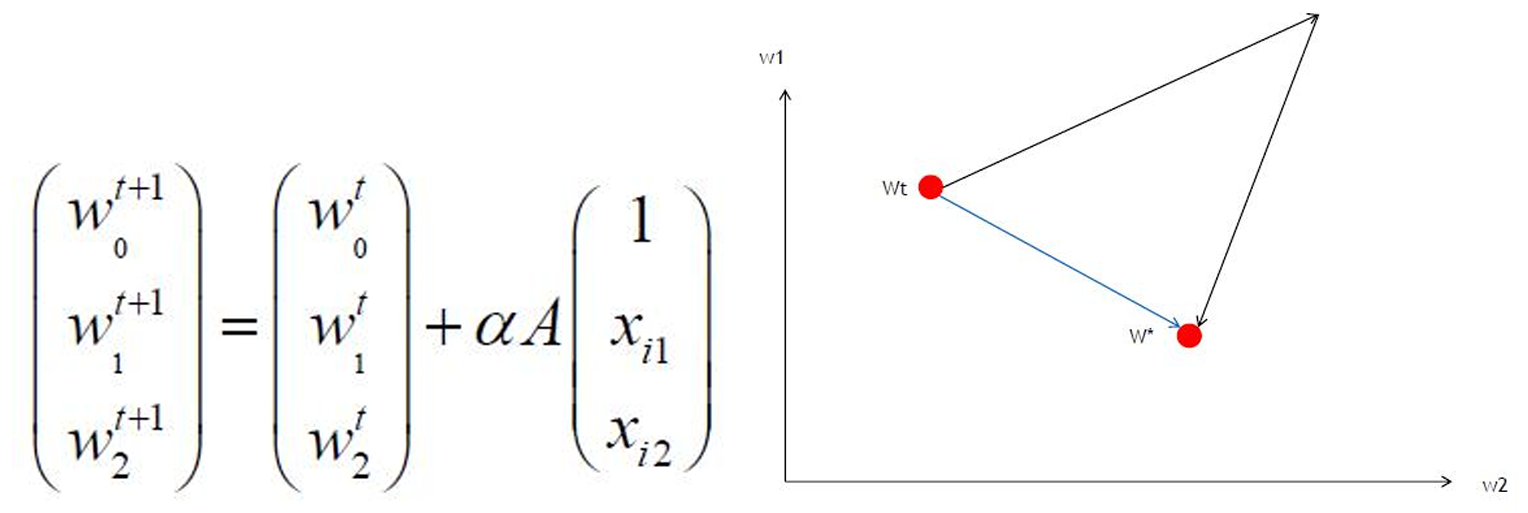
示例说明
- 原始数据:年龄( 25 50 25~50 25 50,全正数),收入( 10 , 000 50 , 000 10,000~50,000 10,000 50,000,全正数)。
- 归一化后:年龄( − 1.2 1.5 -1.2~1.5 −1.2 1.5,有正负),收入( − 0.8 1.3 -0.8~1.3 −0.8 1.3,有正负)。
- 梯度更新时, X j X_j Xj符号差异允许 w 1 w_1 w1 和 w 2 w_2 w2 反向调整,避免“之字形”路径。
pip install scikit-learn
from sklearn.preprocessing import StandardScaler# 创建一个二维列表,表示原始数据
data = [[1], [2], [3], [4], [5]]# 初始化 StandardScaler 对象
# StandardScaler 是 scikit-learn 提供的一个工具,用于对数据进行标准化处理。
# 标准化是指将数据转换为均值为 0、标准差为 1 的分布,公式为:z = (x - μ) / σ
# 其中,μ 是数据的均值,σ 是数据的标准差。
scaler = StandardScaler()# 使用 fit 方法拟合数据
# fit 方法会计算数据的均值(mean_)和方差(var_),并存储在 scaler 对象中。
print(scaler.fit(data))# 打印数据的均值
# mean_ 是 scaler 对象的一个属性,表示数据的均值。
print(scaler.mean_)# 打印数据的方差
# var_ 是 scaler 对象的一个属性,表示数据的方差。
print(scaler.var_)# 使用 transform 方法对数据进行标准化
# transform 方法会根据 fit 方法计算出的均值和方差,将数据转换为标准正态分布。
print(scaler.transform(data))
# 执行结果
'''
[3.]
[2.]
[[-1.41421356][-0.70710678][ 0. ][ 0.70710678][ 1.41421356]]
'''
强调
-
特征工程,很多时候如果对训练集的数据进行预处理,比如这里讲的归一化,那么未来对测试集和模型上线来新的数据的时候,都要进行相同的数据预处理流程,而且所使用的均值和方差是来自当时训练集的均值和方差!因为人工智能就是从训练集数据中找规律,然后利用找到的规律去预测未来。这也就是说假设训练集和测试集以及未来新来的数据是属于同分布的!
-
从代码上面来说如何去使用训练集的均值和方差呢?如果是上面代码的话,就需要把scaler对象持久化,模型上线再加载进来对新来的数据使用。
-
代码案例
from sklearn.preprocessing import StandardScaler
import joblib# 创建一个二维列表,表示原始数据
data = [[1], [2], [3], [4], [5]]# 初始化 StandardScaler 对象
# StandardScaler 是 scikit-learn 提供的一个工具,用于对数据进行标准化处理。
# 标准化是指将数据转换为均值为 0、标准差为 1 的分布,公式为:z = (x - μ) / σ
# 其中,μ 是数据的均值,σ 是数据的标准差。
scaler = StandardScaler()# 使用 fit 方法拟合数据
# fit 方法会计算数据的均值(mean_)和方差(var_),并存储在 scaler 对象中。
print(scaler.fit(data))# 打印数据的均值
# mean_ 是 scaler 对象的一个属性,表示数据的均值。
print(scaler.mean_)# 打印数据的方差
# var_ 是 scaler 对象的一个属性,表示数据的方差。
print(scaler.var_)# 使用 transform 方法对数据进行标准化
# transform 方法会根据 fit 方法计算出的均值和方差,将数据转换为标准正态分布。
print(scaler.transform(data))# 持久化 scaler 对象
joblib.dump(scaler, 'scaler.pkl')# 创建新的测试数据
new_data = [[6], [7], [8]]# 加载 scaler 对象
loaded_scaler = joblib.load('scaler.pkl')# 使用加载的 scaler 对象对新数据进行标准化
print(loaded_scaler.transform(new_data))