【HDFS入门】HDFS故障排查与案例分析:从日志分析到实战解决
目录
1 HDFS故障排查概述
2 三大常见故障类型解析
2.1 块丢失问题处理流程
2.2 副本不足问题架构
2.3 DataNode无法启动诊断
3 日志分析实战技巧
3.1 NameNode日志分析框架
3.2 DataNode日志分析流程
4.1 实战案例分析
4.2 集群性能突然下降
4.2 数据读写异常处理
5 预防性维护建议
5.1 健康检查清单
5.2 关键监控指标
6 总结
1 HDFS故障排查概述
HDFS作为大数据生态的存储基石,其稳定性直接影响整个数据平台的可用性。本文将深入解析HDFS常见故障类型、日志分析技巧,并通过真实案例演示排查流程,帮助您快速定位和解决生产环境中的各类存储问题。
2 三大常见故障类型解析
2.1 块丢失问题处理流程

关键处理步骤:
- 使用hdfs fsck /path -files -blocks确认丢失块范围
- 临时设置dfs.replication=5加速恢复
- 通过hdfs dfsadmin -fetchImage获取最新元数据
- 最终使用hdfs fsck / -delete删除损坏文件(谨慎操作)
2.2 副本不足问题架构
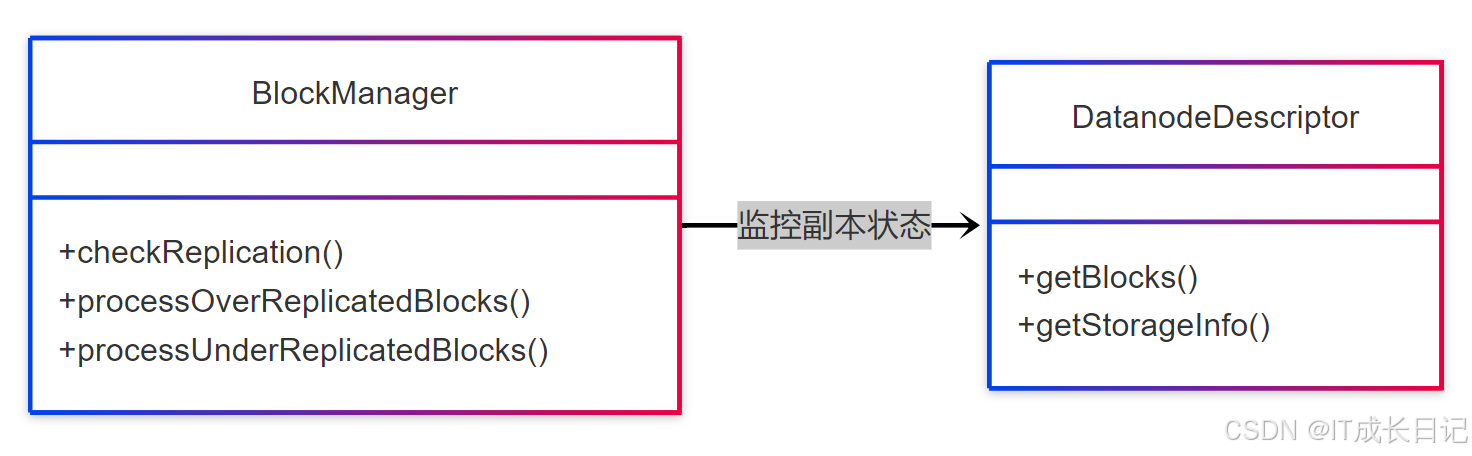
典型解决方案:
- 网络分区:检查dfs.namenode.replication.work.multiplier.per.iteration值
- 磁盘满:清理/hadoop/hdfs/data/current/BP-*下的临时文件
- 配置错误:验证dfs.replication和dfs.namenode.replication.min值
2.3 DataNode无法启动诊断
常见错误码:
- DISK_ERROR:检查dfs.datanode.data.dir权限
- INVALID_VERSION:统一集群Hadoop版本
- NO_SPACE_LEFT:调整dfs.datanode.du.reserved配置
3 日志分析实战技巧
3.1 NameNode日志分析框架
关键日志位置:
- $HADOOP_HOME/logs/hadoop-*-namenode-*.log
- 重点关注WARN和ERROR级别日志
- GC日志单独分析:-XX:+PrintGCDetails
3.2 DataNode日志分析流程
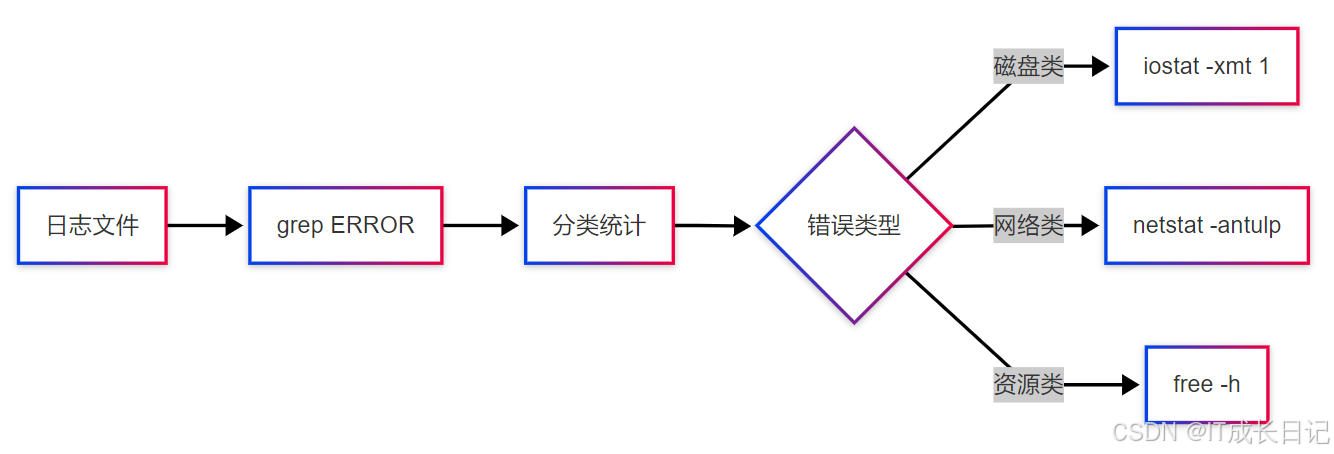
- 实用命令组合
# 实时监控关键错误
tail -F hdfs.log | grep -E "ERROR|WARN|Exception" # 统计错误出现频率
awk '/ERROR/{print $5}' hdfs.log | sort | uniq -c | sort -nr4.1 实战案例分析
4.2 集群性能突然下降

根本原因:
- NameNode老年代GC停顿达到15秒
- 解决方案:
<!-- 调整NN JVM参数 -->
<property><name>hadoop_namenode_opts</name><value>-XX:+UseG1GC -XX:MaxGCPauseMillis=200</value>
</property>4.2 数据读写异常处理

- 定位损坏块
hdfs fsck /user -files -blocks -locations- 隔离问题节点
hdfs dfsadmin -refreshNodes- 手动修复元数据
hdfs debug recoverLease -path /path -retries 55 预防性维护建议
5.1 健康检查清单

- 自动化脚本示例
#!/bin/bash# HDFS健康检查脚本
# 功能:检查HDFS副本不足的块并告警
# 作者:YourName
# 版本:1.1
# 日期:$(date +%Y-%m-%d)# 配置项
LOG_FILE="/var/log/hdfs_check.log"
THRESHOLD=0 # 告警阈值,可以设置为大于0的值
HDFS_PATH="/" # 默认检查根目录# 初始化日志
init_log() {local log_dir=$(dirname "$LOG_FILE")[ ! -d "$log_dir" ] && mkdir -p "$log_dir"echo "===== $(date '+%Y-%m-%d %H:%M:%S') 开始HDFS检查 =====" >> "$LOG_FILE"
}# 记录日志
log() {local level=$1local msg=$2echo "[$(date '+%H:%M:%S')] [$level] $msg" >> "$LOG_FILE"[ "$level" = "ERROR" ] && echo "$msg" >&2 # 错误信息输出到stderr
}# 检查HDFS状态
check_hdfs() {log "INFO" "正在检查HDFS路径: $HDFS_PATH"# 检查hdfs命令是否可用if ! command -v hdfs &> /dev/null; thenlog "ERROR" "hdfs命令未找到,请检查Hadoop环境配置"return 1fi# 执行fsck检查local fsck_outputif ! fsck_output=$(hdfs fsck "$HDFS_PATH" -files -blocks -locations 2>&1); thenlog "ERROR" "HDFS检查失败: $fsck_output"return 1fi# 提取副本不足块数量local under_replicated=$(echo "$fsck_output" | grep 'Under replicated' | awk '{print $3}')if [ -z "$under_replicated" ]; thenlog "WARN" "未能获取副本状态,可能是HDFS版本差异"return 2filog "INFO" "检查完成,发现 $under_replicated 个副本不足块"echo "$under_replicated"
}# 主函数
main() {init_log# 检查参数if [ $# -gt 0 ]; thenHDFS_PATH="$1"log "INFO" "使用自定义检查路径: $HDFS_PATH"fi# 执行检查local under_replicated=$(check_hdfs)local exit_code=$?# 处理结果if [ $exit_code -eq 0 ]; thenif [ "$under_replicated" -gt "$THRESHOLD" ]; thenlocal alert_msg="警告:存在 $under_replicated 个副本不足块(超过阈值 $THRESHOLD)"log "WARN" "$alert_msg"# 这里可以添加邮件告警逻辑# 例如:send_alert "$alert_msg"echo "$alert_msg" # 输出到控制台exit 1elselog "INFO" "副本状态正常"echo "副本状态正常,发现 $under_replicated 个副本不足块"exit 0fielseexit $exit_codefi
}# 执行主函数(带参数传递)
main "$@"5.2 关键监控指标
推荐监控项:
- MissingBlocks
- PendingReplicationBlocks
- TotalLoad
- HeapMemoryUsage
6 总结
80%的问题可以通过日志分析解决,15%需要配置调整,剩下5%可能需要社区支持。