DSA数据结构与算法 6
查找技术(Searching Techniques)
查找简介
在计算机科学中,“查找”指的是在某个集合或序列中寻找特定元素的过程。这个过程可以是成功的,也可以是失败的:
- 若目标元素存在于集合中,我们称之为“查找成功”,并返回它在集合中的位置;
- 若元素不存在,则称为“查找失败”。
查找是数据处理中的基本操作之一,几乎出现在所有软件系统的核心逻辑中。比如搜索联系人、检索图书、匹配登录密码等,背后都离不开查找算法。
而不同的查找算法之间最大的差异,通常体现在“查找的效率”上。这个效率,很大程度上依赖于数据本身的“排列方式”——是否已排序。因此,我们在选择查找方法时,必须考虑数据的特征。
本章将介绍两种最基础的查找技术:
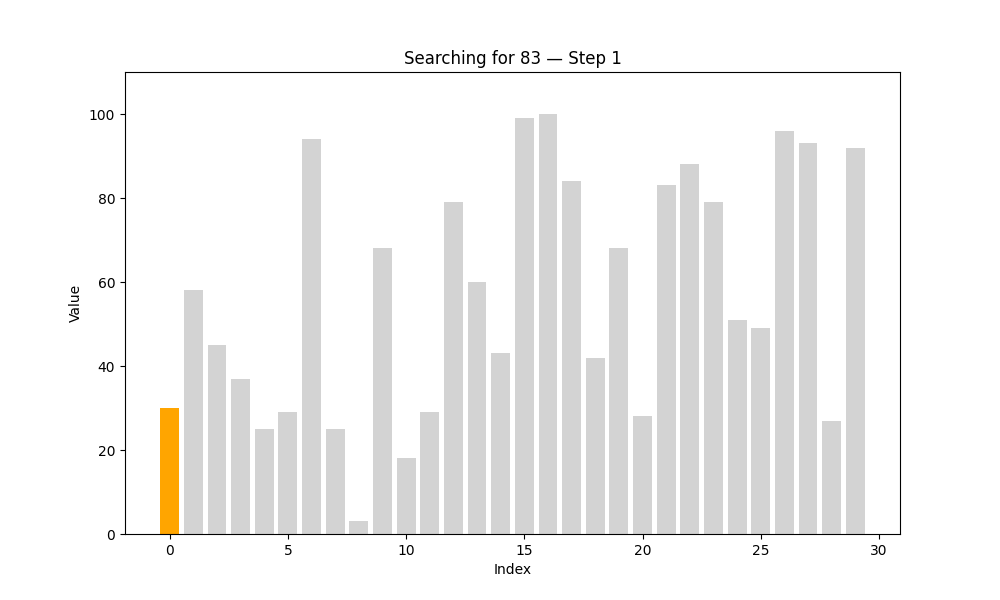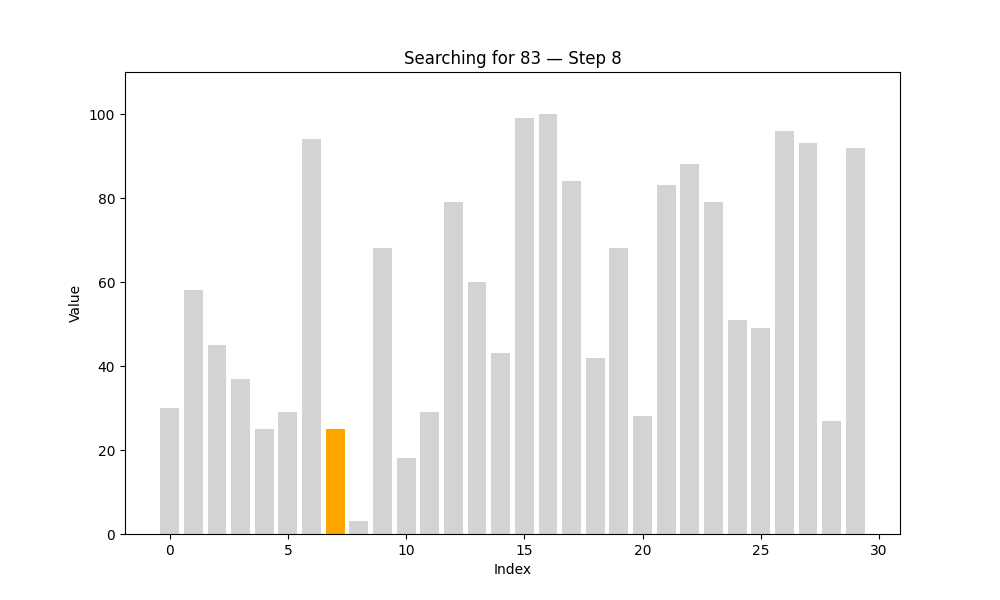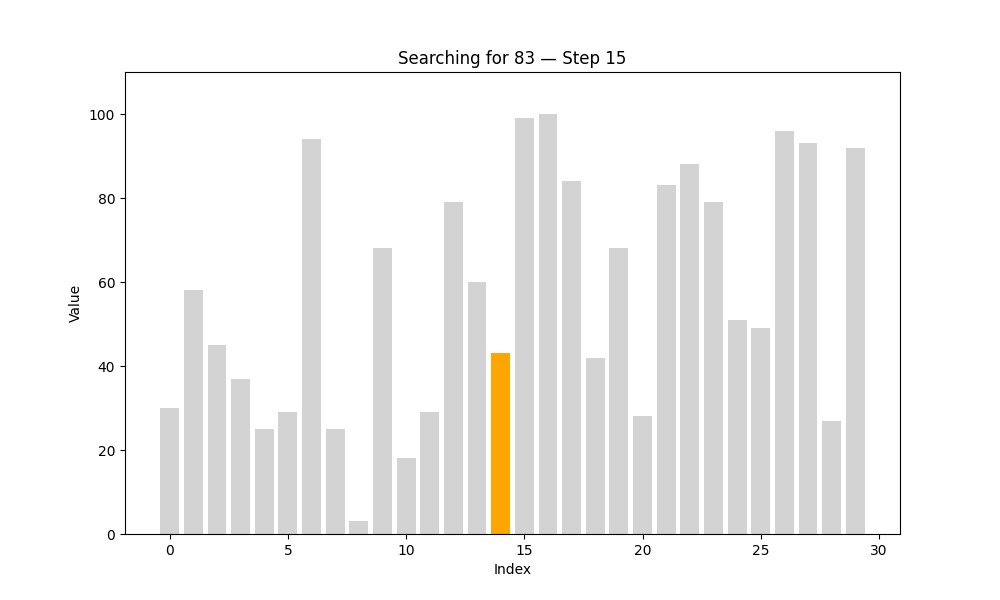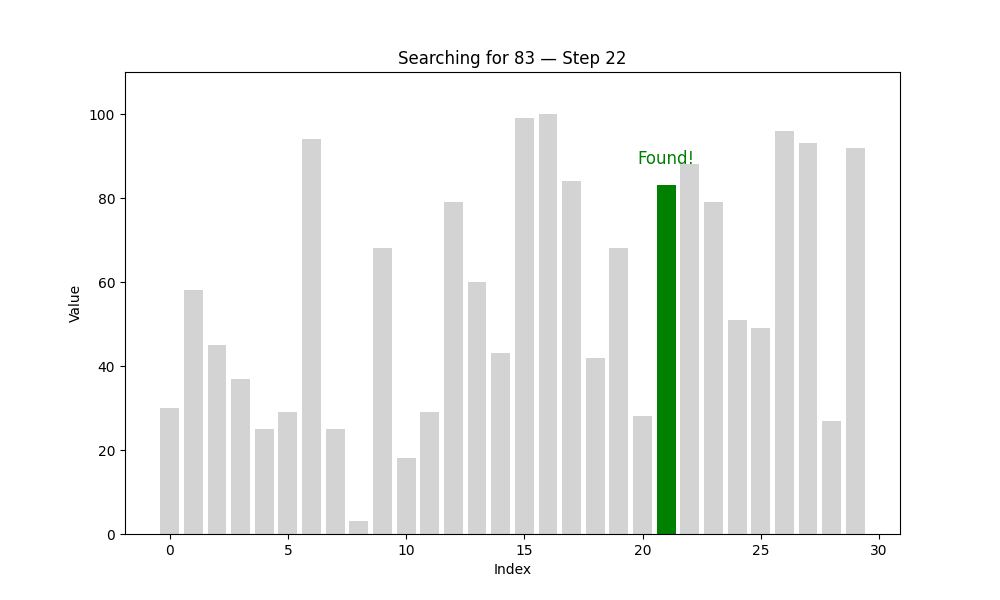
1. 线性查找(Linear Search)
又名“顺序查找”,是最直观的查找方式。算法从第一个元素开始,依次与目标值进行比较,直到找到为止,或遍历完所有元素。
这种方法的优势是实现简单,不要求数据有序;缺点是效率较低,特别是在数据量大的时候。
一个类比:想象你正在翻找一个装满扑克牌的盒子,想找一张红桃 7。如果这些牌是杂乱无章地放着的,你只能一张张翻阅,直到找到为止——这就是线性查找的过程。
def linear_search(arr, target):steps = [] # 每一步的状态for i in range(len(arr)):status = {'array': arr.copy(),'index': i,'found': arr[i] == target}steps.append(status)if arr[i] == target:break # 找到目标值就提前退出return steps
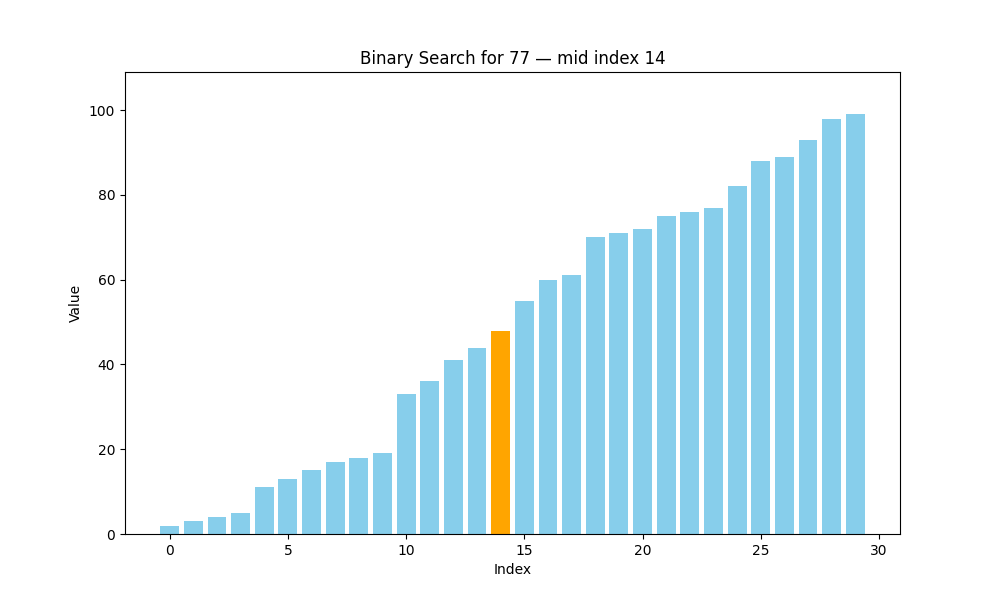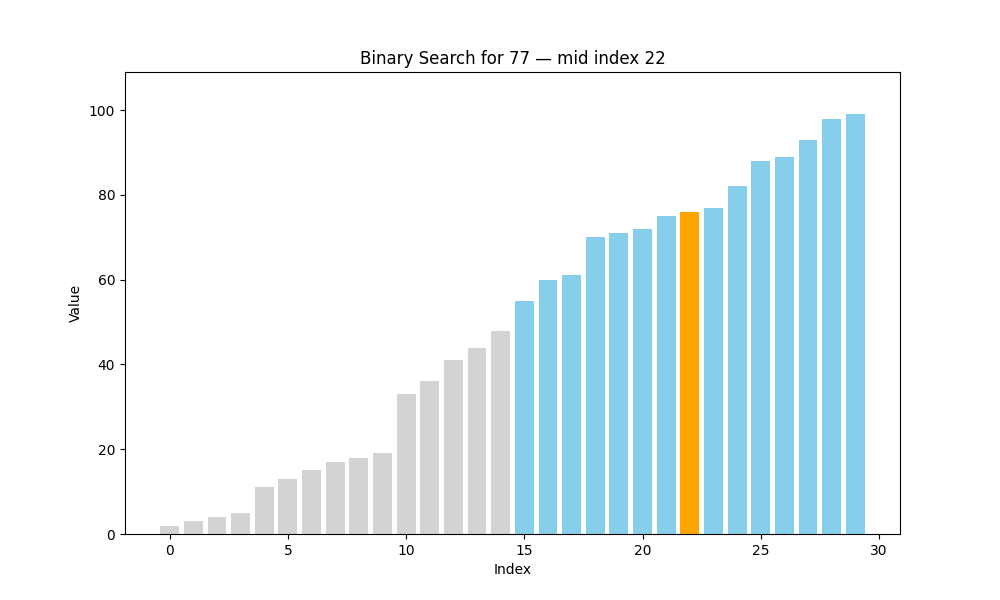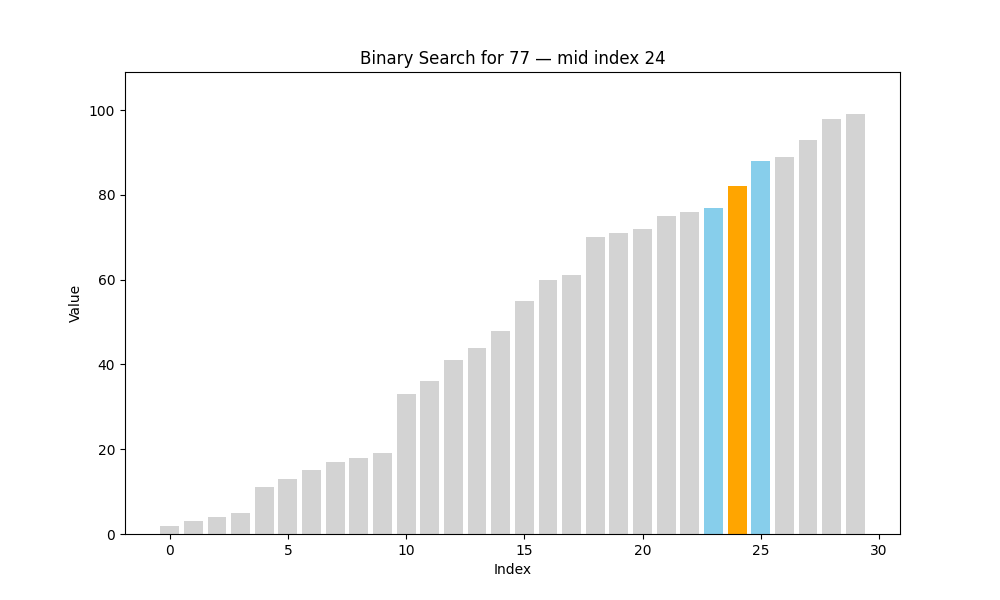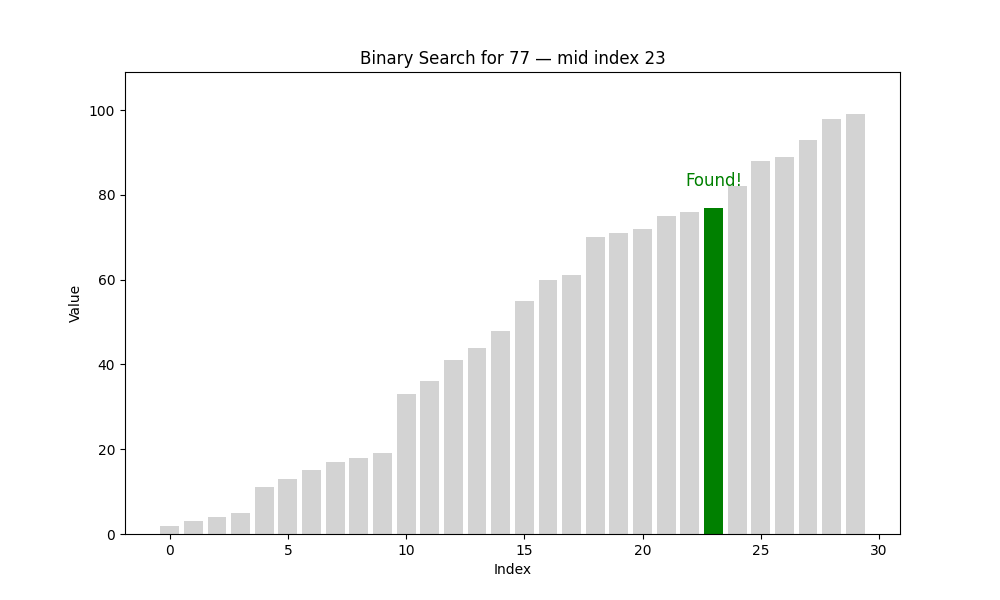
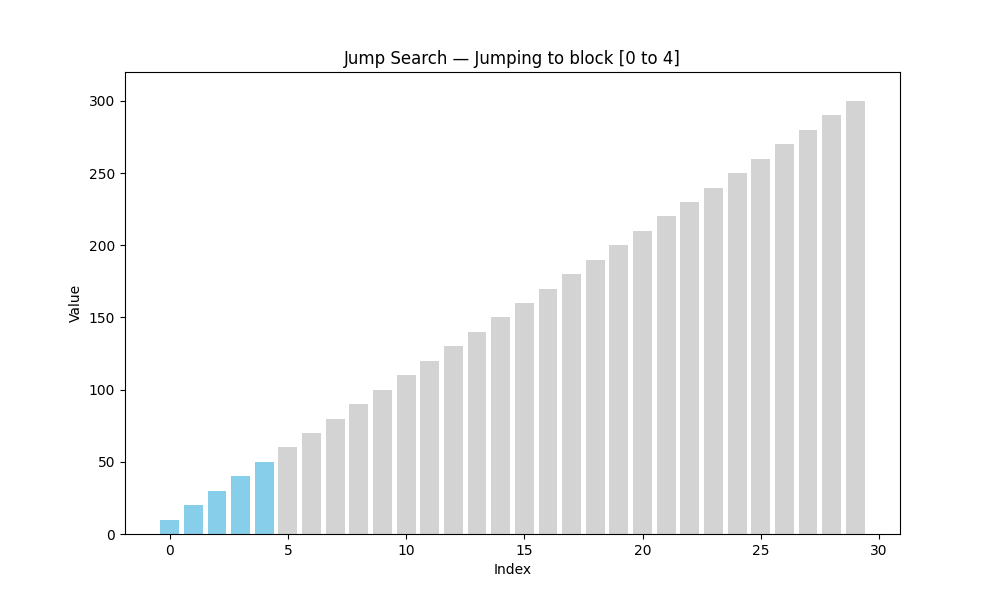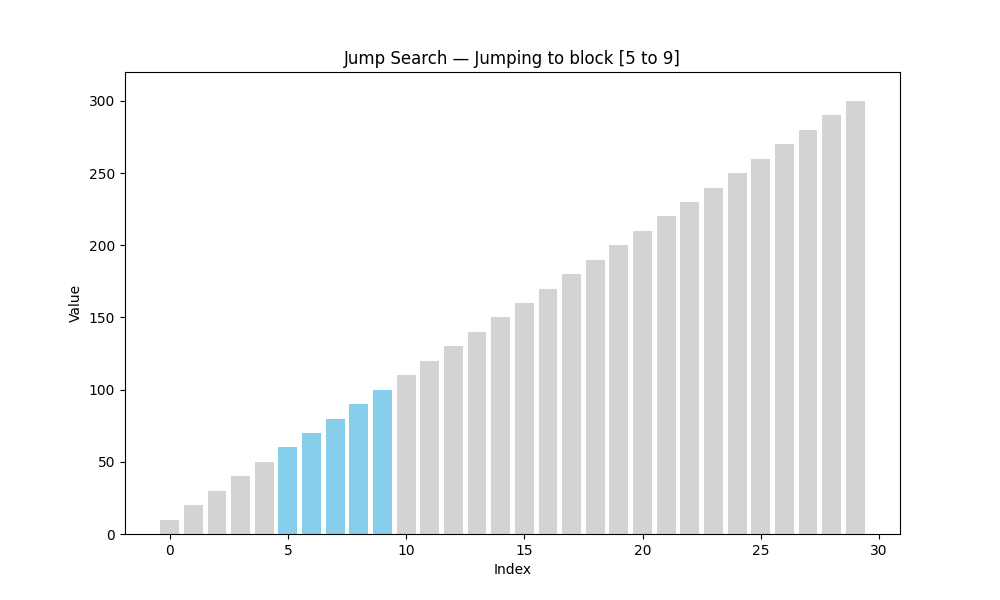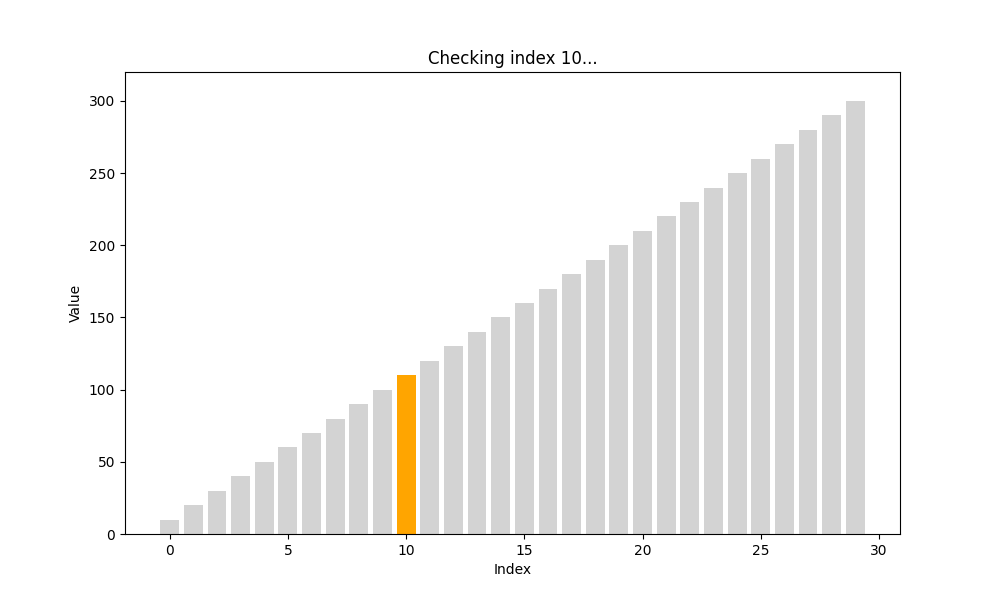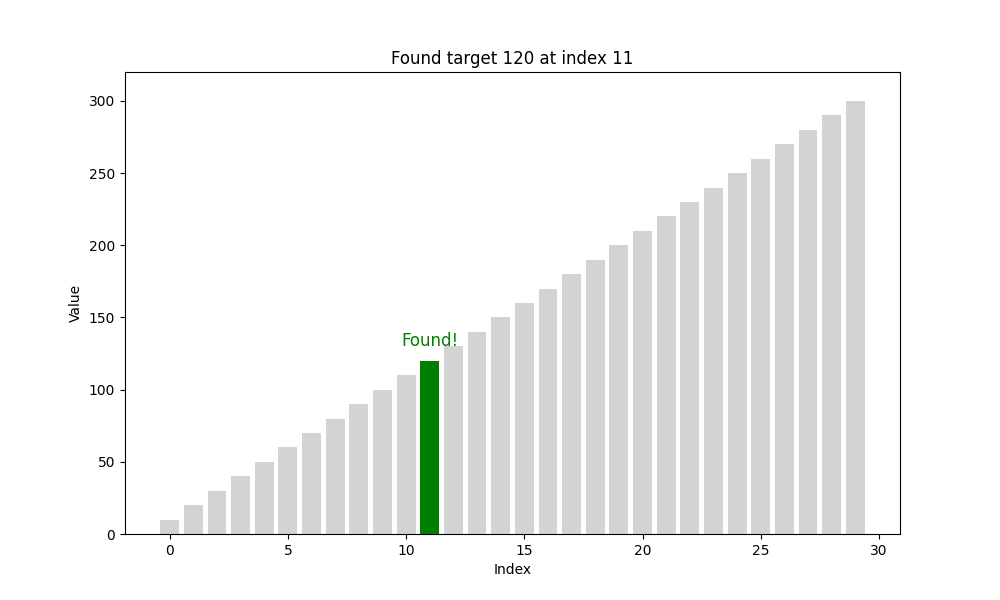
二分查找(Binary Search)
二分查找是一种高效的查找方法,但它有一个前提条件:待查找的列表必须是有序的。也就是说,在使用二分查找之前,我们要确保数据已经按照升序或降序排列好,否则该算法将无法正常工作。
✦ 二分查找的核心思想:分而治之(Divide and Conquer)
具体过程如下:
- 将数组从中间分成两部分;
- 将目标值与中间元素进行比较:
- 如果相等,则查找成功,返回该位置;
- 如果目标值小于中间元素,说明目标在左半部分;
- 如果目标值大于中间元素,说明目标在右半部分;
- 仅在可能存在目标值的一半继续查找;
- 重复上述步骤,直到找到目标或范围为空为止。
这种方法的效率极高:每次查找操作都将问题规模减半,时间复杂度为 O ( log 2 n ) O(\log_2 n) O(log2n),远优于线性查找的 O ( n ) O(n) O(n),尤其在数据量较大时优势更加明显。
def binary_search(arr, target):steps = []low = 0high = len(arr) - 1while low <= high:mid = (low + high) // 2step = {'array': arr.copy(),'low': low,'high': high,'mid': mid,'found': arr[mid] == target}steps.append(step)if arr[mid] == target:breakelif arr[mid] < target:low = mid + 1else:high = mid - 1return steps
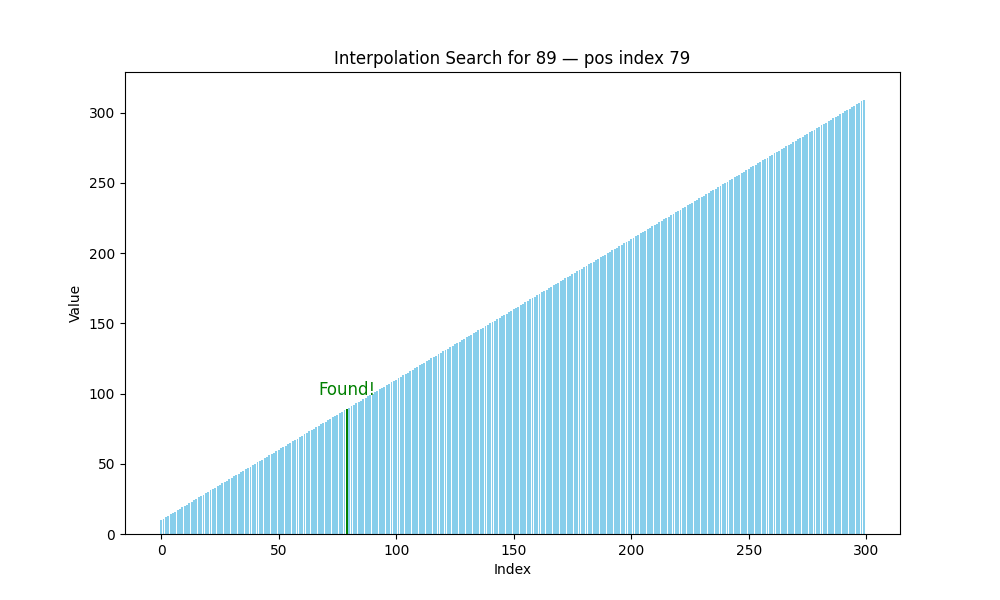
插值查找(Interpolation Search)
- 适用条件: 数据必须是有序且分布均匀
- 核心思想: 预测目标值可能出现的位置,而不是死板地取中间值
m i d = l o w + ( t a r g e t − a r r [ l o w ] ) ⋅ ( h i g h − l o w ) a r r [ h i g h ] − a r r [ l o w ] mid = low + \frac{(target - arr[low]) \cdot (high - low)}{arr[high] - arr[low]} mid=low+arr[high]−arr[low](target−arr[low])⋅(high−low)
- 时间复杂度:
- 最好: O ( log log n ) O(\log \log n) O(loglogn)
- 最坏: O ( n ) O(n) O(n)(分布极度不均)
跳跃查找(Jump Search)
- 适用条件: 有序数组
- 核心思想: 以固定步长(如 n \sqrt{n} n)跳跃前进,找到目标所在区间后回退线性查找
- 时间复杂度: O ( n ) O(\sqrt{n}) O(n)
哈希查找(Hash Search)
- 适用条件: 查找速度要求极高,数据量大,结构可以牺牲顺序
- 核心思想: 使用哈希函数将关键字映射到数组中的某个索引位置
- 优势: 插入和查找时间复杂度通常为 O ( 1 ) O(1) O(1)
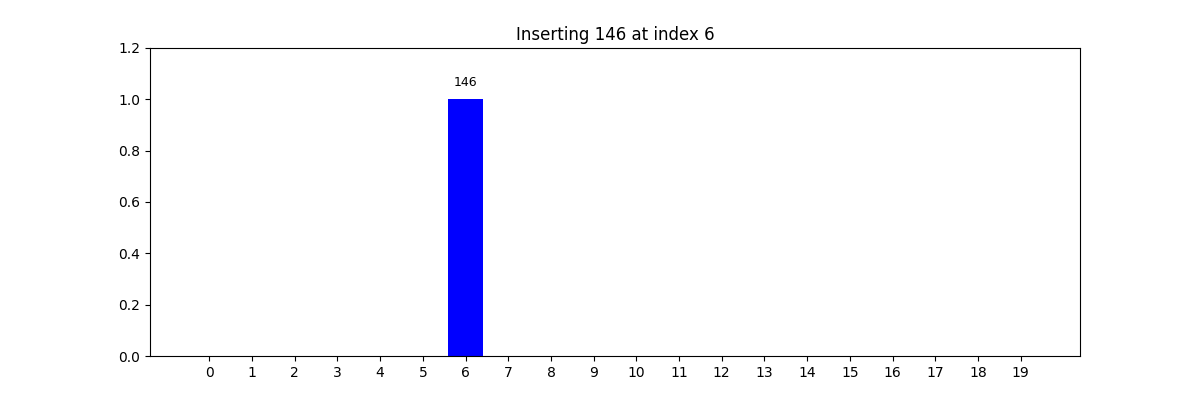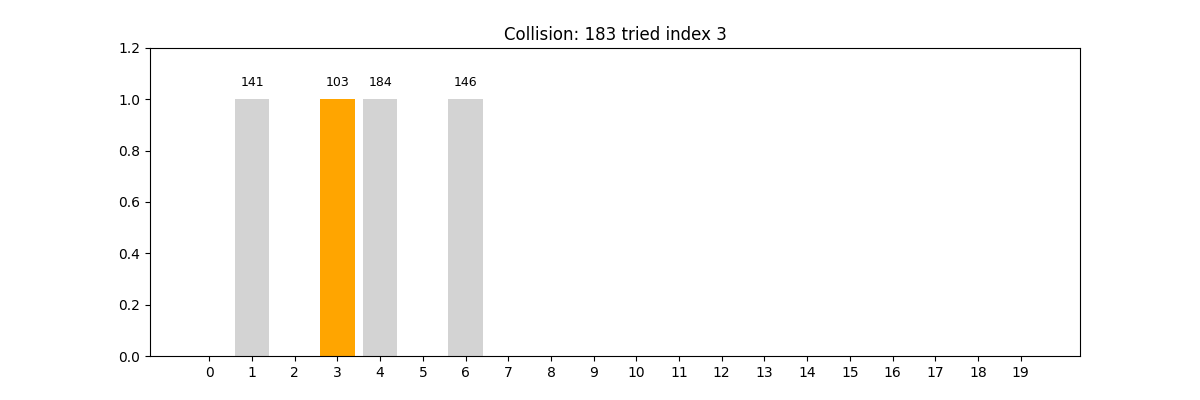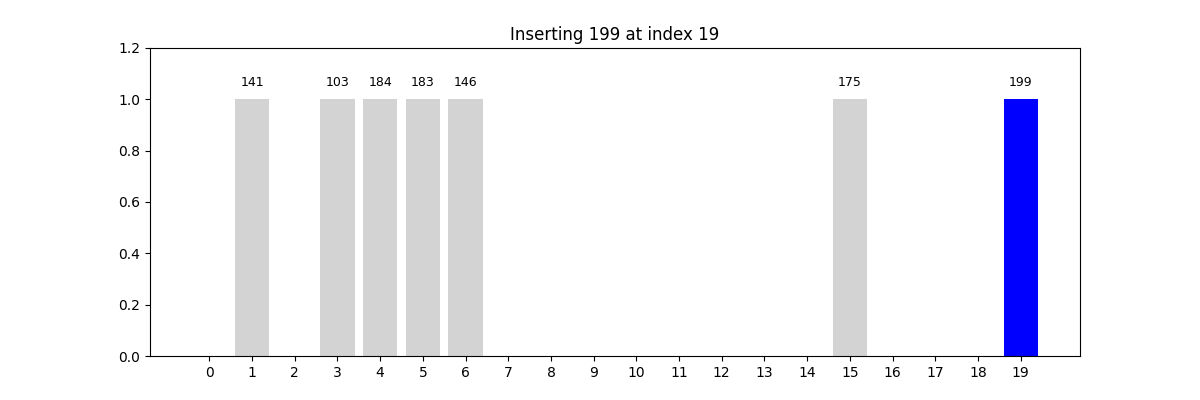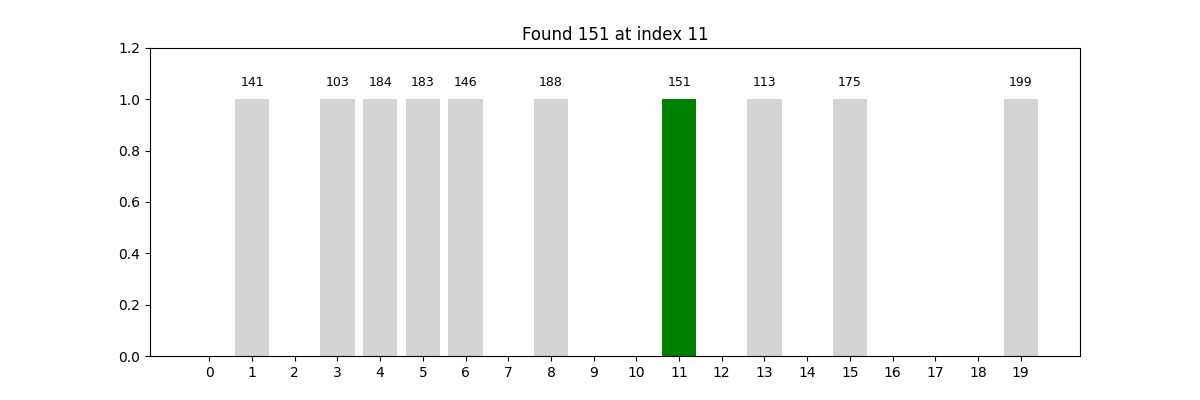
- 挑战: 哈希冲突(如链地址法、开放定址法)
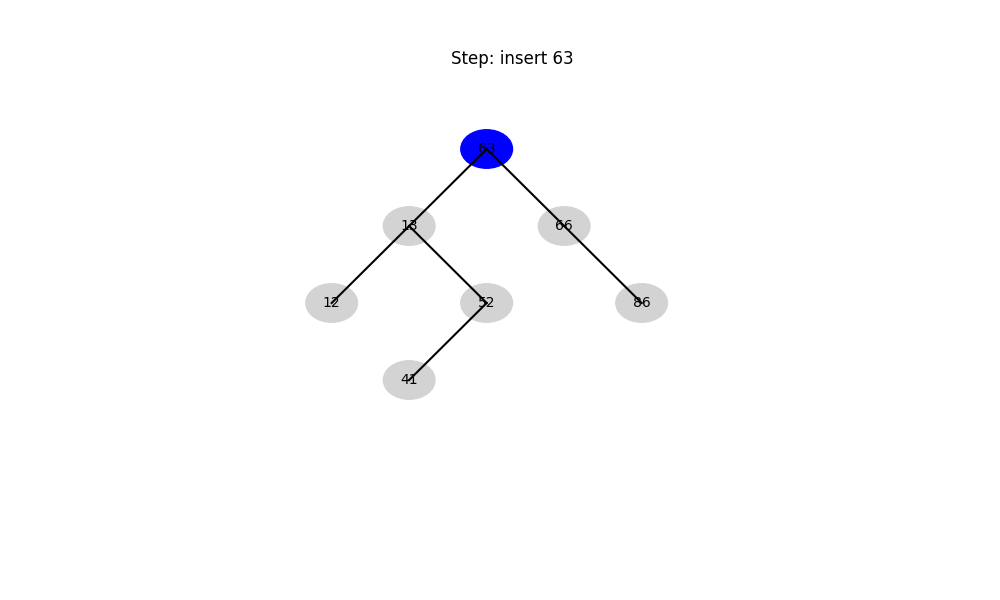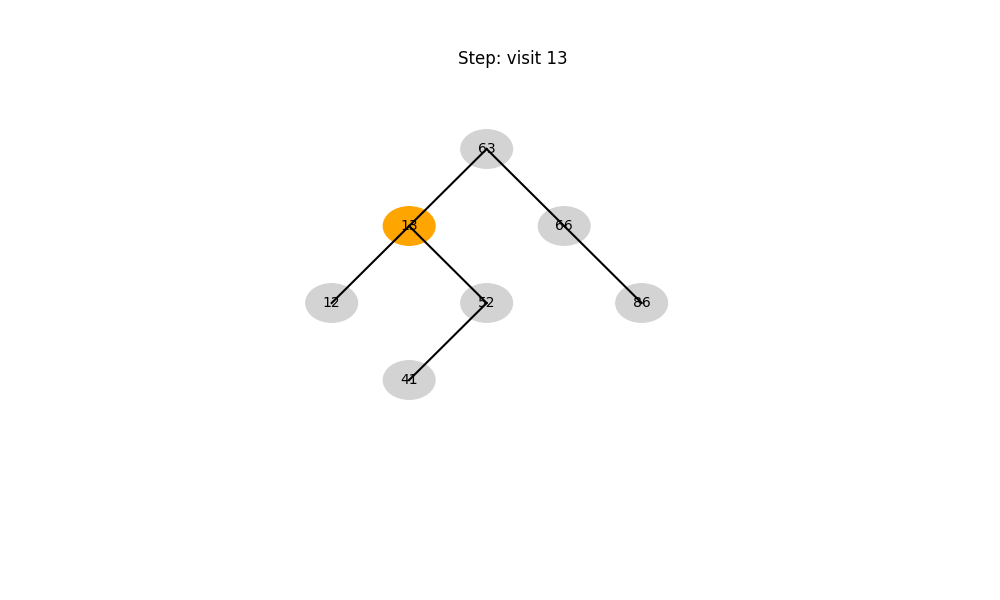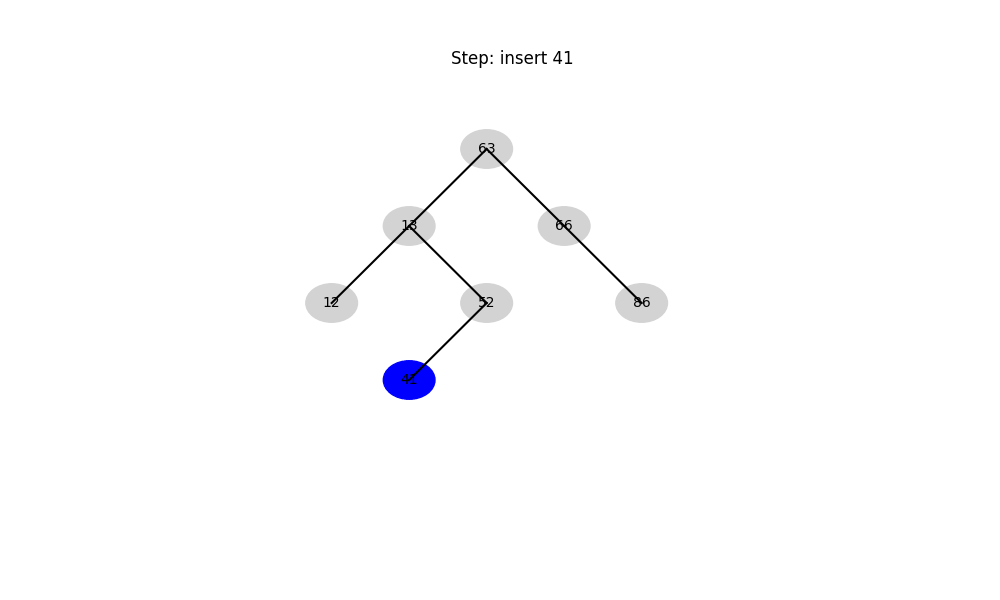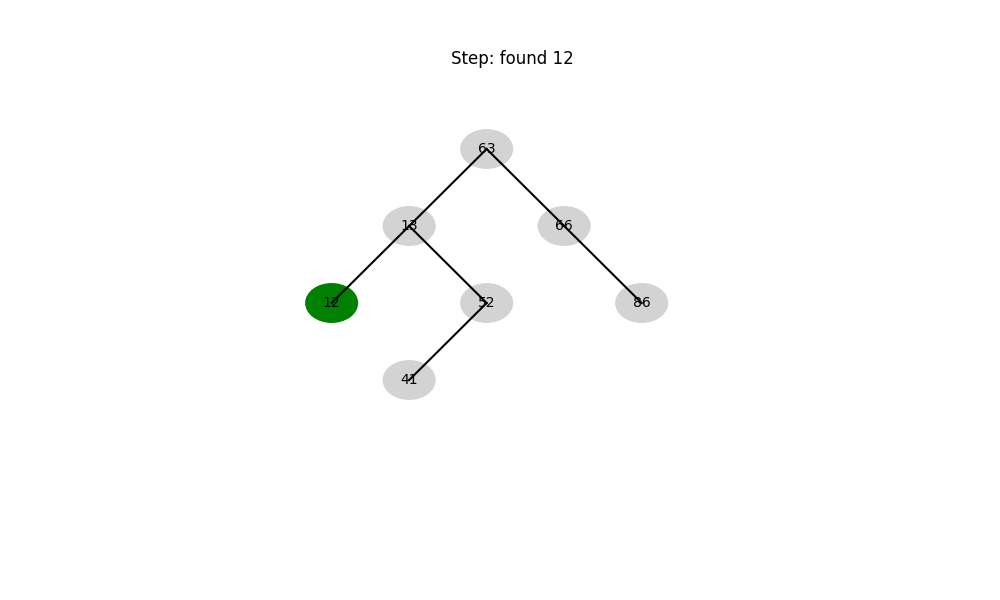
二叉搜索树(Binary Search Tree, BST)
- 结构性质: 左子树 < 根 < 右子树
- 时间复杂度:
- 平均: O ( log n ) O(\log n) O(logn)
- 最坏: O ( n ) O(n) O(n)(退化成链表)
平衡二叉搜索树(AVL 树、红黑树等)
- 特性: 自动保持“树的高度”平衡,防止性能退化
- 优势: 所有操作最坏时间复杂度为 O ( log n ) O(\log n) O(logn)
- 适用: 高频插入+查找操作,如操作系统调度、缓存结构
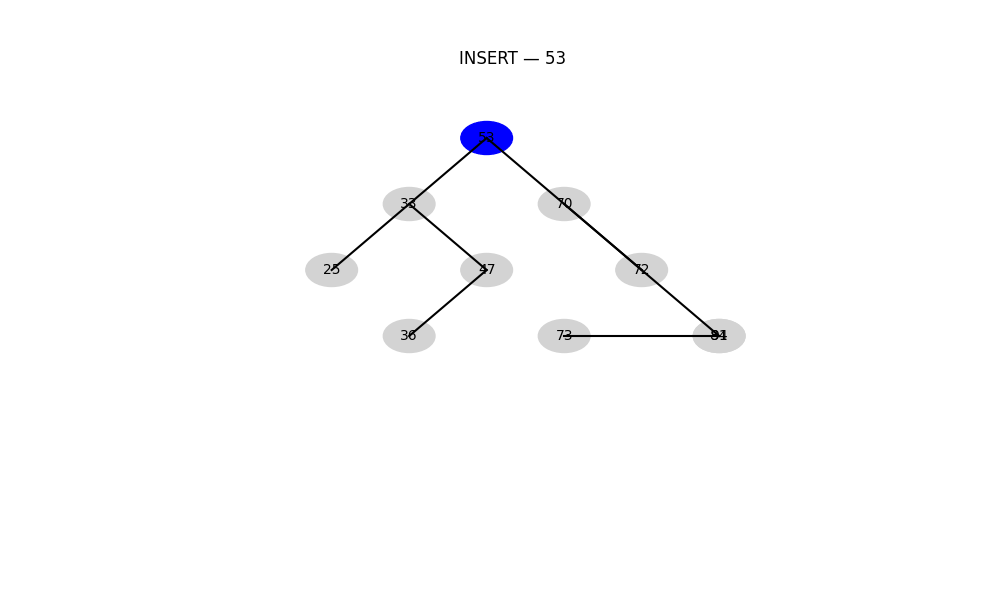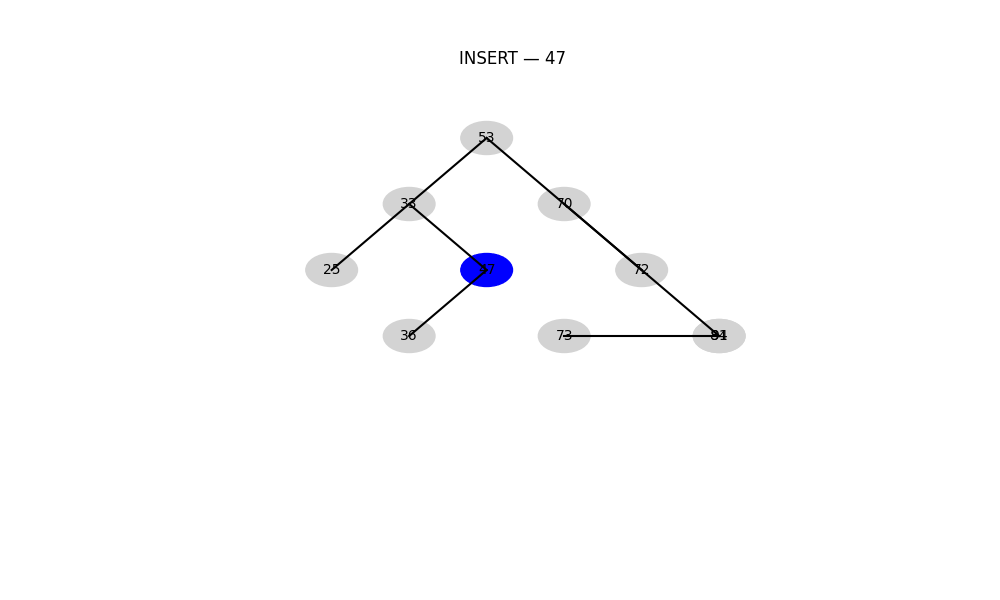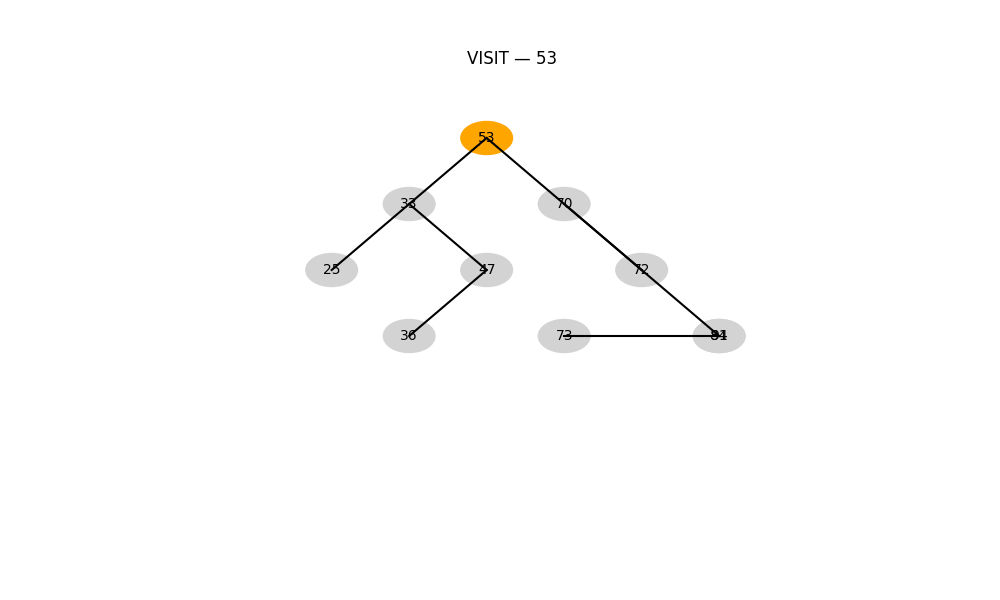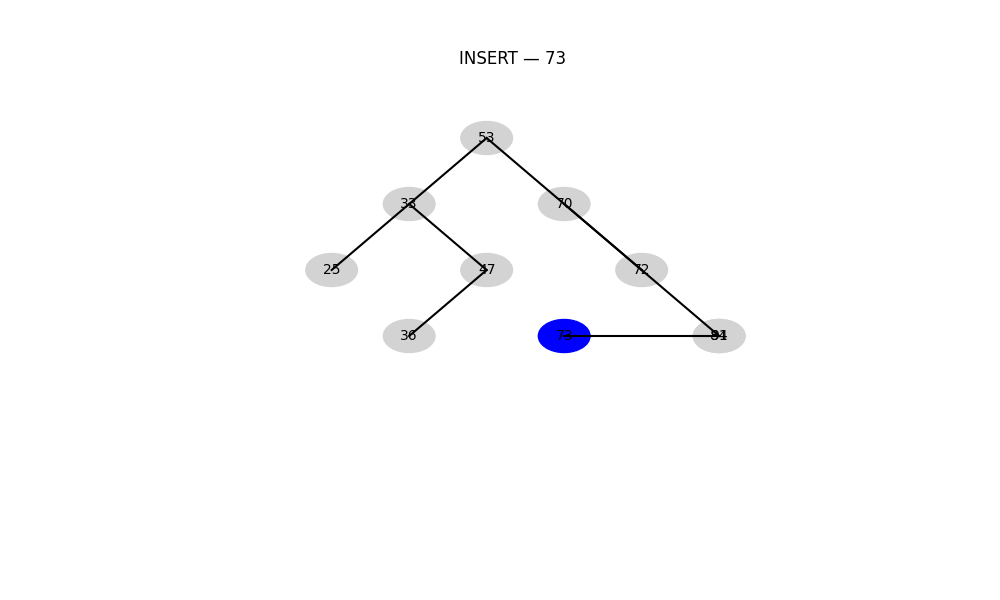
B 树 / B+ 树
- 用途: 用于数据库、文件系统等对磁盘IO优化要求极高的场景
- 特点:
- 多路搜索,不是二叉结构
- 每个节点包含多个关键字
- 优势: 能减少磁盘访问次数,支持批量范围查找
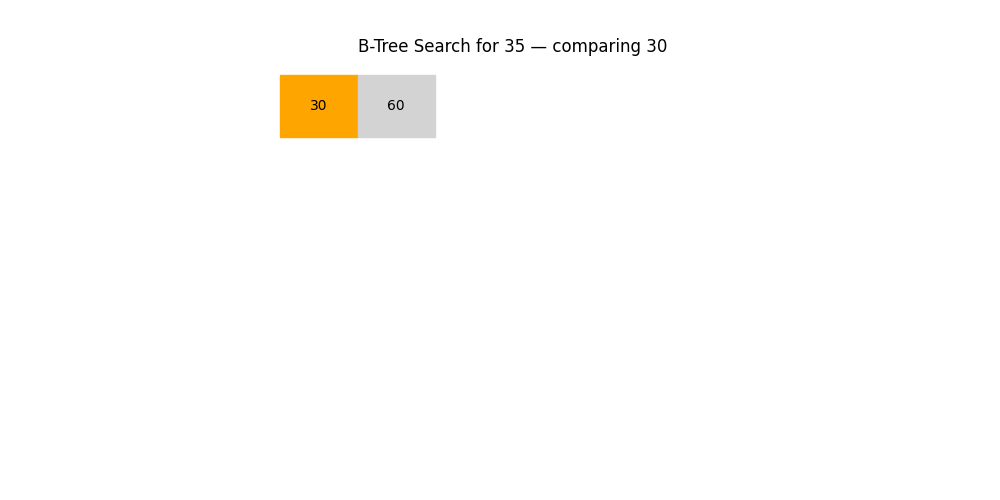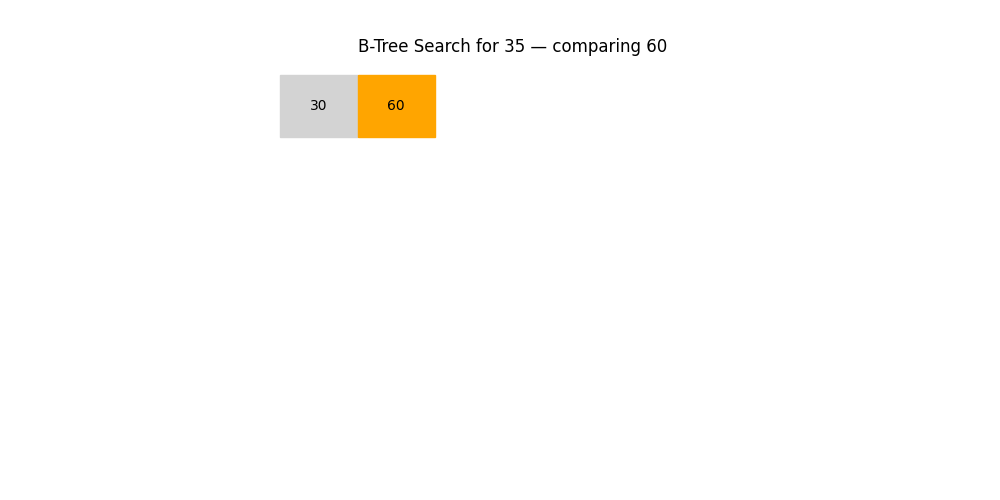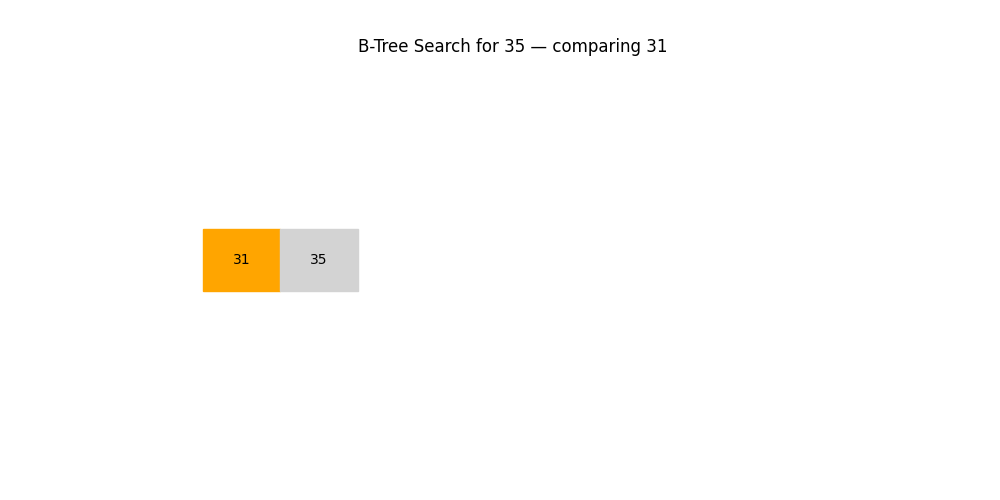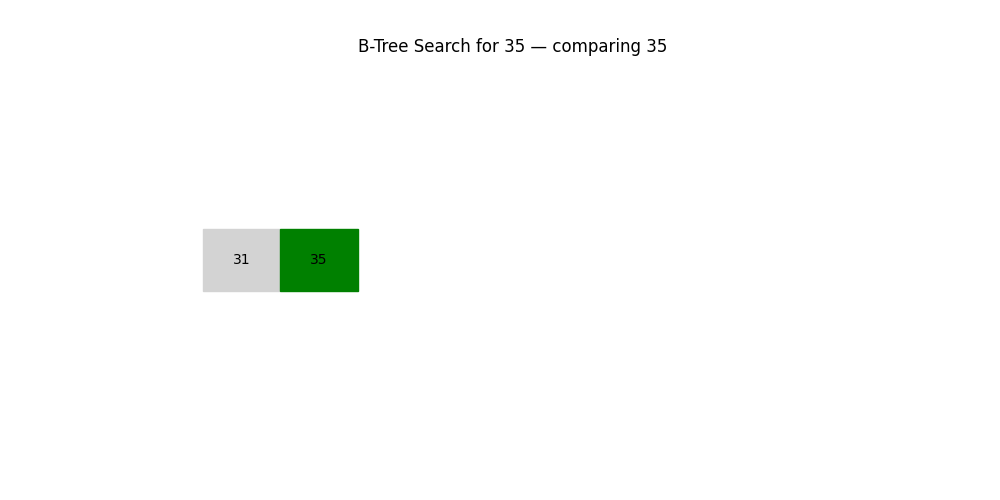
深度优先搜索(DFS)与广度优先搜索(BFS)
- 应用场景: 图结构查找、路径规划、社交网络分析等
- 特点:
- DFS:适合探索所有路径(回溯)
- BFS:适合找最短路径或分层结构
指数查找(Exponential Search)
- 应用场景: 无法直接知道数据规模,如“无限数组”
- 过程:
- 快速扩大查找范围(1, 2, 4, 8…)
- 找到目标值所在的范围后使用二分查找
- 时间复杂度: O ( log i ) O(\log i) O(logi),其中 i i i 为目标位置