Kubernetes控制平面组件:调度器Scheduler(一)
云原生学习路线导航页(持续更新中)
- kubernetes学习系列快捷链接
- Kubernetes架构原则和对象设计(一)
- Kubernetes架构原则和对象设计(二)
- Kubernetes架构原则和对象设计(三)
- Kubernetes控制平面组件:etcd(一)
- Kubernetes控制平面组件:etcd(二)
- Kubernetes控制平面组件:API Server详解(一)
- Kubernetes控制平面组件:API Server详解(二)
- Kubernetes控制平面组件:调度器Scheduler(一)
- Kubernetes控制平面组件:调度器Scheduler(二)
本文是kubernetes的控制面组件调度器Scheduler第一篇,首先介绍了kubernetes调度器的基础、核心原理,然后分别介绍了调度过程的2个阶段:Predicates&Priority,之后详细介绍了Pod资源配置基于cgroups的底层原理,以及pod资源对kubernetes调度器的作用,最后还给出了kube-scheduler源码分析的关键点
- 希望大家多多 点赞 关注 评论 收藏,作者会更有动力继续编写技术文章
1.kube-scheduler基础
1.1.kube-scheduler介绍
1.1.1.scheduler是什么

- scheduler是什么
- Kubernetes调度器(kube-scheduler)是集群资源调度的核心组件,负责将未绑定节点的Pod分配到满足资源需求和策略约束的Worker节点上。
- scheduler核心功能
- 资源优化:基于CPU、内存等资源请求,均衡节点负载,避免局部热点。
- 策略执行:支持亲和性(Affinity)、反亲和性(Anti-Affinity)、污点容忍(Taints/Tolerations)等规则。
- 高可用性:通过分布式调度避免单点故障,支持多调度器共存。
- 扩展性:通过插件化架构(Scheduling Framework)支持自定义调度逻辑。
1.1.2.调度器如何标记pod该调度到哪个节点?
- 通过Pod的NodeName字段。
- 调度器监听所有没有设置NodeName的pod,然后通过一系列调度算法计算出调度到哪个Node上,然后将Node写入pod的NodeName字段
- 后续由对应Node上的kubelet负责将Pod容器拉起来
1.1.3.scheduler本质也是一个生产者-消费者模型
- 生产者:scheduler通过 list-informer 机制监听api-server的pod事件,将未调度的pod的name放入一个队列中,等待调度
- 消费者:scheduler还包括一些worker,监听队列,取出podName,对相应的pod进行调度
1.1.4.调度需要考虑什么因素
- 优先级:保证高优先级优先调度,以及资源不足时是否可抢占…
- 公平性:同一优先级下,如何保证公平性,比如先进先出
- 资源高效利用:资源可以分成 可压缩、不可压缩 两类,调度的时候需要考虑多元资源调度,比如同时存在多个节点符合资源条件时,怎么调度能保证资源使用率更高
- Qos:考虑pod调度在node上的服务质量
- 亲和、反亲和性:比如两个相关的服务,被调度在同一台机器,在发生调用的时候就不是网络调用,不会走到物理网卡,效率和稳定性都会更高
- 数据本地化:大多是在大数据领域出现,大数据领域大都有很多待处理的文件,那么调度的时候就有两种情况:1)pod启动后网络传输文件;2)直接调度到存在该文件的那几台机器上,把进程/作业传过去,避免传输大量数据,作业找数据
- 内部负载干扰
- deadlines
1.2.kube-scheduler核心原理

- 声明式调度:基于Pod的资源请求和策略定义,而非命令式指令。
- 调度队列管理:
- Active Queue:存储待调度Pod,按优先级排序(如Pod优先级类)。
- Backoff Queue:存放调度失败的Pod,采用指数退避机制重试。
- 调度缓存(Scheduler Cache):
- 维护集群节点和Pod的实时状态,减少对API Server的直接访问。
- 调度流程:
- 预选(Predicates):过滤不满足资源请求、端口冲突或策略限制的节点。
- 优选(Priorities):计算节点得分(如资源利用率、亲和性权重),选择最优节点。
- 绑定(Binding):将Pod与节点绑定,触发kubelet启动容器。
- 插件化架构:通过Scheduling Framework定义扩展点(如predicate、priority都允许自定义调度策略),支持按需扩展调度逻辑。
1.3.与其他调度系统的对比
| 系统 | 核心差异 |
|---|---|
| Docker Swarm | 仅支持简单策略(如节点标签),缺乏K8s的插件化扩展能力。 |
| Apache Mesos | 通用资源调度框架,支持非容器负载,但容器生态和调度策略灵活性不及K8s。 |
| OpenShift | 基于K8s增强企业级功能(如安全策略、CI/CD集成),但核心调度逻辑与K8s一致。 |
| Nomad | 支持多类型工作负载(容器、VM),但缺乏K8s的丰富调度插件和生态系统。 |
2.kube-scheduler调度计算:Predicate阶段
2.1.Predicates 工作原理
- Predicates阶段包含很多Plugin插件,用于过滤不满足条件的node,每运行完一些Plugin,满足条件的Node就会越少。
- 最开始输入为All Nodes,所有插件运行完成,最终剩下的就是满足条件的 Node List
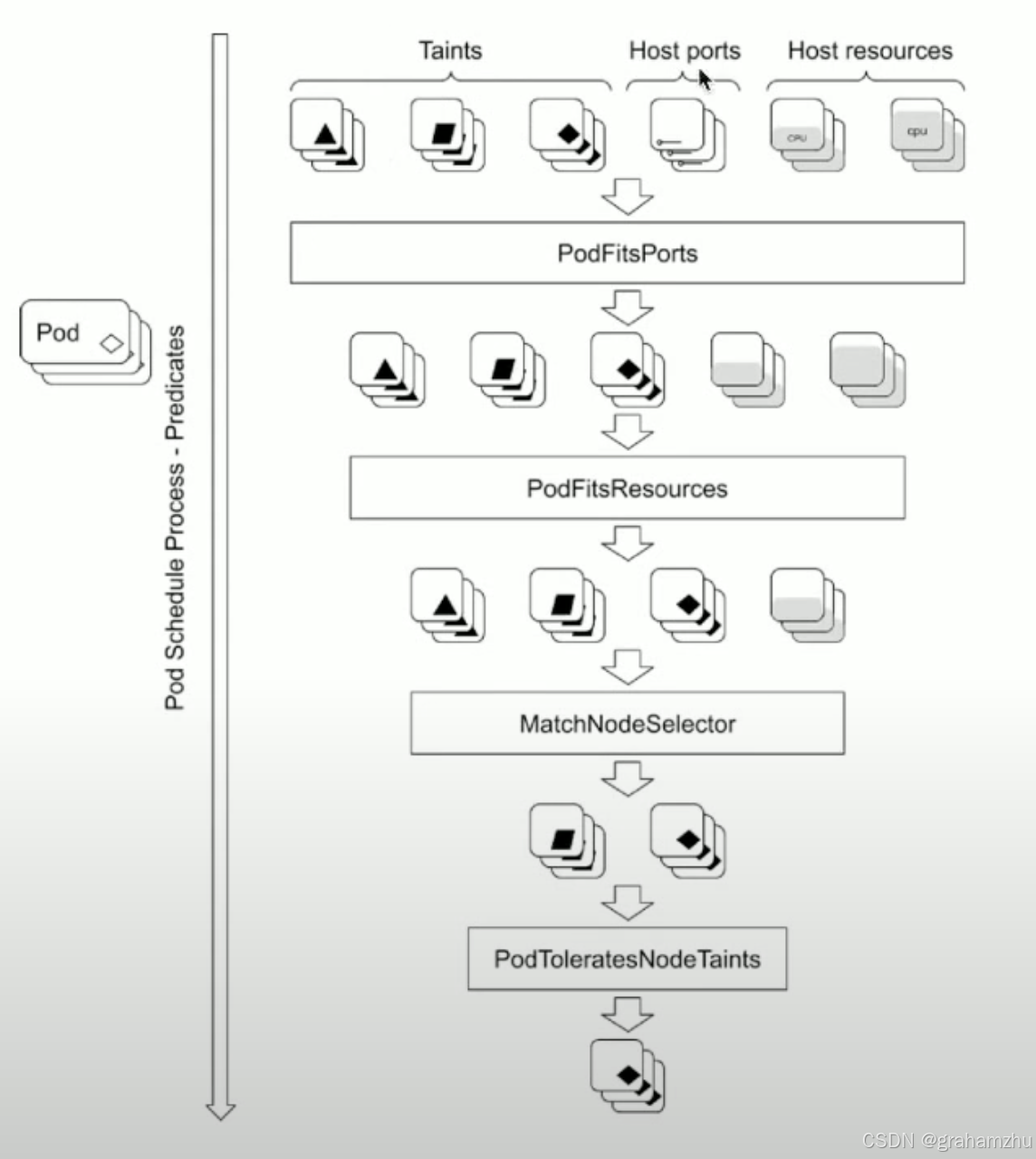
2.2.Predicates 常见 Plugins
- kube-scheduler是插件化设计,拥有很多Predicate插件
- 这里仅列出一些常用的调度策略,实际上还有很多其他的,另外也支持自定义调度predicates策略


2.2.1.PodFitsHostPorts
- 功能:检查候选节点是否存在 HostPort 端口冲突。
- 原理:遍历节点上所有已绑定
hostPort的 Pod,若当前 Pod 声明的hostPort已被占用,则过滤该节点。 - 场景:适用于使用
hostNetwork: true的 Pod,避免端口冲突(如 Nginx 监听 80 端口)。
2.2.2.PodFitsPorts
- 功能:与
PodFitsHostPorts功能相同,可能是旧版本别名或笔误。 - 注意:实际调度器中无此插件,应为
PodFitsHostPorts的重复描述,建议以PodFitsHostPorts为准。
2.2.3.PodFitsResources
- 功能:验证节点 资源是否充足(CPU、内存、GPU、Pod 配额等)。
- 原理:比较节点剩余资源与 Pod 的
requests,若满足以下条件则通过: - 节点可分配资源 ≥ Pod 请求资源。
- 节点 Pod 数量未超过
PodPerCore或MaxPods限制。 - 公式:
节点可分配资源 = 节点总资源 - 已分配资源 - 系统预留资源。
2.2.4. HostName
- 功能:强制 Pod 调度到
pod.Spec.NodeName指定的节点。 - 原理:仅当候选节点的名称与
NodeName完全匹配时通过检查。 - 场景:用于直接指定节点(如 DaemonSet 或运维手动调度)。
2.2.5. MatchNodeSelector
- 功能:校验候选节点 标签是否匹配 Pod 的
nodeSelector或nodeAffinity。 - 原理:检查节点标签是否满足 Pod 的
spec.affinity.nodeAffinity或spec.nodeSelector条件。 - 示例:若 Pod 要求
disk=ssd,则仅调度到有此标签的节点。
2.2.6. NoVolumeZoneConflict
- 功能:确保 Pod 使用的 持久卷(PV)与节点处于同一可用区。
- 原理:检查 PV 的
topology.kubernetes.io/zone标签与节点标签是否一致,避免跨区域访问导致延迟或故障。 - 场景:云环境(如 AWS/Azure)中基于可用区(Availability Zone)的容灾部署。
2.2.7.MatchInterPodAffinity
- 功能:检查 Pod 是否满足与其他 Pod 的亲和性/反亲和性规则。
- 原理:基于
podAffinity和podAntiAffinity配置,验证候选节点上已运行 Pod 的标签是否满足目标 Pod 的拓扑约束(如共置或隔离要求)。
2.2.8.NoDiskConflict
- 功能:检查候选节点是否存在 存储卷冲突(仅限于特定云存储)。
- 原理:验证节点是否已挂载相同存储卷(如 GCE PD、AWS EBS、Ceph RBD、iSCSI),避免多 Pod 同时读写导致数据损坏。
- 限制:仅适用于需要独占访问的块存储类型。
2.2.9.PodToleratesNodeTaints
- 功能:检查 Pod 是否容忍节点的 污点(Taints)。
- 原理:将 Pod 的
tolerations与节点taints列表匹配,若存在匹配的容忍规则则允许调度。 - 场景:控制 Pod 调度到专用节点(如 GPU 节点需容忍
nvidia.com/gpu:NoSchedule)。
2.2.10.CheckNodeMemoryPressure
- 功能:判断 Pod 能否调度到存在 内存压力 的节点。
- 原理:若节点报告
MemoryPressure状态,则仅允许调度Burstable/BestEffortQoS 级别的 Pod(无内存requests限制的 Pod)。
2.2.11.CheckNodeDiskPressure
- 功能:判断 Pod 能否调度到存在 磁盘压力 的节点。
- 原理:若节点报告
DiskPressure状态,则禁止调度新 Pod(系统守护进程 Pod 除外),防止磁盘资源耗尽。
2.2.12.NoVolumeNodeConflict
- 功能:检查节点是否满足 Pod 引用 Volume 的 访问条件。
- 原理:验证节点是否符合 Volume 的
nodeAffinity或访问模式(如ReadWriteOnce要求独占挂载)。 - 示例:本地持久卷(Local PV)需通过节点选择器绑定特定节点。
3.kube-scheduler调度计算:Priority 阶段
3.1.Priority工作原理
- Priority 阶段就是在打分,把经过Predicates阶段过滤后剩余的满足条件node list,经过一系列Priority策略的打分后,最终每个node都得到一个分数,取分数最高的node作为调度节点
- 注意:Priority策略并非同等重要,每一个Priority策略都有权重,在计算分数时,node得分计算公式:
node得分=求和(每个策略得分*权重)
3.2.Priority 常见Plugins
- kube-scheduler是插件化设计,拥有很多Priority插件
- 这里仅列出一些常用的调度策略,实际上还有很多其他的,另外也支持自定义调度Priority策略

3.2.1.SelectorSpreadPriority
- 功能:优先减少节点上属于同一 Service/ReplicationController 的 Pod 数量。
- 原理:通过计算节点上已运行的同服务 Pod 数量,选择同类 Pod 分布最分散 的节点,提升服务容灾能力。
- 场景:部署高可用服务(如 Web 前端)时避免单节点过载。
3.2.2.InterPodAffinityPriority
- 功能:优先将 Pod 调度到满足 Pod间亲和性/反亲和性规则 的拓扑域。
- 原理:根据
podAffinity/podAntiAffinity配置,匹配相同或不同拓扑域(节点/Rack/Zone)的 Pod 分布。 - 示例:数据库与缓存服务需共置(亲和性),或同类服务跨可用区部署(反亲和性)。
3.2.3.LeastRequestedPriority
- 功能:优先调度到 资源请求量少 的节点。优先调度到能满足要求并且剩余资源最少的节点
- 原理:基于节点剩余资源比例计算得分,公式:
得分 = (CPU剩余量 / CPU总量 + 内存剩余量 / 内存总量) / 2 * 10 - 优势:最大化资源利用率,适合资源密集型应用(如大数据任务)。
- 缺点:可能造成大量pod调度到相同node,使得部分node压力大,部分node很空
3.2.4.BalancedResourceAllocation
- 功能:优先平衡各节点的 资源使用比例。优先调度到能满足要求并且剩余资源最多的节点
- 原理:计算节点 CPU 和内存使用率的方差,选择资源消耗最均衡的节点,公式:
得分 = 10 - (|CPU使用率 - 内存使用率|) * 10 - 场景:避免节点出现 CPU 过载但内存空闲(或反之)的资源碎片问题。
3.2.5.NodePreferAvoidPodsPriority
- 功能:依据节点注解
alpha.kubernetes.io/preferAvoidPods决策调度权重。 - 原理:若节点存在此注解,则为该节点赋予 固定权重 10000,覆盖其他优先级策略。
- 用途:强制调度/驱逐特定 Pod(如系统关键组件),需谨慎使用(可能破坏常规调度逻辑)。
3.1.6.调度权重对比
| 插件名称 | 默认权重 | 优先级覆盖能力 |
|---|---|---|
| NodePreferAvoidPodsPriority | 10000 | 最高(覆盖其他策略) |
| InterPodAffinityPriority | 1000 | 高 |
| BalancedResourceAllocation | 1 | 低 |
4.Pod资源配置底层原理
4.1.Pod的 三种服务质量Qos

4.1.1.QoS 核心概念
- QoS(Quality of Service)是 Kubernetes 用于管理 Pod 资源分配与驱逐优先级的核心机制。
- QoS通过 Pod 容器的资源请求(
requests)和限制(limits)配置自动分配 QoS 类别,决定资源紧张时 Pod 的驱逐顺序。
4.1.2.QoS 分类规则
4.1.2.1.Guaranteed 有保证的(最高优先级)
- 核心条件:
- 所有容器必须同时设置 CPU 和内存的
requests和limits; - 每个容器的
requests必须等于limits(如cpu: 500m,memory: 1Gi)。
- 所有容器必须同时设置 CPU 和内存的
- 特点:
- 资源完全保障,仅在 Pod 自身超限或节点无更低优先级 Pod 时被驱逐;
- 可使用独占 CPU 核(通过
staticCPU 管理策略)。
4.1.2.2.Burstable 可超售的(中优先级)
- 核心条件:
- 不满足 Guaranteed 条件;
- 至少一个容器设置了 CPU 或内存的
requests或limits。
- 特点:
- 资源使用有下限保障,但允许弹性扩展(如未设
limits时默认使用节点剩余资源); - 驱逐优先级低于 BestEffort,但高于 Guaranteed。
- 资源使用有下限保障,但允许弹性扩展(如未设
4.1.2.3.BestEffort 尽力而为的(最低优先级)
- 核心条件:
- 所有容器均未设置 CPU 和内存的
requests和limits。
- 所有容器均未设置 CPU 和内存的
- 特点:
- 无资源保障,优先被驱逐;
- 适用于非关键任务(如日志收集)以最大化资源利用率。
4.1.3.QoS 对资源管理的具体影响
4.1.3.1.调度与资源分配
- 调度依据:Kubernetes 调度器仅基于
requests分配节点,limits不影响调度;- 比如一个node只有4个cpu,配置limits.cpu==5没有问题,可以调度。但是如果配置requests.cpu==5,pod就会一直Pending,事件报错 InSufficient Cpu 即cpu不足。
- 资源使用限制:
- CPU(可压缩资源):超限时被节流(Throttled),但进程不被终止;
- 内存(不可压缩资源):超限时触发 OOM Killer,进程被终止3,7。
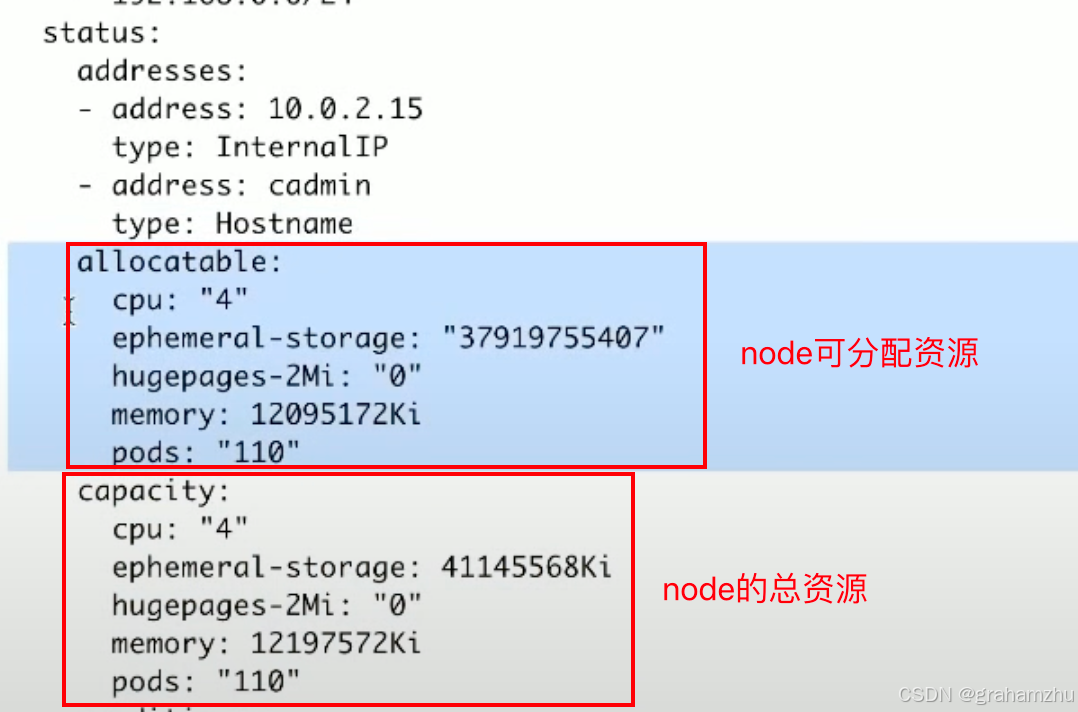
- 调度器完成调度后,会把对应node上的资源信息,扣除掉这个requests
- 比如在node中可以看到总资源、可分配资源(去除系统预留资源之后的)
- 调度器看node是否满足资源要求时,看的就是这里
4.1.3.2.不同QoS适用业务
- 核心服务:使用 Guaranteed 确保稳定性(如数据库)
- 弹性服务:Burstable 适合 Web 服务等需灵活扩展的场景
- 临时任务:BestEffort 用于批处理或监控工具
- 节点分级:结合节点亲和性策略将不同 QoS Pod 调度到专用节点
4.1.4.Pod资源限制的生效原理:cgroups
4.1.4.1.核心机制概述
- Kubernetes 通过 cgroups 实现 Pod 资源限制的运行时控制
- Requests:仅影响调度决策,确保节点有足够资源容纳 Pod
- Limits:通过 cgroups 硬性限制容器运行时资源使用
- 资源类型差异:
- 可压缩资源(CPU):超限时被节流(Throttling)
- 不可压缩资源(内存):超限时触发 OOM Killer
4.1.4.2.CPU 资源实现细节
4.1.4.2.1.前置知识:CPU 的m是什么单位
- 在声明资源时,经常看到100m的cpu,这个m如何解释呢?
- 在虚拟机中,资源限制粒度是非常粗的,cpu至少要是1个,那么如何限制一个应用对cpu更细粒度的资源需求呢?
- m是一个1/1000的单位,1m即为1/1000个cpu。但cpu是个物理的,没办法分,只能从时间片上看,1个cpu一般是100000us(10w us),所以1/1000个cpu即为大约 100us。
4.1.4.2.2.CPU Requests 映射
- 通过 cpu.shares 控制 CPU 时间片分配比例
- 注:
cpu.shares是软限制,在存在多个进程时,通过cpu.shares控制时间分配比例# 计算方式 cpu.shares = requests.cpu * 1024 # 示例:requests.cpu=500m → cpu.shares = 500*1/1000*1024 = 512 # 其中 m==1/1000 - 仅在 CPU 资源争抢时生效,空闲 CPU 可超用
- Pod cpu Requests 配置路径示例:
/sys/fs/cgroup/cpu/kubepods/pod<pod-uid>/<container-id>/cpu.shares
4.1.4.2.2.CPU Limits 映射
- 通过 CFS 配额机制 实现硬性限制:
cpu.cfs_period_us:调度周期(默认 100ms==100000us)cpu.cfs_quota_us:当前进程周期内可用的 CPU 时间# 计算方式 quota = limits.cpu * period # 示例:limits.cpu=1 → quota=100000μs (100ms) # 其中 m==1/1000- Pod cpu Limits路径示例:
/sys/fs/cgroup/cpu/kubepods/pod<pod-uid>/<container-id>/cpu.cfs_quota_us
4.1.4.3. 内存资源实现细节
4.1.4.3.1 内存 Limits 映射
- 通过 memory.limit_in_bytes 设置内存使用上限:
# 示例:limits.memory=512Mi → 536870912 cat /sys/fs/cgroup/memory/kubepods/pod<pod-uid>/<container-id>/memory.limit_in_bytes - 超限时触发 OOM Killer,容器被强制终止
- memory 无对应 Requests 的 cgroups 参数(仅影响调度)
4.1.4.3.2 内存软限制(特殊场景)
- 通过 memory.soft_limit_in_bytes 设置柔性限制:
# 示例(需手动配置): echo 268435456 > /sys/fs/cgroup/memory/.../memory.soft_limit_in_bytes - Kubernetes 默认不配置该参数
4.1.4.4. 多级 cgroups 控制
- Kubernetes 采用分层控制策略:
kubepods (根cgroup) ├── burstable (QoS级别) │ └── pod-uid (Pod级) │ └── container-id (容器级) ├── besteffort └── guaranteed - QoS 级控制:不同 QoS 类别 Pod 的隔离策略
- Pod 级控制:聚合所有容器的资源限制
- 容器级控制:实际执行资源限制的最小单元
4.1.4.5. 完整配置示例
4.1.4.5.1 Pod 定义
apiVersion: v1
kind: Pod
spec:containers:- name: demoimage: nginxresources:requests:cpu: "500m"memory: "256Mi"limits:cpu: "1"memory: "512Mi"
4.1.4.5.2 生成的 cgroups 配置
# CPU 控制文件
/sys/fs/cgroup/cpu/kubepods/burstable/pod-xxx/cpu.shares → 512
/sys/fs/cgroup/cpu/kubepods/burstable/pod-xxx/cpu.cfs_quota_us → 100000# 内存控制文件
/sys/fs/cgroup/memory/kubepods/burstable/pod-xxx/memory.limit_in_bytes → 536870912
4.1.4.6. 监控与调试
4.1.4.6.1 查看当前限制
# CPU 配额使用率
cat /sys/fs/cgroup/cpu/.../cpu.stat | grep nr_throttled# 内存使用量
cat /sys/fs/cgroup/memory/.../memory.usage_in_bytes
4.1.4.6.2 性能问题排查
- CPU Throttling:检查
cpu.stat中的nr_throttled计数 - OOM 事件:通过
dmesg | grep oom_kill查看被杀容器 - 实时监控:
kubectl top pod结合 Prometheus 指标
4.2.LimitRange资源
为了自动化管理 资源设置,提供了LimitRange资源,能够做一些校验+默认值配置,但是资源配置需求多样,LimitRange能提供的能力有限,所以实际生产很少使用
4.2.1.LimitRange定位
- LimitRange 是 Kubernetes 中用于 命名空间级资源管控 的策略对象,主要用于限制 Pod、容器或 PersistentVolumeClaim 的资源分配范围,并自动注入默认配置。
4.2.2.LimitRange核心功能
- 资源范围限制
- 限制 Pod/Container 的 CPU/内存 最小请求值(
min)和 最大限制值(max)
- 默认值注入
- 为未指定
requests/limits的容器自动设置 默认请求值(defaultRequest)和 默认限制值(default)
- 存储限制
- 控制 PersistentVolumeClaim 的存储容量范围(
storage字段)
- 资源比例控制
- 通过
maxLimitRequestRatio限制资源limits与requests的比值
4.2.3.LimitRange Spec 常用字段
| 字段 | 类型 | 描述 | 示例值 |
|---|---|---|---|
type | string | 限制对象类型(Pod/Container/PersistentVolumeClaim) | Container |
default | map | 默认资源限制值(cpu/memory) | cpu: "500m" |
defaultRequest | map | 默认资源请求值 | memory: "256Mi" |
min | map | 资源请求/限制的最小值 | cpu: "100m" |
max | map | 资源请求/限制的最大值 | memory: "2Gi" |
maxLimitRequestRatio | map | limits 与 requests 的最大比值 | cpu: 3 |
4.2.4.LimitRange使用示例
apiVersion: v1
kind: LimitRange
metadata:name: example-limitrange
spec:limits:- type: Containerdefault:cpu: "500m"memory: "512Mi"defaultRequest:cpu: "200m"memory: "256Mi"min:cpu: "100m"memory: "128Mi"max:cpu: "2"memory: "2Gi"maxLimitRequestRatio:cpu: 3- type: PersistentVolumeClaimmin:storage: "1Gi"max:storage: "10Gi"
4.2.5.LimitRange的局限性
- LimitRange设置默认值实际使用中受限
- LimitRange无法区分container的类型:主容器、initContainer,所以设置的默认值会同时设置到initContainer上去,这在使用中不太符合实际,所以限制了LimitRange的实际使用
- 因此LimitRange一般可用于设置Limit上限,但不太会用default设置
4.3.磁盘资源需求

- 临时存储发生在调度完成之后,由node上的kubelet来管理
- 比如一个pod声明了临时存储,如果对临时存储的使用超限,pod会被驱逐,驱逐pod后会清理掉临时写的那些数据,防止对磁盘造成压力影响到系统稳定性。
5.调度器仅关注pod的requests
调度器 关注的 pod资源总量== 多个Containers requests资源之和 + 多个initContainers requests最大值

-
调度器只关注requests
-
不同类型容器的requests需求不一样
- 对于 pod 的 多个Containers,在运行时是同时运行的,所以资源计算方法,是所有Containers requests之和
- 对于 pod 的 多个initContainers,在运行时是串行运行的,所以资源计算方法,是 取initContainers requests的最大值,并不会把所有initContainers requests加起来
-
提出问题:
- initContainers阶段需要大量资源,init结束,资源不会归还,也不再使用,其实就浪费掉了
- 解决:没有直接的解决办法,应用一般不会主动归还资源,可以看是否可以配置一些HPA、VPA做一些弹性工作,或做一个额外的组件专用于回收资源
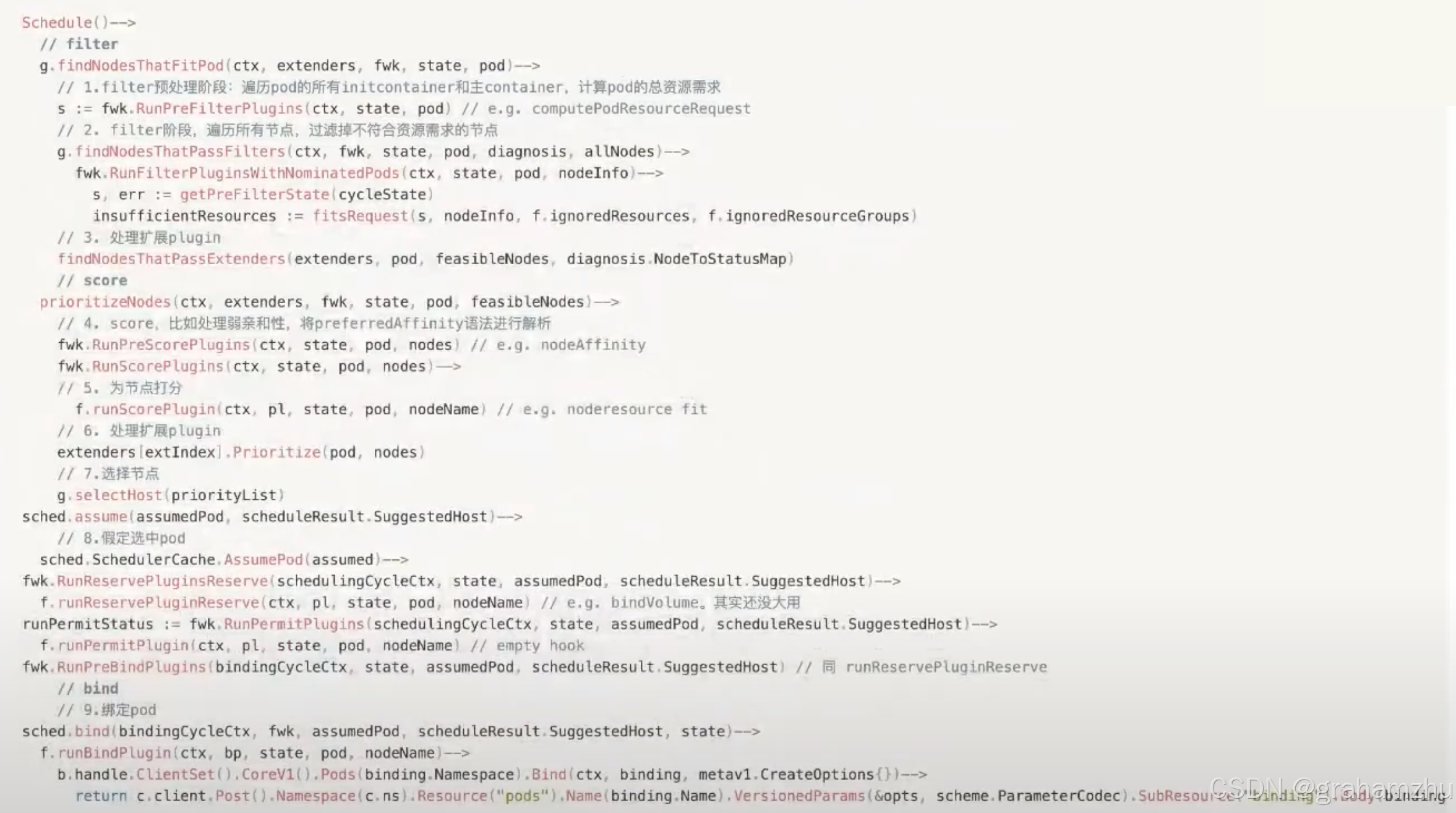
6.kube-scheduler代码关键点

7.常见问题解析
7.1.Predicate、Priority阶段的插件都是顺序执行的吗?
- Kubernetes 调度器的 Predicate 插件(在旧版本中称为 Predicates 阶段)并非完全顺序执行,其执行模式取决于调度器版本和具体配置。
7.1.1.旧版本调度器(基于 Predicates/Priorities 架构)
- 顺序执行
- 在 Kubernetes v1.15 及更早版本中,Predicates 阶段的规则是顺序执行的。每个 Predicate 规则依次对候选节点进行过滤,只有通过所有规则的节点才能进入下一阶段。例如:
- 先检查
PodFitsResources(资源是否足够) - 再检查
PodFitsHostPorts(端口是否冲突) - 最后验证
PodToleratesNodeTaints(污点容忍)
- 先检查
- 并发处理节点
- 虽然规则是顺序执行的,但每个 Predicate 规则会对所有节点并发计算(默认开启 16 个 Goroutine)。
- 例如,当处理
PodFitsResources时,调度器会同时计算所有节点的 CPU/内存资源是否满足需求。
- 性能瓶颈
- 顺序执行规则在节点规模较大时会导致延迟累积,例如若某个规则计算耗时较长,整个调度周期会被拉长。
7.1.2.新版调度框架(Scheduler Framework)
- 从 Kubernetes v1.16 开始引入的 Scheduler Framework 对 Predicates 进行了重构,将其拆分为 Filter 插件,并支持更灵活的并发机制
- 默认并行执行
- Filter 插件在调度框架中默认并行执行(部分插件可能因依赖关系需顺序处理)。例如:
NodeResourcesFit(资源检查)和NodeAffinity(节点亲和性)可以同时计算;VolumeBinding(存储卷绑定)和PodTopologySpread(拓扑分布)可能并行运行。
- Filter 插件在调度框架中默认并行执行(部分插件可能因依赖关系需顺序处理)。例如:
- 依赖控制
- 若插件之间存在依赖关系(例如必须先完成资源检查再处理亲和性),可通过插件配置显式声明执行顺序。
- 性能优化
- 并行执行显著减少调度延迟,尤其在大规模集群中效果明显。例如,1000 节点的集群调度耗时可从旧版的 2-3 秒降至 500 毫秒以内。
- 顺序执行的例外场景
- 即使在新版本中,部分 Filter 插件仍需顺序执行
- 资源预检查
如NodeResourcesFit(资源充足性)通常需要优先执行,避免在不满足资源条件的节点上浪费计算资源。 - 存储卷绑定
VolumeBinding插件必须等待持久卷(PV)绑定完成后才能进行后续检查。 - 拓扑分布约束
PodTopologySpread需要基于当前已调度 Pod 的分布状态,可能依赖于其他插件的执行结果。
- 资源预检查
- 即使在新版本中,部分 Filter 插件仍需顺序执行