【AI论文】对人工智能生成文本的稳健和细粒度检测
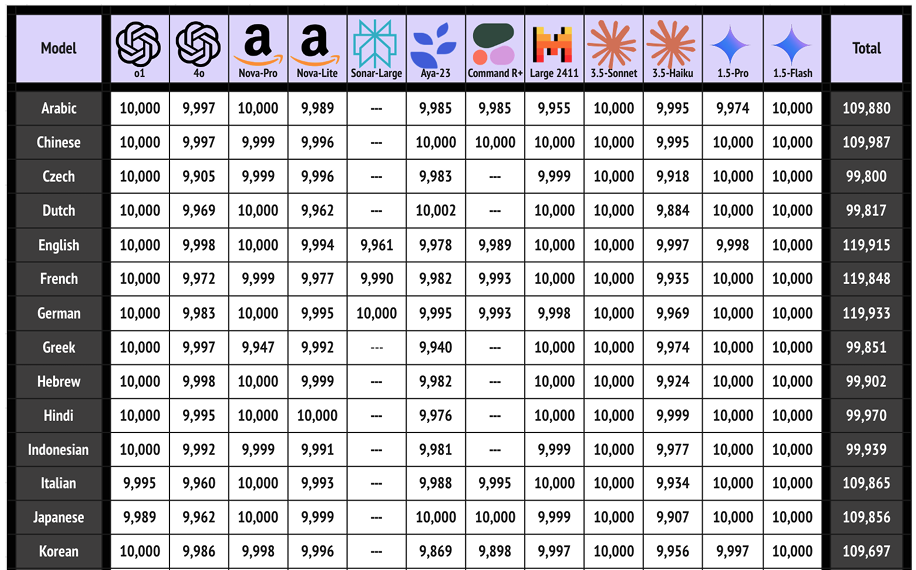
摘要:机器生成内容的理想检测系统应该能够在任何生成器上很好地工作,因为越来越多的高级LLM每天都在出现。 现有的系统往往难以准确识别人工智能生成的短文本内容。 此外,并非所有文本都完全由人类或LLM创作,因此我们更关注部分案例,即人类-LLM共同创作的文本。 我们的论文介绍了一组为标记分类任务而构建的模型,这些模型是在大量的人机共同撰写的文本上训练的,在未见过的领域、未见过的生成器、非母语人士撰写的文本和具有对抗性输入的文本上表现良好。 我们还引入了一个新的数据集,其中包含超过240万篇这样的文本,这些文本大多是由几种流行的专有LLM在23种语言上共同撰写的。 我们还展示了我们的模型在每个领域和生成器的每个文本上的性能表现。 其他发现包括对每种对抗方法的性能比较、输入文本的长度以及与原始人类创作文本相比生成文本的特征。Huggingface链接:Paper page,论文链接:2504.11952
研究背景和目的
研究背景
随着大型语言模型(LLMs)的快速发展,其生成文本的能力日益增强,使得人工智能生成文本在各个领域的应用日益广泛。然而,这也带来了一系列挑战,尤其是如何准确检测和识别这些由AI生成的文本。传统的检测方法在面对日益复杂和逼真的AI生成文本时,往往难以取得令人满意的效果。特别是在短文本场景下,以及当文本由人类和LLM共同创作时,现有的检测系统更是力不从心。此外,随着新的LLM不断涌现,它们的风格和特性各不相同,这也对检测系统的泛化能力提出了更高要求。
在此背景下,研究一种稳健且细粒度的AI生成文本检测方法显得尤为重要。该方法不仅需要能够准确识别不同LLM生成的文本,还需要能够处理人机共同创作的文本,甚至需要对抗各种对抗性输入。这对于维护信息的真实性、打击虚假信息的传播具有重要意义,特别是在教育、新闻、社交媒体等领域。
研究目的
本研究旨在开发一套针对AI生成文本的稳健且细粒度的检测系统。该系统的主要目标包括:
- 泛化能力强:能够在不同领域、不同LLM生成的文本上取得良好的检测效果,而不仅仅是局限于特定的生成器或文本类型。
- 细粒度检测:不仅能够判断一段文本是否由AI生成,还能够准确识别出文本中由AI生成的部分,实现人机共创文本的精细分割。
- 对抗性强:能够抵御各种对抗性输入,包括但不限于重述、拼写错误、同形异义词等,确保检测结果的准确性和可靠性。
- 实用性强:提出的检测方法和模型应易于部署和使用,能够在实际应用中发挥有效作用。
研究方法
数据集构建
为了训练和评估检测模型,本研究构建了一个大型的多语言数据集,包含超过240万篇文本。这些文本大多由几种流行的专有LLM在23种语言上共同撰写。数据集的构建过程考虑了多种因素,包括文本的长度、领域、生成器的类型以及是否包含对抗性输入等。此外,还考虑了非母语人士撰写的文本,以增加数据集的多样性和复杂性。
具体来说,数据集的构建过程包括以下几个步骤:
- 选择生成器:从多种LLM中选择代表性的生成器,包括流行的专有LLM和开源LLM。
- 文本生成:使用选定的生成器生成大量文本,这些文本涵盖不同的领域和主题。
- 数据清洗:对生成的文本进行清洗和过滤,去除重复、低质量或不符合要求的文本。
- 标注数据:对清洗后的文本进行标注,包括标注出由AI生成的部分和人类撰写的部分。
- 引入对抗性输入:在部分文本中引入对抗性输入,如重述、拼写错误、同形异义词等,以测试检测模型的对抗性。
模型构建
本研究采用了一种基于标记分类的检测方法。具体来说,使用了一种多语言Transformer模型,并在其基础上添加了条件随机场(CRF)层以提高分类的准确性。模型的训练过程采用了二进制标记分类的方法,即对每个标记进行分类,判断其是否由AI生成。在训练过程中,使用了交叉熵损失函数和多种优化技术来提高模型的收敛速度和最终性能。
评估方法
为了全面评估检测模型的性能,本研究采用了多种评估指标和方法,包括:
- 准确率、精确率和召回率:在词级、句子级和整体级别上计算模型的准确率、精确率和召回率,以评估模型在不同粒度上的检测效果。
- F1分数:综合精确率和召回率计算F1分数,以更全面地评估模型的性能。
- 跨领域和跨生成器测试:在未见过的领域和生成器上测试模型的性能,以评估其泛化能力。
- 对抗性测试:在包含对抗性输入的文本上测试模型的性能,以评估其对抗性。
研究结果
模型性能
实验结果表明,本研究提出的检测模型在多个基准测试集上取得了优异的性能。具体来说:
- 词级准确率:在测试集上,模型的词级准确率达到了较高水平,表明模型能够准确识别文本中由AI生成的部分。
- 跨领域和跨生成器性能:在未见过的领域和生成器上,模型仍然能够保持较好的性能,表明模型具有较强的泛化能力。
- 对抗性:在包含对抗性输入的文本上,模型仍然能够取得较高的准确率,表明模型具有较强的对抗性。
数据集分析
通过对数据集的分析,本研究还发现了一些有趣的现象:
- 文本长度:由AI生成的文本部分往往比人类撰写的部分更短,这可能是由于LLM在生成文本时倾向于使用更简洁的表达方式。
- 语言特性:不同语言在由AI生成的文本部分上表现出不同的特性,如某些语言可能更容易被LLM模仿或生成。
- 对抗性输入的影响:不同类型的对抗性输入对模型性能的影响程度不同,其中重述和同形异义词等对抗性输入对模型性能的影响较大。
研究局限
尽管本研究在AI生成文本的检测方面取得了一定的进展,但仍存在一些局限性:
- 数据集多样性:尽管本研究构建了一个大型的多语言数据集,但数据集的多样性仍然有限,无法涵盖所有可能的文本类型和领域。
- 模型复杂性:为了提高检测准确性,本研究采用了一种相对复杂的模型结构。然而,这也增加了模型的计算复杂性和部署难度。
- 对抗性测试:尽管本研究在包含对抗性输入的文本上测试了模型的性能,但对抗性输入的类型和强度仍然有限,无法完全模拟实际场景中的对抗性情况。
未来研究方向
针对上述研究局限,未来的研究可以从以下几个方面展开:
- 扩展数据集:进一步扩展数据集的多样性和规模,涵盖更多类型的文本和领域,以提高模型的泛化能力。
- 优化模型结构:探索更简洁、高效的模型结构,以降低模型的计算复杂性和部署难度。
- 增强对抗性:引入更多类型和强度的对抗性输入,以测试和提高模型的对抗性。
- 实际应用:将检测模型应用于实际场景中,如教育、新闻、社交媒体等领域,以验证其有效性和实用性。同时,根据实际应用中的反馈和需求对模型进行进一步优化和改进。
此外,未来的研究还可以探索将检测模型与其他技术相结合的方法,如自然语言处理、机器学习、深度学习等,以提高检测的准确性和效率。同时,也可以关注与AI生成文本检测相关的伦理和法律问题,以确保技术的合理和合规使用。