Federated Weakly Supervised Video Anomaly Detection with Multimodal Prompt

标题:联邦弱监督视频异常检测的多模态提示方法
原文链接:https://ojs.aaai.org/index.php/AAAI/article/view/35398
源码链接:https://github.com/wbfwonderful/Fed-WSVAD
发表:AAAI-2025
摘要(Abstract)
视频异常检测(Video Anomaly Detection, VAD)旨在定位视频中的异常事件。近年来,弱监督视频异常检测(Weakly Supervised VAD)取得了显著进展,其在训练时仅需视频级标签。在实际应用中,不同机构可能拥有不同类型的异常视频。然而,出于隐私保护的考虑,这些异常视频无法在互联网上流通。为了训练一个能够识别多种异常类型的更具泛化能力的异常检测器,将联邦学习引入 WSVAD 是合理的。在本文中,我们提出了一种基于全局与局部上下文驱动的联邦学习方法,这是一种新的隐私保护弱监督视频异常检测范式。具体而言,我们利用 CLIP 的视觉-语言关联能力来检测视频帧是否异常。不同于使用人工设计的文本提示,我们提出了一种文本提示生成器。所生成的提示同时受到文本和视觉的影响:一方面,文本提供与异常相关的全局上下文,增强模型的泛化能力;另一方面,视觉提供个性化的局部上下文,因为不同客户端可能拥有不同类型的异常视频或场景。该提示能够在处理来自不同客户端的个性化数据时,同时保持全局泛化性。大量实验证明,所提出的方法具有显著性能。
代码链接:https://github.com/wbfwonderful/Fed-WSVAD
引言(Introduction)
视频异常检测(Video Anomaly Detection, VAD)是计算机视觉领域中的一项重要任务(Zhang, Qing, and Miao 2019; Huang et al. 2021, 2022b,c)。例如,VAD 可应用于智能监控系统,用于检测异常事件以减少财产损失。此外,VAD 还可用于视频内容审查系统,以更好地检测不良内容。弱监督视频异常检测(WSVAD)(Sultani, Chen, and Shah 2018; Huang et al. 2022a; Zhang et al. 2022; Wu et al. 2023)是 VAD 的一个重要分支。对于 WSVAD,模型会同时以正常视频和异常视频作为输入,但仅提供视频级标签。现有方法通常通过多实例学习(Multiple Instance Learning, MIL)(Sultani, Chen, and Shah 2018)将帧级异常分数适配到视频级标签。WSVAD 在标注成本极低的前提下取得了良好性能。然而,传统的 WSVAD 仅利用单一模态信息。
近年来,以 CLIP(Contrastive Language-Image Pretraining)(Radford et al. 2021)为代表的大规模视觉-语言预训练模型在多个下游任务中展现出强大性能,如目标检测(Du et al. 2022; Zhao et al. 2022; Kim et al. 2024)、图像分割(Xu et al. 2022; Yun et al. 2023; Luo et al. 2024)和视频理解(Wu, Sun, and Ouyang 2023; Jin et al. 2024)。CLIP 的核心思想是通过对比学习在嵌入空间中对齐图像和文本。一些研究尝试将 CLIP 应用于 WSVAD(Wu et al. 2024a,b,c; Yang, Liu, and Wu 2024)。尽管这些基于 CLIP 的方法由于利用了视觉-语言关联性而优于传统方法,但它们仅适用于集中式训练,即所有视频必须上传至中心服务器,这将无法保证数据隐私。
联邦学习(Federated Learning, FL)(McMahan et al. 2017)是一种分布式机器学习方法,其目标是在不共享原始数据的前提下,在多个客户端之间训练统一模型,以实现隐私保护。近年来,一些研究已将联邦学习应用于计算机视觉任务,如图像分类(Hsu, Qi, and Brown 2020; Su et al. 2024)和识别(Liu et al. 2020; Dutto et al. 2024)。在 VAD 场景中,异常视频可能分布于不同机构或数据拥有者之间。由于视频内容的敏感性或隐私保护,难以将这些视频集中收集用于训练。例如,交通部门可能拥有交通事故的监控视频,但为了保护事故当事人,该类视频禁止在互联网上传播。此外,公安部门可能拥有执法记录仪拍摄的视频,由于其中包含暴力或恐怖画面,也无法传播。因此,将 WSVAD 引入联邦学习环境以训练统一的异常检测模型是合理的选择。
为了在联邦学习环境中实现隐私保护的 WSVAD,并激活 CLIP 在该任务中的潜力,需解决以下三个挑战:
- 如何将 CLIP 适配到 WSVAD 任务;
- 如何在联邦学习环境中利用 CLIP;
- 如何提升联邦模型的性能。
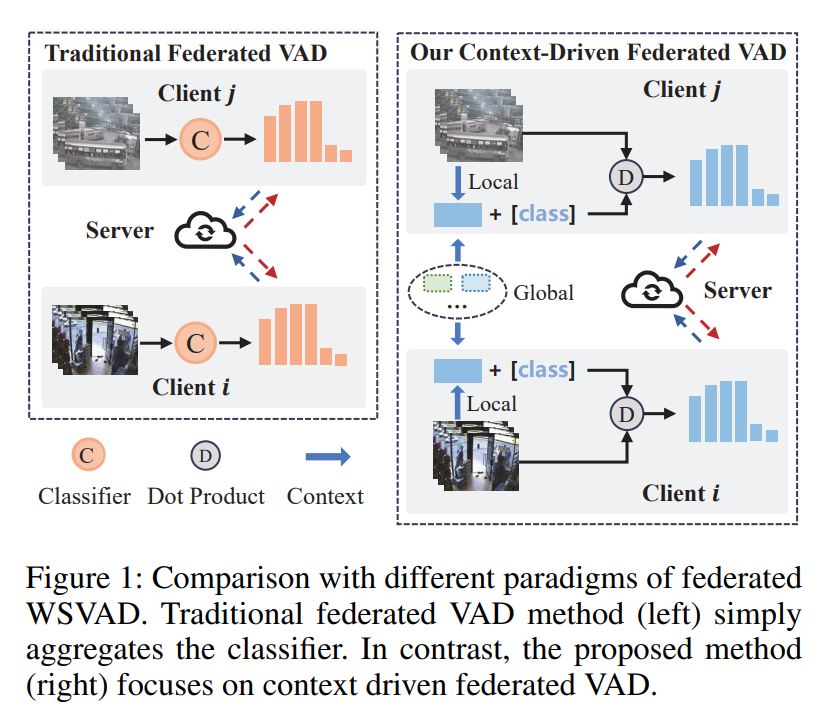
在本文中,我们提出了一种基于全局与局部上下文驱动的联邦学习框架,用于隐私保护的视频异常检测。图 1 展示了我们提出的方法与传统联邦 WSVAD 方法之间的差异。具体而言,对于第一个挑战,我们提出了一个时序建模模块,用于捕捉异常事件的时间依赖性,因为视频中的异常帧通常是连续相关的。之后,引入文本来利用 CLIP 的视觉-语言关联性。类似于 CLIP 的零样本图像分类方式,我们计算文本和视觉特征之间的相似度。最终,该相似度图表示了多类别的帧级异常置信度。同时,由于 WSVAD 仅有视频级标注,我们采用 MIL 策略选取最具异常性的帧来代表整段视频。
对于第二个挑战,CLIP 由于其强大的表征能力,能够适配来自不同客户端的多样数据,因此适用于联邦学习(Cui et al. 2024b)。然而,在联邦学习中完整训练 CLIP 计算与传输代价过高。Prompt Learning 技术(如 Context Optimization, CoOp)(Zhou et al. 2022b)通过引入可训练参数适配 CLIP 于下游任务,从而在保持 CLIP 原有能力的同时提取任务相关信息。一些研究(Zhao et al. 2023; Yang, Wang, and Wang 2023; Li et al. 2024)已将 Prompt Learning 扩展至联邦学习环境,在保留 CLIP 能力的同时为每个客户端学习个性化 Prompt。然而,这些 Prompt 的表达仍存在局限。因此,我们提出了一种生成器,能够根据上下文动态生成唯一的 Prompt。
对于第三个挑战,我们提出的 Prompt 生成器由全局与局部上下文共同驱动:一方面,全局上下文由来自所有客户端的异常类别构成,具备全局任务相关性;在全局聚合过程中,受到全局上下文调节的 Prompt 生成器能够保持尽可能快的泛化能力,也就是说,生成的 Prompt 可泛化至其他客户端的异常类别。另一方面,局部上下文来自于客户端间不同特征的视频。例如,客户端 i i i 拥有街道监控视频,而客户端 j j j 拥有商店监控视频。局部上下文引导生成的 Prompt 关注来自不同客户端视频的平均分布,即模型在保持泛化的前提下,适度地识别客户端特有的特征。总之,全局与局部上下文的结合,在全局最优与局部最优之间取得平衡。
相关工作(Related Work)
弱监督视频异常检测(Weakly Supervised Video Anomaly Detection)
训练 WSVAD 模型时仅提供视频级别的标注。为了解决这一限制,Sultani 等人(Sultani, Chen, and Shah 2018)首次提出了一种多实例学习(Multiple Instance Learning, MIL)框架用于 WSVAD,将视频视为“包”(bags),将视频片段(snippets)视为“实例”(instances)。MIL 的核心思想是选择异常置信度最高的片段来代表整个视频。随后,引入了排序损失(rank loss)以拉开正常视频与异常视频中代表性片段之间的距离。在此基础上,许多后续研究做出了改进。例如,Huang 等人(Huang et al. 2022a)提出了一种基于 Transformer 的时序特征聚合器,用于捕捉不同嵌入空间中片段的语义相似性与位置相关性;Zhou 等人(Zhou, Yu, and Yang 2023)提出了一种记忆机制,用于存储正常和异常原型,以更好地区分难分类样本;Lv 等人(Lv et al. 2023)提出了一种无偏 MIL 框架,引导模型关注无偏异常。
近年来,多模态学习(Xu et al. 2023; Ling et al. 2023; Cui et al. 2023, 2024a)取得显著进展。一些研究引入了如 CLIP 等预训练视觉-语言模型到 WSVAD 中。具体而言,Wu 等人(Wu et al. 2024c)提出了一种名为 VadCLIP 的新范式,通过两种 Prompt 机制适配 CLIP 至 WSVAD;Yang 等人(Yang, Liu, and Wu 2024)提出了一个框架,用于将 CLIP 的能力迁移至伪标签生成,从而服务于 WSVAD。
此外,还有少量研究尝试将 WSVAD 应用于联邦学习场景。具体而言,Doshi 等人(Doshi and Yilmaz 2023)提出了一种基于 Transformer 的联邦学习框架,用于视频异常检测与视频动作识别;Al-Lahham 等人(Al-Lahham et al. 2024)提出了一种名为 CLAP 的新基线,该方法为联邦 VAD 提供了新的测试与评估场景。然而,联邦 VAD 的性能仍有进一步探索空间。
用于 CLIP 的联邦 Prompt 学习(Federated Prompt Learning for CLIP)
Prompt 调优技术能有效地将 CLIP 适配至下游任务。例如,CoOp(Zhou et al. 2022b)将人工设计的 Prompt 替换为一组可学习向量,用于 CLIP 的文本编码器。进一步地,CoCoOp(Zhou et al. 2022a)通过图像输入动态调整所学习的 Prompt。一些研究(Guo et al. 2023;Zhao et al. 2023)将 Prompt 调优引入联邦学习,既保持了 CLIP 的强大能力,又降低了通信成本。此外,pFedPG(Yang, Wang, and Wang 2023)学习了一个网络,用于生成个性化 Prompt,以应对客户端之间的个性化数据问题;FedTPG(Qiu et al. 2024)则训练了一个条件于任务上下文的 Prompt 生成器,使模型具备对未见类别和数据集的泛化能力;FedAPT(Su et al. 2024)解决了跨域挑战,通过在 Prompt 中注入个性化信息,引导 CLIP 激活领域相关知识;Fed-DPT(Wei et al. 2023)通过自注意力机制将视觉和文本表征耦合的方式进行领域特定 Prompt 学习,以促进领域适应。
然而,在联邦环境中,关键挑战在于如何使每个客户端能够适配或生成适合其个性化数据的 Prompt,同时仍对全局模型做出贡献,确保其具有鲁棒且泛化的能力。一些研究致力于泛化与个性化之间的平衡。例如,FedOTP(Li et al. 2024)利用非均衡最优传输(Unbalanced Optimal Transport)对齐全局与局部 Prompt,同时引导 Prompt 更多关注图像中的类别相关信息;FedPGP(Cui et al. 2024b)采用低秩分解方式,在保证鲁棒泛化的同时引入对比损失。
所提方法(Proposed Method)
在本节中,我们将详细介绍本文提出的方法,如图 2 所示。我们的方法通过全局与局部上下文驱动的 Prompt,适配 CLIP 于联邦弱监督视频异常检测(WSVAD)任务。
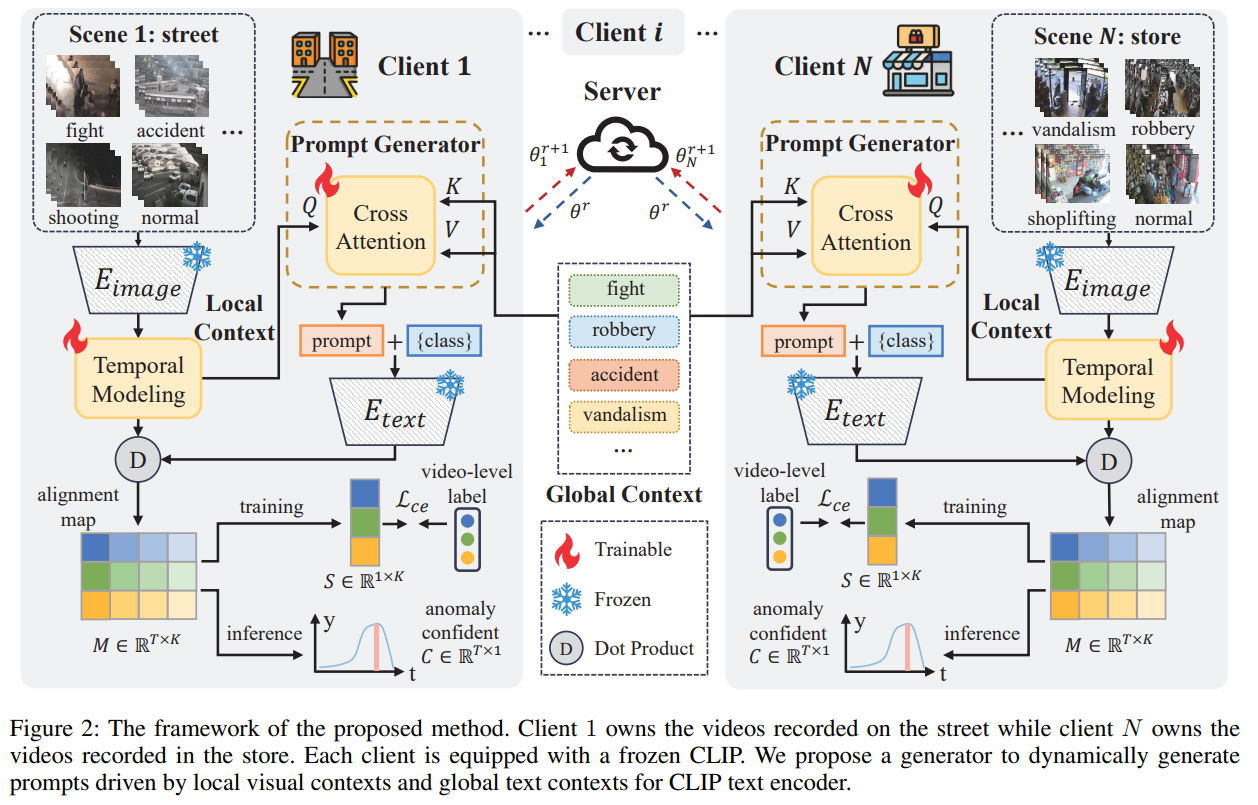
图2:所提方法的框架示意图。客户端1拥有街道录制的视频,而客户端N拥有商店录制的视频。每个客户端均配备一个冻结的CLIP模型。我们提出一个生成器,用于动态生成由局部视觉上下文和全局文本上下文驱动的提示,供CLIP文本编码器使用。
将 CLIP 适配至 WSVAD(Adapting CLIP for WSVAD)
在训练阶段,WSVAD 仅提供视频级别的标签。给定一个视频 v v v,若至少存在一个帧包含异常,则该视频被定义为异常,标签 y = 1 y=1 y=1;反之,若所有帧均为正常,则标签为 y = 0 y=0 y=0。WSVAD 的目标是训练一个异常检测器 f ( ⋅ ) f(\cdot) f(⋅),在仅有视频级标签的情况下预测帧级异常置信度。
以往研究通常使用预训练的 C3D(Tran et al., 2015)或 I3D(Carreira and Zisserman, 2017)提取视频特征。为了获得更好的特征表示并利用视觉-语言关联性,我们采用 CLIP 的图像编码器提取视频帧特征。具体而言,提取的特征可表示为:
I ∈ R T × D I \in \mathbb{R}^{T \times D} I∈RT×D
其中 T T T 表示帧数, D D D 是嵌入维度。CLIP 在大规模图文对上训练,在多种图像处理任务中表现优异。然而,若仅使用 CLIP 处理视频帧,则会忽略时间上的依赖性。对于 WSVAD,异常事件往往持续一段时间,若仅以独立帧检测异常将难以奏效。
为了解决 CLIP 缺乏时间建模的问题,一些研究(Huang et al. 2022a;Wu et al. 2024c)提出了各种时序建模模块。类似地,我们引入一个轻量级的时序建模模块,具体做法为:在 CLIP 图像编码器提取特征后,接入一个 Transformer 编码器 ϕ ( ⋅ ) \phi(\cdot) ϕ(⋅),得到具有时序信息的视频特征:
V = ϕ ( I ) , V ∈ R T × D V = \phi(I), \quad V \in \mathbb{R}^{T \times D} V=ϕ(I),V∈RT×D
然后,文本标签通过 CLIP 的文本编码器进行编码,得到:
L ∈ R K × D L \in \mathbb{R}^{K \times D} L∈RK×D
其中 K K K 表示标签类别数量。随后,计算帧特征与文本特征之间的对齐图(alignment map)如下:
M = V ⋅ L ⊤ (1) M = V \cdot L^\top \tag{1} M=V⋅L⊤(1)
其中 M ∈ R T × K M \in \mathbb{R}^{T \times K} M∈RT×K 表示每帧与各类别文本之间的相似度。
接下来,我们对齐图 M M M 进行处理,以适配视频级标签。具体而言, M M M 的每一列表示视频帧与某一类别的相似度。我们取每列中前 k k k 大值的平均,衡量视频与该类别的匹配程度,得到:
S = { s 1 , s 2 , … , s K } S = \{s_1, s_2, \dots, s_K\} S={s1,s2,…,sK}
最终,计算多类别预测结果:
p i = exp ( s i / τ ) ∑ j exp ( s j / τ ) (2) p_i = \frac{\exp(s_i / \tau)}{\sum_j \exp(s_j / \tau)} \tag{2} pi=∑jexp(sj/τ)exp(si/τ)(2)
其中, p i p_i pi 表示视频属于第 i i i 类的概率, τ \tau τ 为温度超参数。最终采用交叉熵损失训练模型。
在推理阶段,对于对齐图 M M M,我们关注其与“正常”类别之间的相似度。若相似度越高,说明当前帧越可能是正常的,对应的异常置信度应越低。因此,我们将其相似度从 1 中减去,作为异常置信度输出。
联邦 WSVAD 中的 Prompt 生成(Generating Prompts in Federated WSVAD)
CoOp(Zhou et al. 2022b)通过将手工设计的文本提示替换为可学习的向量,有效提升了 CLIP 在下游任务中的性能。类似地,我们为 CLIP 文本编码器引入文本 Prompt,以适配多种异常类别。但在联邦学习环境下,单纯可学习的 Prompt 表达能力受限。
为更好适配联邦 WSVAD,我们提出一种 Prompt 生成器,用于动态生成文本 Prompt。具体过程如下:
-
首先,原始类别标签 l l l 经过 CLIP 的分词器处理:
tokens = Tokenizer ( l ) \text{tokens} = \text{Tokenizer}(l) tokens=Tokenizer(l)
-
然后,将生成的 Prompt 表示为 P = { p 1 , . . . , p n } P = \{p_1, ..., p_n\} P={p1,...,pn},与分词后的类别标签拼接,作为 CLIP 文本编码器的输入:
t = { p 1 , . . . , token , . . . , p n } t = \{p_1, ..., \text{token}, ..., p_n\} t={p1,...,token,...,pn}
接下来我们讨论 Prompt 生成器在联邦 WSVAD 中的训练过程。设联邦学习包含 N N N 个客户端,每个客户端 i i i 拥有本地数据集 D i D_i Di,且配备预训练的 CLIP 模型。每个客户端的可训练参数包括上一节提到的时序建模模块和 Prompt 生成器,而 CLIP 本体始终被冻结。
第 r r r 轮训练的交互流程如下:
-
步骤 I:每个客户端从服务器接收并加载全局模型参数 θ r \theta_r θr;
-
步骤 II:每个客户端 i i i 利用 Prompt 与类别标签拼接后输入文本编码器,按公式(2)计算预测 P P P,并使用以下损失函数训练模型:
L i = − E ( v , Y ) ∈ D i Y log P (3) \mathcal{L}_i = - \mathbb{E}_{(v, Y) \in D_i} \, Y \log P \tag{3} Li=−E(v,Y)∈DiYlogP(3)
其中 Y ∈ R K Y \in \mathbb{R}^K Y∈RK 为多标签表示。
-
步骤 III:客户端在本地训练若干轮后,将本地参数 θ r i \theta_r^i θri 发送至服务器,服务器按加权平均规则聚合为全局参数:
θ r + 1 = ∑ i ∣ D i ∣ ∑ j ∣ D j ∣ θ r i (4) \theta_{r+1} = \sum_i \frac{|D_i|}{\sum_j |D_j|} \theta_r^i \tag{4} θr+1=i∑∑j∣Dj∣∣Di∣θri(4)
全局与局部上下文驱动的 Prompt(Global and Local Context-driven Prompt)
联邦学习旨在利用分布式数据训练统一模型。但实际中,各客户端间数据分布通常不同。例如,不同机构可能拥有风格各异的异常视频。因此,为同时实现局部个性化和全局泛化,我们提出一种全局与局部上下文驱动的 Prompt 学习策略。
-
全局上下文:受 FedTPG(Qiu et al. 2024)启发,任务相关文本可为联邦 Prompt 学习提供语义上下文。在 WSVAD 中,来自各客户端的异常类别文本构成的全局上下文,包含了对整个任务的概括性描述。即使某些客户端未见过某些异常类别,全局上下文也能激活冻结的 CLIP,赋予其一定的识别能力。
-
局部上下文:本地视觉特征提供客户端特有的视频平均语义,引导模型学习本地数据分布,从而避免模型偏向某个具体类别。
两者结合后,Prompt 学习可在个性化与泛化之间取得平衡。
具体而言,Prompt 生成器由一个 Cross-Attention 模块组成:
-
对于全局上下文,类别文本首先编码为:
T ∈ R K × D T \in \mathbb{R}^{K \times D} T∈RK×D
然后映射为 Key 和 Value:
K T = T × W K , V T = T × W V K_T = T \times W_K,\quad V_T = T \times W_V KT=T×WK,VT=T×WV
-
对于局部上下文,考虑一批视频帧特征 V ∈ R B × T × D V \in \mathbb{R}^{B \times T \times D} V∈RB×T×D,对 batch 维度进行平均得到:
V ˉ ∈ R T × D , Q V ˉ = V ˉ × W Q \bar{V} \in \mathbb{R}^{T \times D}, \quad Q_{\bar{V}} = \bar{V} \times W_Q Vˉ∈RT×D,QVˉ=Vˉ×WQ
最终,Prompt P P P 通过 Cross-Attention 融合得到:
P = CrossAttention ( Q V ˉ , K T , V T ) (5) P = \text{CrossAttention}(Q_{\bar{V}}, K_T, V_T) \tag{5} P=CrossAttention(QVˉ,KT,VT)(5)
实验(Experiment)

实验设置(Experimental Settings)
数据集与评估指标(Datasets and Evaluation Metrics)
我们在两个大规模数据集上进行了大量实验:UCF-Crime(Sultani, Chen, and Shah 2018)和 XD-Violence(Wu et al. 2020)。此外,我们还在未见过的数据集 ShanghaiTech(Luo, Liu, and Gao 2017)的测试集上评估了方法的泛化能力。ShanghaiTech 最初设计用于半监督 VAD,我们采用 Zhong 等人(Zhong et al. 2019)重构后的测试集。
参考 CLAP(Al-Lahham et al. 2024),我们对 UCF-Crime 和 XD-Violence 进行了三种数据划分策略:
- 随机划分(Random Split):作为基线设定,每个客户端持有数量相同的视频;
- 基于事件划分(Event-Based Split):每个客户端拥有不同类型异常的视频。例如,客户端 i i i 包含爆炸类视频,而客户端 j j j 包含打斗类视频;
- 基于场景划分(Scene-Based Split):最贴近真实应用场景,每个客户端的视频来自特定场景。例如,客户端 i i i 拥有商店中发生如抢劫、偷窃等异常的视频,而客户端 j j j 拥有街道上发生如交通事故、枪击事件的视频。
更多划分细节见附录材料。
评估指标方面,遵循以往工作(Wu et al. 2020, 2024c),我们在 UCF-Crime 和 ShanghaiTech 上采用帧级 ROC 曲线的 AUC(Area Under Curve)作为指标,而在 XD-Violence 上使用帧级 PR 曲线的 AP(Average Precision)作为指标。
训练设定(Training Settings)
我们在以下三种训练设定下对所提方法与现有 SOTA 方法进行比较:
- 集中式训练(Centralized Training):将所有数据集中训练异常检测器,不考虑隐私问题;
- 本地训练(Local Training):每个客户端仅在本地数据上训练自身模型,隐私安全但可能损失全局性能;
- 联邦训练(Federated Training):多个客户端共同训练一个联合异常检测器,同时保障本地数据隐私。本论文中仅使用全局测试集,即每个客户端仅持有本地训练集。
实现细节(Implementation Details)
我们使用预训练的 CLIP(ViT-B/16)提取视觉与文本特征,嵌入维度 D = 512 D=512 D=512。Prompt 生成器由一个四头 Cross-Attention、LayerNorm 以及一个线性投影层组成,嵌入维度同样为 512。我们在单张 NVIDIA RTX 3090 GPU 上使用 PyTorch 进行训练,batch size 设为 128,学习率为 1 × 1 0 − 5 1\times10^{-5} 1×10−5。全局聚合轮数为 15,每轮本地训练 epoch 为 10。
在不同划分策略上的对比(Comparisons on Different Data Splits)
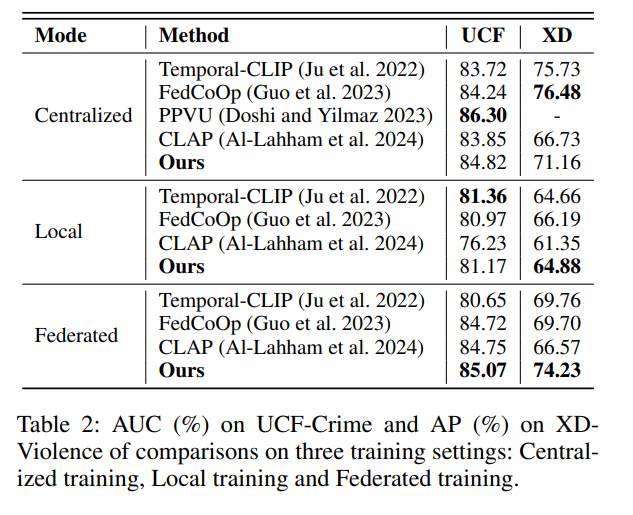
表 1 显示了在 UCF-Crime 和 XD-Violence 上,分别以随机划分、事件划分和场景划分进行测试的结果。我们的方法相较于手工 Prompt 的 ZS-CLIP(Radford et al. 2021)和使用可学习 Prompt 向量的 FedCoOp(Guo et al. 2023)性能更优,说明我们提出的 Prompt 生成器在联邦学习环境中更具灵活性。
此外,我们的方法相比于其他联邦 WSVAD 方法如 PPVU(Doshi and Yilmaz 2023)和 CLAP(Al-Lahham et al. 2024)表现更佳。PPVU 基于 Transformer,在联邦环境中仅训练分类器;CLAP 利用聚类生成伪标签,但只考虑视觉信息,忽视联邦学习中泛化与个性化的平衡。而我们的方法结合视觉-语言关联性与上下文调控,在全局泛化与局部个性化之间做出更优权衡。
在不同训练设定下的对比(Comparisons on Different Training Settings)
表 2 显示了我们方法在集中式、本地和联邦训练三种设定下的性能。为保证公平性,我们对比方法均在三种设定下重新实现。
- 一方面,希望联邦训练尽可能逼近集中式训练性能,后者具有全局泛化能力;
- 另一方面,虽然本地训练具有隐私保护优势,但若每个客户端只训练本地模型,则其在全局测试集上的表现通常不佳。
作为折中方案,联邦训练既聚合了全局性能,又保留了本地数据隐私。与本地训练相比,我们在 UCF-Crime 和 XD-Violence 上分别获得了 2.89% AUC 和 10.44% AP 的提升。由于我们的 Prompt 生成器同时受全局和局部上下文驱动,特别适合联邦学习,因此在集中式训练中可能略显劣势。
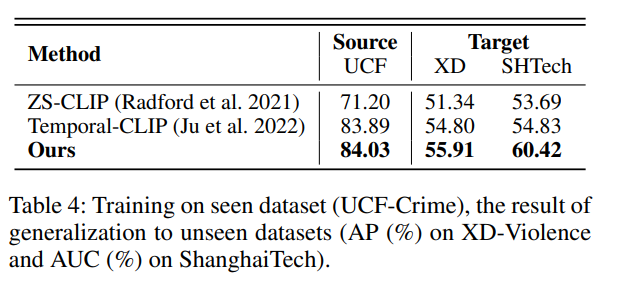
泛化能力评估(Generalization to Unseen Datasets)
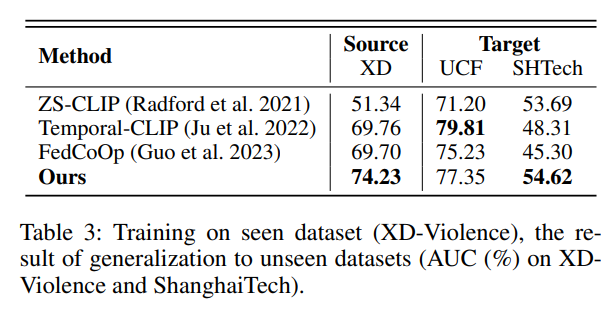
我们评估了模型对未见数据集的泛化能力。具体做法是在 UCF-Crime 或 XD-Violence 上进行联邦训练,在 ShanghaiTech 测试集上进行测试。
- 表 3 显示在 XD-Violence 上训练后,在未见数据集上的测试结果;
- 表 4 显示在 UCF-Crime 上训练后的测试结果。
我们方法在 ShanghaiTech 上分别取得了 54.62% 和 60.42% 的 AUC,平均超越 ZS-CLIP 与 Temporal-CLIP 分别为 3.83% 和 9.32%。这种泛化能力来自两个方面:
- CLIP 的预训练模型提供了稳健的语义特征表示;
- 我们提出的 Prompt 生成器由全局与局部上下文共同驱动,其中全局上下文激活了模型对未见类别的识别能力。
好的,以下是论文的 消融实验(Ablation Studies) 和 可视化分析(Qualitative Analyses) 部分的完整翻译,继续保持学术风格和 KaTeX 格式。
消融实验(Ablation Studies)
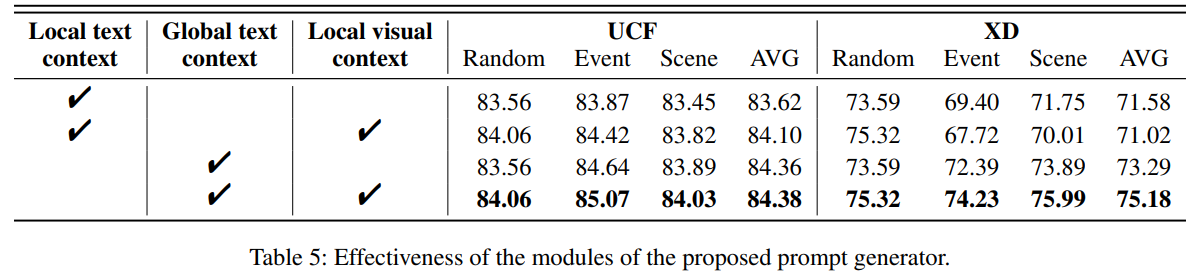
在本节中,我们重点评估所提方法中各个模块的有效性,实验结果如表 5 所示。
首先,我们比较了**局部文本上下文(Local Text Context)与全局文本上下文(Global Text Context)**的差异。类似于 FedTPG(Qiu et al. 2024),当仅提供当前客户端所拥有的类别文本作为 Prompt 生成上下文时,在 UCF-Crime 和 XD-Violence 上的平均性能分别下降了 0.28%(AUC)和 4.16%(AP)。这是因为全局上下文能提供完整的任务相关信息,而局部上下文则相对有限,难以提供任务的全面语义表示。
需要注意的是,在**随机划分(random split)**下,局部上下文和全局上下文在本质上是一致的,因此这两种设置在该场景下没有差异。
其次,我们评估了**局部视觉上下文(Local Visual Context)**的作用。将局部视觉上下文替换为一组可学习向量时,在 XD-Violence 上平均性能下降了 1.89%(AP)。这是因为在缺乏局部视觉信息的引导下,模型难以适应本地数据分布。
可视化分析(Qualitative Analyses)
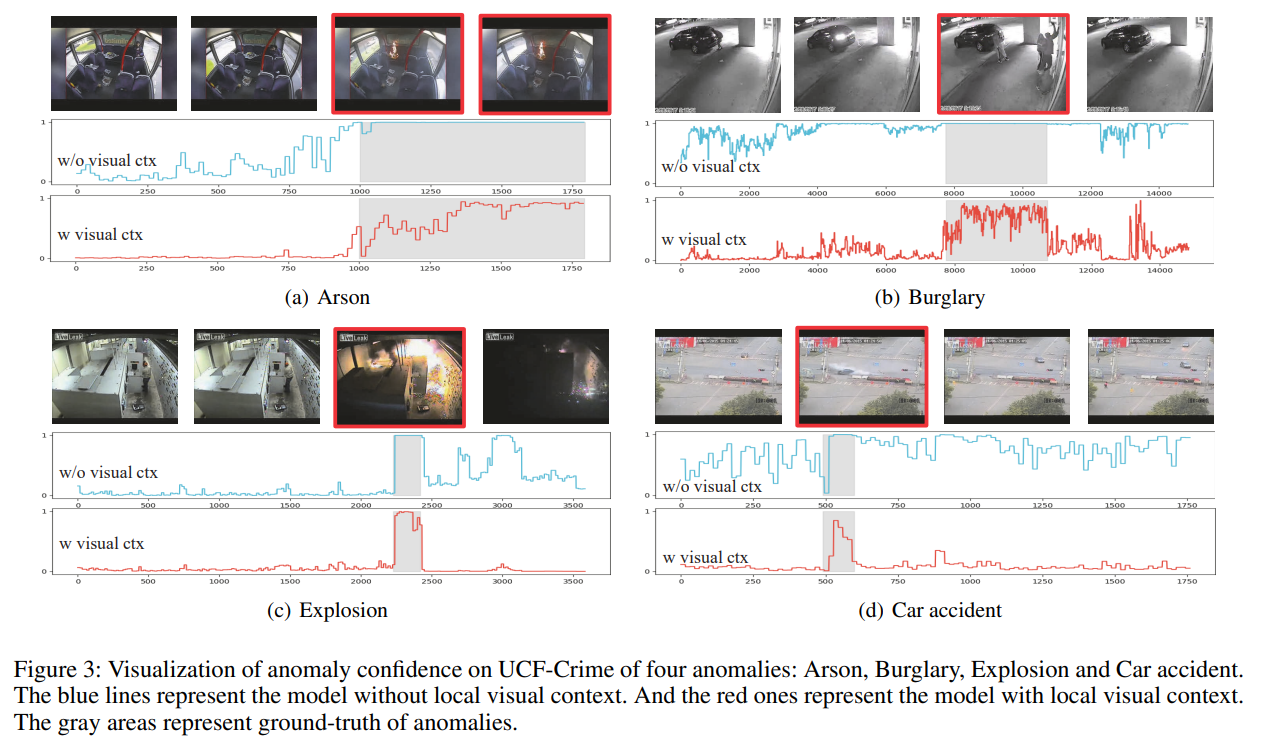
图 3 展示了我们在 UCF-Crime 数据集上四类异常事件的可视化异常置信度:纵火(Arson)、入室盗窃(Burglary)、爆炸(Explosion)和车祸(Car Accident)。
- 蓝色曲线表示不使用局部视觉上下文的模型;
- 红色曲线表示结合局部视觉上下文与全局文本上下文的模型;
- 灰色区域表示异常事件的真实发生区间(Ground Truth)。
从图中可以观察到:
- 未使用局部视觉上下文时,模型在正常帧上有时会产生较高的异常置信度,即误报率较高;
- 结合局部视觉上下文时,模型的异常置信度曲线更加平滑,对异常事件的定位更加准确,误报率显著降低。
这进一步验证了我们所提出的局部视觉上下文驱动 Prompt 生成器的有效性。
结论(Conclusion)
在本工作中,我们提出了一个基于全局与局部上下文驱动的联邦学习框架,用于隐私保护的视频异常检测。具体而言:
- 我们利用 CLIP 的视觉-语言关联能力进行异常检测;
- 为了在联邦学习环境中保留 CLIP 的强大表达能力,我们提出了一种动态 Prompt 生成器,替代手工设计的文本模板;
- 此外,为了在联邦环境下兼顾全局泛化能力与局部个性化适应性,我们设计了一个结合全局文本上下文与局部视觉上下文的 Prompt 学习策略。
在这两种上下文的共同驱动下,所生成的 Prompt 更适用于联邦环境,具备更强的表达力与适应性。
未来,我们将继续探索**隐私保护的视频异常检测(VAD)**方法。