SpringBoot集成Kafka详解
在Spring Boot项目中集成Kafka,首先需要确保Kafka服务器已经启动并正常运行。然后,通过引入 Kafka依赖,编写yml配置,创建Kafka生产者和消费者。最后通过接口调用,实现消息发送和消费。
一、pom依赖
| <!--kafka--> <!--注意版本冲突--> |
二、yml配置
| spring: kafka: bootstrap-servers: localhost:9092 # Kafka集群地址 # 生产者配置 producer: compression-type: gzip # 默认不压缩,可选值:"gzip", "snappy", "lz4", "zstd" acks: all # 确认机制 retries: 3 # 发送失败后重试次数 retry-backoff-ms: 500 # 每次重试之间的间隔时间(单位:毫秒) enable-idempotence: true # 启用幂等性 linger-ms: 5 # 延迟发送的时间,单位毫秒,默认 0ms(立即发送) batch-size: 32768 # 生产者每个批次发送的最大字节数,默认 16KB buffer-memory: 67108864 # 生产者缓冲区内存大小,单位字节,默认32MB key-serializer: org.apache.kafka.common.serialization.StringSerializer # 键的序列化器 value-serializer: org.apache.kafka.common.serialization.StringSerializer # 值的序列化器 transactional-id-prefix: tx- # 启用事务时的前缀,用于事务标识 # 生产者拦截器,用于记录日志和指标收集 interceptors: - org.apache.kafka.clients.producer.internals.LogAndMetricsProducerInterceptor # 消费者配置 consumer: group-id: my-consumer-group # 消费者组ID concurrency: 10 # 设置消费者并发数 enable-auto-commit: false # 禁用自动提交,手动提交偏移量 auto-offset-reset: earliest # 如果偏移量无效则从最早的消息开始消费。可选"latest" session-timeout-ms: 10000 # session会话超时时间(与心跳有关) max-poll-records: 1000 # 每次poll的最大记录数 max-poll-interval-ms: 300000 # 最大轮询间隔 ,确保消费者不会在空闲期间超时 fetch-max-wait-ms: 300 # 拉取消息时的最大等待时间 fetch-max-bytes: 104857600 # 拉取的最大字节数,单位字节 fetch-min-size: 5000 # 拉取消息时的最小字节数,单位字节 key-deserializer: org.apache.kafka.common.serialization.StringDeserializer # 键的反序列化器 value-deserializer: org.apache.kafka.common.serialization.StringDeserializer # 值的反序列化器 isolation-level: read_committed # 事务隔离级别,确保读取已提交的数据。可选 "read_uncommitted" # Admin配置,用于创建和管理Kafka的主题 admin: bootstrap-servers: localhost:9092 # Kafka集群地址 default-topic: partitions: 5 # 默认主题的分区数 replication-factor: 3 # 默认主题的副本数 # 副本机制 replication: # 副本落后超过此时间(毫秒)会被移出 ISR 列表 replica_lag_time_max_ms: 10000 # 默认为 10000 毫秒,即 10 秒 # 最少需要多少个同步副本才能进行写入 min_insync_replicas: 2 # 默认为 1,根据需求设置 # 是否允许在没有足够 ISR 的情况下进行领导者选举 unclean_leader_election_enable: false # 默认为 false,防止数据丢失 # 监听器的配置 listener: concurrency: 10 # 设置监听器的并发数,控制消费者的并发线程数 ack-mode: manual # 手动确认消息,默认是 "auto" 自动确认 poll-timeout: 3000 # 拉取消息的超时时间,单位毫秒 missing-topics-fatal: false # 是否忽略主题缺失的错误,默认是false container-factory: kafkaListenerContainerFactory # 默认监听器容器工厂 # 错误处理配置 error-handler: # 在消息消费出错时重试的配置 retry: max-attempts: 3 # 最大重试次数 initial-interval: 1000 # 初始重试间隔,单位毫秒 multiplier: 1.5 # 重试间隔的增量倍数 #日志段和日志保留配置 log: # 设置每个日志段的大小 segment: bytes: 1073741824 # 每个日志段的大小,默认为 1GB # 设置日志保留时间(毫秒) retention: ms: 604800000 # 7天,单位是毫秒 # 设置日志的最大保留大小 retention_bytes: 10737418240 # 默认为 10GB # 设置日志清理策略(delete 或 compact) cleanup_policy: "delete" # 可选:delete 或 compact # 设置日志索引间隔大小 index_interval_bytes: 4096 # 默认为 4096 |
三、KafkaConfig(可选)
| @Configuration public class KafkaConfig { @Bean public KafkaTemplate<String, String> kafkaTemplate(ProducerFactory<String, String> producerFactory) { return new KafkaTemplate<>(producerFactory); } @Bean public ProducerFactory<String, String> producerFactory() { Map<String, Object> configProps = new HashMap<>(); configProps.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); configProps.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class); configProps.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class); return new DefaultKafkaProducerFactory<>(configProps); } } |
四、KafkaProducer
在Spring Boot中创建Kafka生产者,向Kafka主题发送消息。
1.KafkaTemplate<String, String>
Spring Kafka提供的用于生产消息的模板类。
2.sendMessage()
向指定的Kafka主题(test_topic)发送消息。
| @Service public class KafkaProducer { private final KafkaTemplate<String, String> kafkaTemplate; public KafkaProducer(KafkaTemplate<String, String> kafkaTemplate) { this.kafkaTemplate = kafkaTemplate; } public void sendMessage(String topic, String message) { kafkaTemplate.send(topic, message); } } |
五、KafkaConsumer
编写Kafka消费者来接收消息。
1.@KafkaListener
用于指定消费的主题及消费者组。
2.consumeMessage()
将会接收到来自test_topic主题的消息,并将其打印出来。
| @Service public class KafkaConsumer { // 监听test主题的消息 @KafkaListener(topics = "test", groupId = "my-consumer-group") public void consumeMessage(String message) { System.out.println("Received Message in group my-group: " + message); } } |
六、自定义调用
在启动类中,使用CommandLineRunner来在应用启动时发送一条消息。
| @SpringBootApplication public class KafkaApplication { public static void main(String[] args) { SpringApplication.run(KafkaApplication.class, args); } @Bean public CommandLineRunner demo(KafkaProducer producer) { return (args) -> { producer.sendMessage("Hello, Kafka!"); // 启动时发送一条消息 }; } } |
七、注意事项
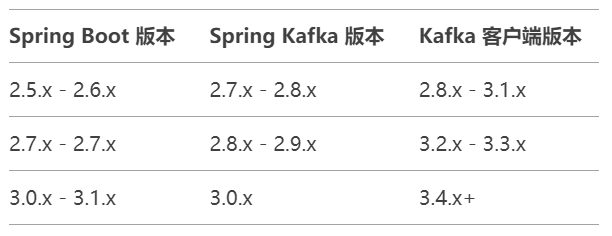
根据你的 Spring Boot 版本,选择兼容的 Kafka 依赖版本:
八、总结
在Spring Boot项目中集成Kafka,首先需要确保Kafka服务器已经启动并正常运行。然后,通过引入 Kafka依赖,编写yml配置,创建Kafka生产者和消费者。最后通过接口调用,实现消息发送和消费。