Transformer系列(二):自注意力机制框架
自注意力机制框架
- 一、K-Q-V的自注意力机制
- 二、位置表征
- 1. 通过学习嵌入来进行位置表征
- 2. 通过直接改变 α \alpha α来进行位置表征
- 三、逐元素非线性变换
- 四、未来掩码(future mask)
- 五、总结
上篇博客:NLP中放弃使用循环神经网络架构讲解了循环神经网络在处理更长的序列或句子时存在很多问题,于是学者们开发了注意力机制来解决该问题。
广义上,注意力机制是一种处理查询的方法,它通过选取与查询最为相似的键所对应的值,来在键值存储中柔和地查找信息。这里所说的“选取”和“最为相似”,指的是对所有值进行加权平均,对于那些与查询更为相似的键所对应的值赋予更大的权重。在自注意力机制中,我们指的是使用与定义键和值相同的元素来帮助我们定义查询。
在本节中,我们将讨论如何使用一些方法来开发上下文表示,在这些方法中,实现上下文关联的主要机制不是循环,而是注意力机制。
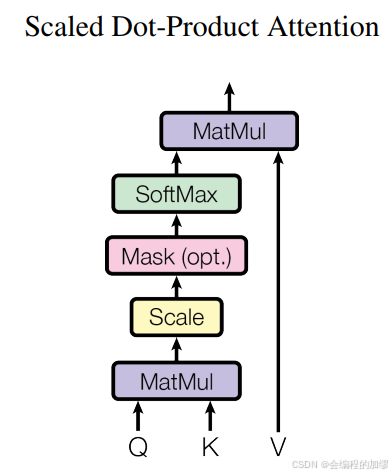
一、K-Q-V的自注意力机制
自注意力机制有多种形式;我们在此要讨论的这种形式目前是最受欢迎的。它被称为键-查询-值自注意力机制(key-query-value)。
考虑序列 x 1 : n x_{1:n} x1:n中的一个词元 x i x_{i} xi。基于它,对于矩阵 Q ∈ R d × d Q\in\mathbb{R}^{d\times d} Q∈Rd×d,我们定义一个查询 q i = Q x i q_{i} = Qx_{i} qi=Qxi。然后,对于序列中的每个词元 x j ∈ { x 1 , … , x n } x_{j}\in\{x_{1},\ldots,x_{n}\} xj∈{x1,…,xn},我们使用另外两个权重矩阵以类似的方式分别定义一个键和一个值:对于 K ∈ R d × d K\in\mathbb{R}^{d\times d} K∈Rd×d和 V ∈ R d × d V\in\mathbb{R}^{d\times d} V∈Rd×d,有 k j = K x j k_{j}=Kx_{j} kj=Kxj以及 v j = V x j v_{j}=Vx_{j} vj=Vxj 。
我们对词元 x i x_{i} xi的上下文表示 h i h_{i} hi是该序列中各个值的线性组合(也就是加权和):
h i = ∑ j = 1 n α i j v j ( 1 ) h_{i}=\sum_{j=1}^n\alpha_{ij}v_{j} \quad (1) hi=j=1∑nαijvj(1)
其中,权重 α i j \alpha_{ij} αij控制着每一个值 v j v_{j} vj的贡献程度。这一点可以从下图中看出,对making贡献较多的词是more和difficult
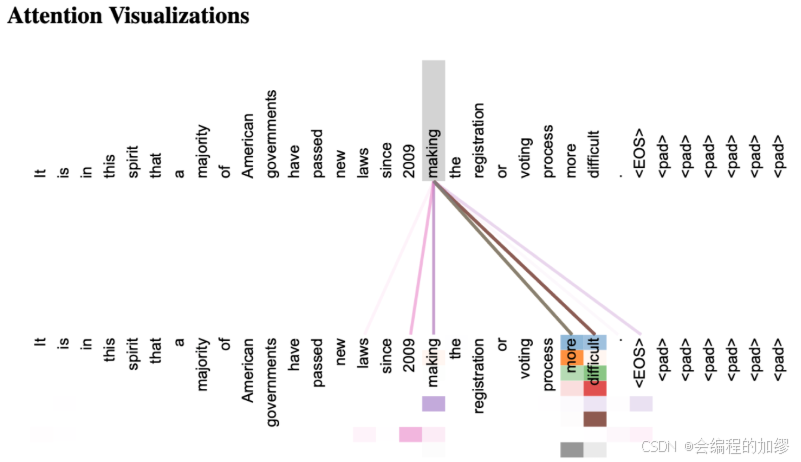
图片来源:Understanding and Coding the Self-Attention Mechanism of Large Language Models From Scratch
回到我们关于键值存储的类比, α i j \alpha_{ij} αij 以一种柔和的方式选择要查找的数据。我们通过计算键与查询之间的亲和度 q i ⊤ k j q_{i}^{\top}k_{j} qi⊤kj来定义这些权重,然后在整个序列上计算 softmax 函数:
α i j = exp ( q i T k j ) ∑ j ′ = 1 n exp ( q i T k ′ ) (2) \alpha_{ij}=\frac{\exp(q_{i}^Tk_{j})}{\sum _{j'=1}^n\exp(q_{i}^Tk')} \tag{2} αij=∑j′=1nexp(qiTk′)exp(qiTkj)(2)
⭐ 所以每个值的权重其实是键和查询的softmax函数,softmax得到的便是一个概率向量(也可以理解为权重向量)
直观上看,该操作通过选取元素 x i x_{i} xi,并在 x i x_{i} xi所在的序列 x 1 : n x_{1:n} x1:n中查找,以确定应该使用来自其他哪些词元的哪些信息,来在上下文中表示 x i x_{i} xi。 从直观上看,矩阵 K K K、 Q Q Q和 V V V的使用,让我们能够针对键、查询和值这三种不同的角色,对词元 x i x_{i} xi采用不同的 “视角” 来进行处理。我们执行这样的操作,从而为所有属于集合 { 1 , … , n } \{1, \ldots, n\} {1,…,n} 的 i i i(即序列中的每一个位置)构建对应的上下文表示 h i h_{i} hi。
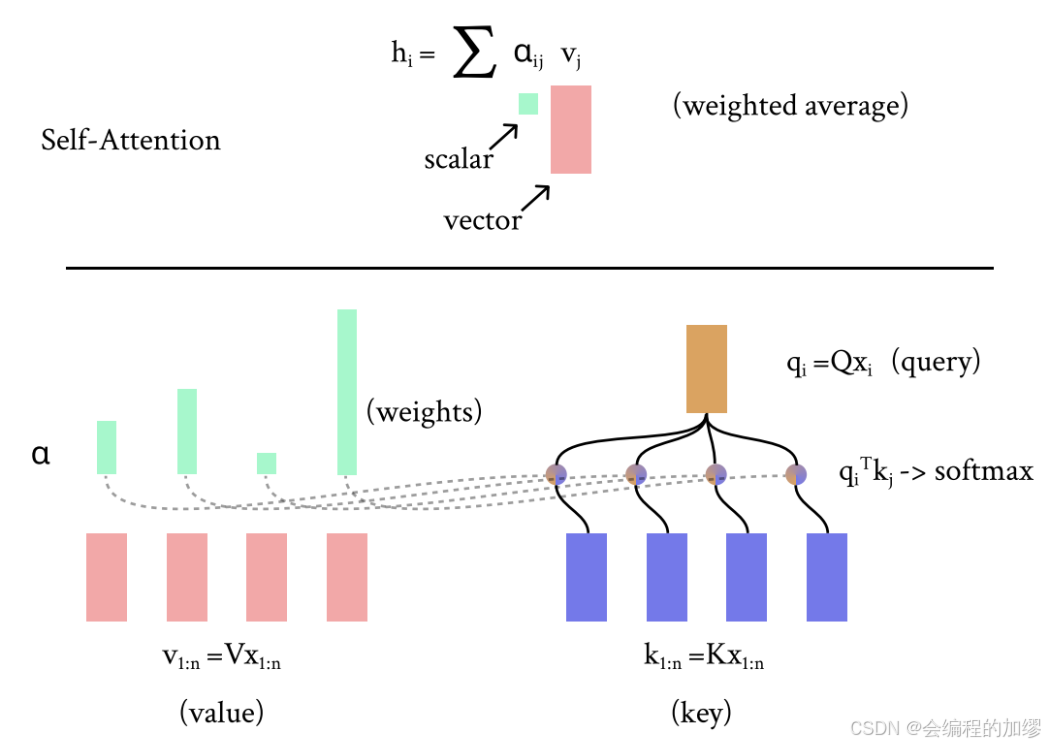
所以 q i T k j q_{i}^Tk_{j} qiTkj是为了得到value的权重,来计算出 x i x_i xi的上下文表征 (所对应的隐向量表征 h i h_{i} hi)
二、位置表征
以“the oven cooked the bread so”(烤箱烤了面包,就这样)这个序列为例。正如你可能猜到的,这与“the bread cooked the oven so”(面包烤了烤箱,就这样)是不同的序列。前一个句子表达的是我们做出了美味的面包,而后者我们可能会理解为面包不知怎么把烤箱弄坏了。
在循环神经网络中,序列的顺序决定了展开的顺序,所以这两个序列有不同的表示。而在自注意力操作中,并没有内置的顺序概念。
⭐ 自注意力操作没有内置的序列顺序概念。
为了理解这一点,让我们来看一下对这个序列进行的自注意力操作。对于“the oven cooked the bread so”这个序列,我们有一组向量 x 1 : n x_{1:n} x1:n,可以将其写为: x 1 : n = [ x t h e ; x o v e n ; x c o o k e d ; x t h e ; x b e ; x s o ] ∈ R 5 × d ( 3 ) x_{1:n} = [x_{the}; x_{oven}; x_{cooked}; x_{the}; x_{be}; x_{so}] \in \mathbb{R}^{5×d} \quad (3) x1:n=[xthe;xoven;xcooked;xthe;xbe;xso]∈R5×d(3)
因此,权重 α s o , 0 \alpha_{so, 0} αso,0(即我们查找第一个单词的权重,通过写出softmax公式可得)为: α s o , 0 = exp ( q s o ⊤ k t h e ) exp ( q s o ⊤ k t h e ) + ⋯ + exp ( q s o ⊤ k b r e a d ) ( 4 ) \alpha_{so, 0}=\frac{\exp(q_{so}^{\top}k_{the})}{\exp(q_{so}^{\top}k_{the}) + \cdots + \exp(q_{so}^{\top}k_{bread})} \quad(4) αso,0=exp(qso⊤kthe)+⋯+exp(qso⊤kbread)exp(qso⊤kthe)(4)
计算第一个单词的权重 softmax(qk)
所以, α ∈ R 5 \alpha\in\mathbb{R}^{5} α∈R5是我们的权重,我们用这些权重按照公式7计算加权平均值,从而得到 h s o h_{so} hso
h s o = α s o , 0 v t h e + α s o , 1 v o v e n + α s o , 2 v c o o k e d + α s o , 3 v t h e + α s o , 4 v b e + α s o , 5 v s o h_{so}=\alpha_{so,0}v_{the}+\alpha_{so,1}v_{oven}+\alpha_{so,2}v_{cooked}+\alpha_{so,3}v_{the}+\alpha_{so,4}v_{be}+\alpha_{so,5}v_{so} hso=αso,0vthe+αso,1voven+αso,2vcooked+αso,3vthe+αso,4vbe+αso,5vso
对于重新排序后的句子“the bread cooked the oven”,注意 α s o , 0 \alpha_{so, 0} αso,0是相同的。分子没有变化,分母也没有变化;我们只是重新排列了求和中的项。同样地,对于 α s o , b r e a d \alpha_{so,bread } αso,bread和 α s o , o v e n \alpha_{so,oven } αso,oven,你可以计算得出,它们也与序列的顺序无关,是相同的。这一切都归结于两个事实:
- x x x的表示与位置无关,对于任何单词 w w w,它都只是 E w Ew Ew;
- 自注意力操作与位置无关。
⭐ 非上下文嵌入词 x i = E w i x_{i}=Ew_{i} xi=Ewi与词在序列 w 1 : n w_{1:n} w1:n中的位置无关,仅取决于词汇表 V V V中该词的身份。
1. 通过学习嵌入来进行位置表征
为了在自注意力机制中表示位置信息,可以:
(1)使用本身就依赖于位置的向量作为输入;
(2)改变自注意力操作本身。
一种常见的解决方案是对(1)的简单实现。我们设定一个新的参数矩阵 P ∈ R N × d P \in \mathbb{R}^{N ×d} P∈RN×d,其中 N N N是你的模型能够处理的任何序列的最大长度。
然后,我们只需将一个单词位置的嵌入表示添加到其词嵌入中:
x ~ i = P i + x i (5) \tilde{x}_{i}=P_{i}+x_{i} \tag{5} x~i=Pi+xi(5)
并像往常一样执行自注意力操作(即位置嵌入是在输入之前就已经嵌入了的)。现在,自注意力操作可以利用嵌入 P i P_{i} Pi,将处于位置 i i i的单词与处于其他位置的同一个单词区别看待。例如,在BERT论文[Devlin等人,2019]中就是这样做的.
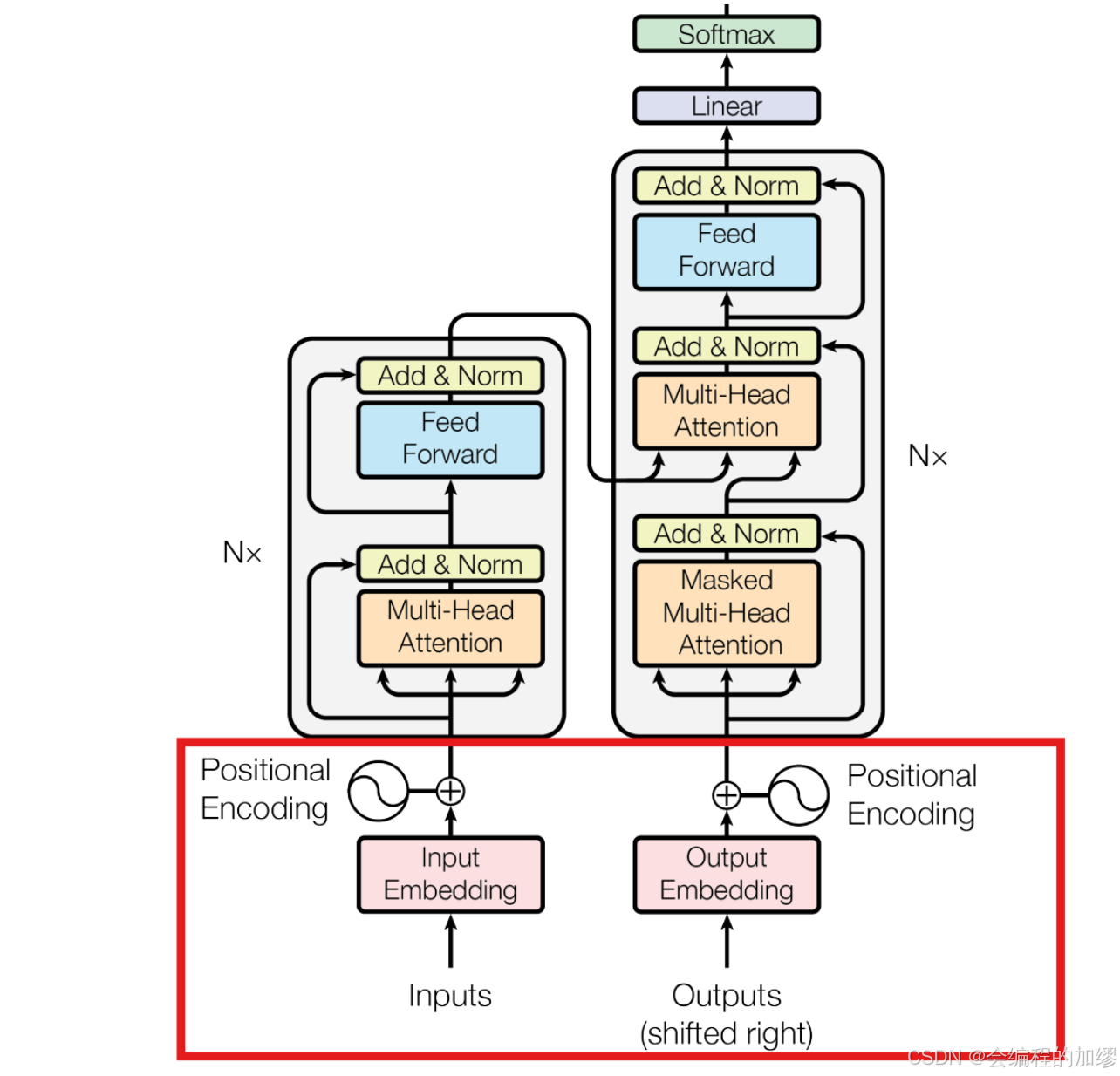
2. 通过直接改变 α \alpha α来进行位置表征
除了改变输入表示之外,我们还可以改变自注意力的形式,使其内置位置概念。一种直观的想法是,在其他条件相同的情况下,自注意力应该更多地关注 “附近 ”的词,而不是 “远处 ”的词。带线性偏差的注意力机制(Press等人,2022年)就是这一想法的一种实现方式。其一种实现方式如下:
α i = softmax ( k 1 : n q i + [ − i , . . . , − 1 , 0 , − 1 , . . . , − ( n − i ) ] ) (6) \alpha_{i} = \text{softmax}(k_{1:n}q_{i} + [-i, ..., -1, 0, -1, ..., -(n - i)]) \tag{6} αi=softmax(k1:nqi+[−i,...,−1,0,−1,...,−(n−i)])(6)
其中, k 1 : n q i ∈ R n k_{1:n}q_{i} \in \mathbb{R}^{n} k1:nqi∈Rn是原始的注意力分数,在其他条件相同的情况下,我们添加的偏差使注意力更多地集中在附近的词上,而不是远处的词上。从某种意义上说,这种方法能奏效很奇怪,但也很有趣!
三、逐元素非线性变换
想象一下,如果我们堆叠自注意力层,这是否足以替代堆叠的长短期记忆网络(LSTM)层呢?直观来看,缺少了标准深度学习架构中常见的逐元素非线性变换。实际上,如果我们堆叠两个自注意力层,得到的结果很像单个自注意力层:
o i = ∑ j = 1 n α i j V ( 2 ) ( ∑ k = 1 n α j k V ( 1 ) x k ) = ∑ k = 1 n ( α j k ∑ j = 1 n α i j ) V ( 2 ) V ( 1 ) x k = ∑ k = 1 n α i j ∗ V ∗ x k \begin{align*} o_{i} & =\sum_{j = 1}^{n} \alpha_{ij} V^{(2)}(\sum_{k = 1}^{n} \alpha_{jk} V^{(1)} x_{k})\\ & =\sum_{k = 1}^{n}(\alpha_{jk} \sum_{j = 1}^{n} \alpha_{ij}) V^{(2)} V^{(1)} x_{k}\\ & =\sum_{k = 1}^{n} \alpha_{ij}^{*} V^{*} x_{k} \end{align*} oi=j=1∑nαijV(2)(k=1∑nαjkV(1)xk)=k=1∑n(αjkj=1∑nαij)V(2)V(1)xk=k=1∑nαij∗V∗xk
其中 α i j ∗ = ( α j k ∑ j = 1 n α i j ) \alpha_{ij}^{*}=(\alpha_{jk} \sum_{j = 1}^{n} \alpha_{ij}) αij∗=(αjk∑j=1nαij),且 V ∗ = V ( 2 ) V ( 1 ) V^{*}=V^{(2)} V^{(1)} V∗=V(2)V(1)。所以,这只是对输入进行线性变换后的线性组合,和单层自注意力层很相似!这样就足够了吗?
💡和MLP中加激活函数不同,这里直接加了一个前馈网络。所以,每个注意力块后面都跟一个前馈网络。 |
在实践中,在自注意力层之后,通常会对每个词的表示独立应用前馈网络:
h F F = W 2 ReLU ( W 1 h self - attention + b 1 ) + b 2 (7) h_{FF}=W_{2} \text{ReLU}(W_{1} h_{\text{self - attention}} + b_{1}) + b_{2} \tag{7} hFF=W2ReLU(W1hself - attention+b1)+b2(7)
通常, W 1 ∈ R 5 d × d W_{1} \in \mathbb{R}^{5d ×d} W1∈R5d×d, W 2 ∈ R d × 5 d W_{2} \in \mathbb{R}^{d ×5d} W2∈Rd×5d。也就是说,前馈网络的隐藏层维度远大于整个网络的隐藏层维度 d d d,这样做是因为矩阵乘法是可以高效并行化的操作,因此是进行大量计算和设置参数的有效部分。
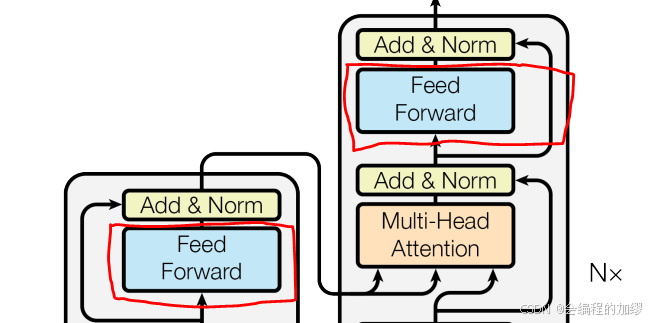
四、未来掩码(future mask)
在进行自回归语言建模时,我们根据目前已有的所有单词来预测下一个单词:
w t ∼ softmax ( f ( w 1 : t − 1 ) ) (18) w_{t} \sim \text{softmax}(f(w_{1:t - 1})) \tag{18} wt∼softmax(f(w1:t−1))(18)
其中 f f f是一个将序列映射到 R ∣ V ∣ \mathbb{R}^{|V|} R∣V∣向量的函数。
这个过程的一个关键方面是,在预测时我们不能查看未来的单词,否则这个问题就变得毫无意义。单向循环神经网络(RNN)中就内置了这个概念。如果我们想用RNN来实现函数 f f f,可以使用单词 w t − 1 w_{t - 1} wt−1的隐藏状态:
w t ∼ softmax ( h t − 1 E ) (19) w_{t} \sim \text{softmax}(h_{t - 1}E) \tag{19} wt∼softmax(ht−1E)(19)
h t − 1 = σ ( W h t − 2 + U x t − 1 ) (20) h_{t - 1}=\sigma(Wh_{t - 2}+Ux_{t - 1}) \tag{20} ht−1=σ(Wht−2+Uxt−1)(20)
通过RNN的展开过程可知,我们不会查看未来的单词(在这种情况下,未来的单词指的是 w t , . . . , w n w_{t}, ..., w_{n} wt,...,wn)。
在Transformer中,自注意力权重 α \alpha α并没有明确限制在表示第 i i i个词元时不能查看索引 j > i j>i j>i的词元。 在实际应用中,我们通过在softmax的输入中添加一个很大的负常数(或者等效地,当 j > i j>i j>i时将 α i j \alpha_{ij} αij设置为 0 0 0 )来强制实施这个约束。
α i j , masked = { α i j j ≤ i 0 否则 \alpha_{ij,\text{masked}} = \begin{cases} \alpha_{ij} & j \leq i \\ 0 & \text{否则} \end{cases} αij,masked={αij0j≤i否则
💡 似乎应该使用负无穷(-∞)作为常数,以“切实”确保无法看到未来的信息。然而,实际并非如此,人们会使用一个即使在“float16”编码的浮点范围内也算适中的常数,比如 -105。使用无穷大可能会导致非数字(NaNs),而且各个库对于无穷大输入的处理方式也不明确,所以我们倾向于避免使用它。由于精度有限,一个足够大的负常数仍然会将注意力权重精确设置为零。 |
从图中看,它就像图3所示。
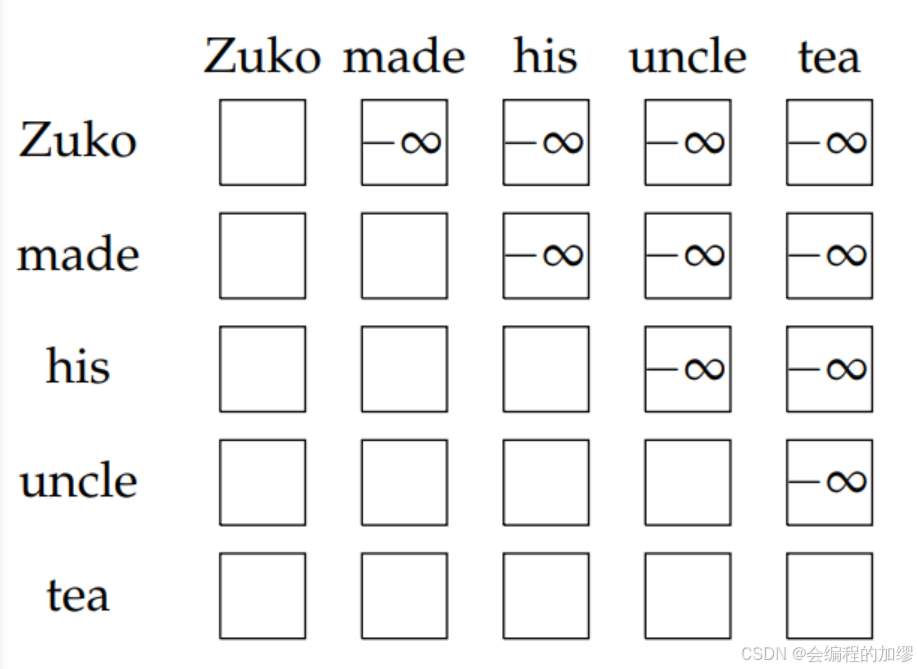
📔 图3:自注意力中自回归未来掩码示意图。每行中的单词都对未来的单词进行了掩码处理(例如,“Zuko”只能关注“Zuko”,而“made”可以关注“Zuko”和“made”)。
五、总结
我们的最简单自注意力架构包含:
(1)自注意力操作;
(2)位置表示;
(3)逐元素非线性变换;
(4)(在语言建模场景下的)未来掩码机制。
直观地说,这些是需要理解的主要部分。然而,截至2023年,自然语言处理中使用最广泛的架构是Transformer,它由[Vaswani等人,2017年]提出,包含许多非常重要的组件。所以现在我们将深入探讨该架构的细节。