Versal Adaptive SoC AI Engine 知识分享6
AI Engine 架构(续)
5.标量单元
下图显示了标量单元的框图,包括标量寄存器文件和标量功能单元。
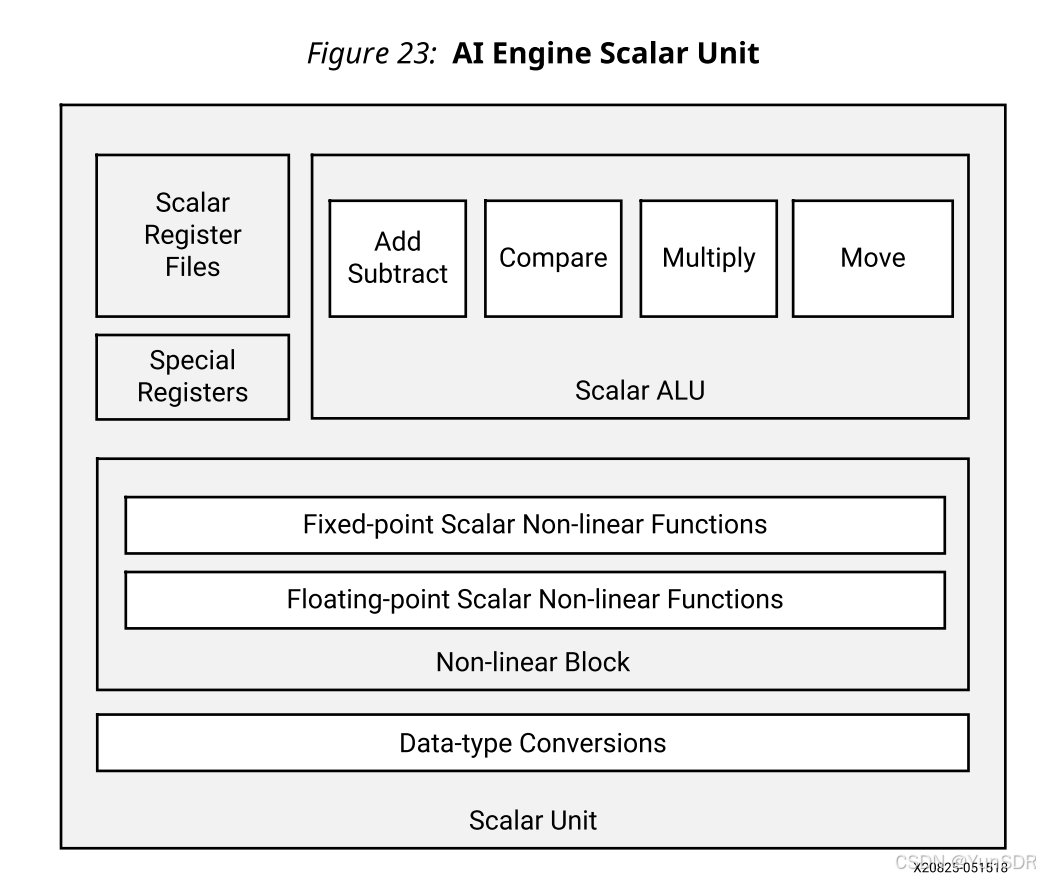
标量单元包含以下功能块。
•寄存器文件和特殊寄存器
•算术和逻辑单元(ALU)
•非线性函数-定点和浮点精度
•数据类型转换
加法、减法、比较和移位函数是单周期操作。整数乘法运算具有三个周期的延迟。非线性函数需要一个或四个周期来产生标量结果。上述操作的吞吐量是一个周期。
算术逻辑单元、标量函数和数据类型转换
AI引擎中的算术逻辑单元(ALU)管理以下操作。在所有情况下,发行率都是每个周期一条指令。
•整数加减法:32位。该操作具有一个周期延迟。
•32位整数的逐位逻辑运算(BAND、BOR、BXOR)。该操作具有一个周期延迟。
•乘法:32 × 32位,32位的输出结果存储在R寄存器文件中。该操作具有三个周期的延迟。
•移位操作:支持左右移位。正移位量用于左移位,负移位量用于右移位。移位量通过通用寄存器。移位操作的一位操作数指示需要正移位还是负移位。该操作具有一个周期延迟。AI引擎中有两种类型的标量初等函数:定点和浮点。下面介绍每个功能。
•定点非线性函数
○正弦和余弦:
-输入来自32位输入的高20位
-输出是具有高16位正弦和低16位余弦的级联字
-操作具有四个周期延迟
○绝对值(ABS):将输入数反转并加一。该操作具有一个周期延迟
○计数前导零(CLZ):计数32位输入中的前导零。操作具有一个周期延迟
○最小值/最大值(小于(LG)/大于(GT)):比较两个输入以找到最小值或最大值。该操作具有一个周期延迟
○平方根、平方根倒数和倒数:这些操作以浮点精度实现。对于定点实现,需要首先将输入转换为浮点精度,然后作为输入传递给这些非线性操作。此外,输出为浮点格式,需要转换回定点整数格式。操作具有四个周期的延迟
•浮点非线性函数
○平方根:输入和输出都是在R寄存器文件上操作的单精度浮点数。该操作具有四个周期的延迟
○平方根倒数:输入和输出都是在R寄存器文件上操作的单精度浮点数。该操作具有四个周期的延迟
○反转:输入和输出都是在R寄存器文件上操作的单精度浮点数。该操作具有四个周期延迟
○绝对值(ABS),该操作具有一个周期延迟
○最小值/最大值,该操作具有一个周期延迟。
标量单元中没有浮点单元,浮点运算是通过仿真来支持的。通常,优选地以向量单元执行加法和乘法。
AI Engine标量单元支持数据类型转换操作,将输入数据从定点转换为浮点,以及从浮点转换为定点。fix2float操作和float2fix操作支持输入为32位值的可变小数点。沿着输入,小数点位置也作为另一个输入。如果需要,这些操作会放大或缩小值。两个操作都有一个周期的延迟。AI Engine浮点并不完全符合IEEE标准,并且对一组功能有限制。本节概述了例外情况。
•当使用非常大的正数或负数调用float 2fix函数并且附加指数增量大于零时,指令返回0而不是正确的饱和值231-1或-231。float 2fix函数接受两个输入参数:
○ n:要转换的浮点输入值。
○ sft:6位有符号数,表示定点表示中的小数位数(从-32到31)。考虑以下两种情况:
○如果n*2sft > 2129,则输出应返回0x 7 FFFFFFF。相反,它返回0x 0000000。
○如果n*2sft <-2129,则输出应返回0X 80000000。相反,它返回0x 0000000。一般来说,对于sft > 0,应确保n浮点输入值保持在-2(129-sft)< n < 2(129-sft)的无错误范围内。这里引入了两种实现来提供解决方法:
○ float2fix_safe:如果指定float 2fix而没有任何选项,这是默认模式。该实现返回任何范围的正确值,但速度较慢。
○ float2fix_fast:这个实现只在没有bug的范围内返回正确的值,你需要确保这个范围是有效的。要选择floatfix_fast实现,您需要将预处理器FLOAT2FIX_FAST添加到项目文件中。
•定点值的法律的范围为-231到231-1。当float 2fix函数返回值-231时,该值在范围内,但溢出异常设置不正确。此溢出异常没有解决方法。
6.Vector Unit
(1)定点向量单元
定点向量单元包含三个单独且基本上独立的数据路径。
•乘法累加器(MAC)路径:主乘法路径从向量寄存器读取值,以用户可控的方式排列它们,执行可选的预加,将它们相乘,并且在一些后加之后,将它们累加到累加器寄存器的先前值。
•升档路径:该路径与MAC路径并行运行。它从MAC路径中的置换单元或向量寄存器读取数据,左移,并将其馈送到累加器寄存器。
•移位循环饱和(SRS)路径:该路径从累加器寄存器读取并存储到向量寄存器或数据存储器。之所以需要它,是因为每个通道的寄存器宽度为48或80位,而向量寄存器和数据存储器的宽度为8、16、32或64位2的幂。SRS单元使用饱和和舍入控制寄存器MD及其字段Q和R来影响其行为,并使用状态寄存器MC来向环境提供信息。移位控制寄存器S确定移位量。该单元支持基于寄存器MD中的字段R的值的各种舍入模式。如果R设置为0,则在LSB侧截断该值。如果R设置为1,则会实现上限行为,这意味着没有实际舍入。对于R = 2至7,模式分别为PosInf、NegInf、SymInf、SymZero、ConvEven和ConvOdd。
下图是主乘法和升档路径的流水线图,在指令解码阶段(ID)之后,六个执行阶段编号为E1至E6。深灰色的盒子,总是跨越两个阶段,是寄存器。可以跨越多个阶段的浅灰色框是功能单元。白色框表示处理器描述内部的硬件寄存器。所有框之间有箭头连接器。它们是nML传输器,是纯粹的非存储线。除了图中所示的元件之外,还有多路复用器,它们根据所执行的指令实现不同的连接。至UPS单元意味着在三个置换单元和VD寄存器之间进行选择的多路复用器。有一个内部单元读取输入,并在将数据输出到UPS单元之前预加两个值。
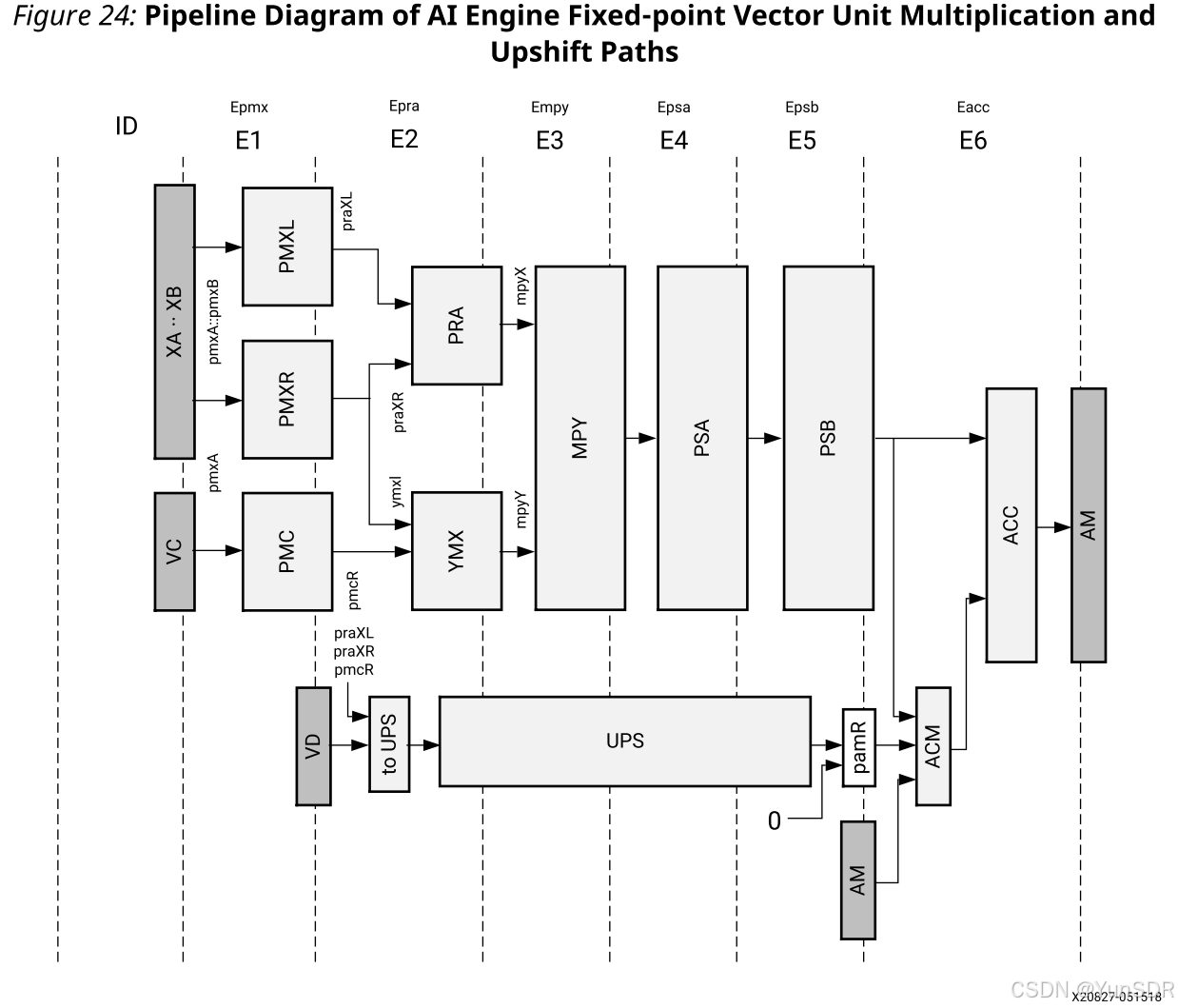
下表显示了主乘法路径中的功能单元。预加单元PRA也可以用于执行一些向量基本功能,例如确定两个向量的最小值或最大值或比较两个向量。在这些情况下,预加法器(PRA)被配置为减法,并且检查符号位以选择所选择的输入(对于MIN和MAX),并且还写入寄存器R以进行纯向量比较。

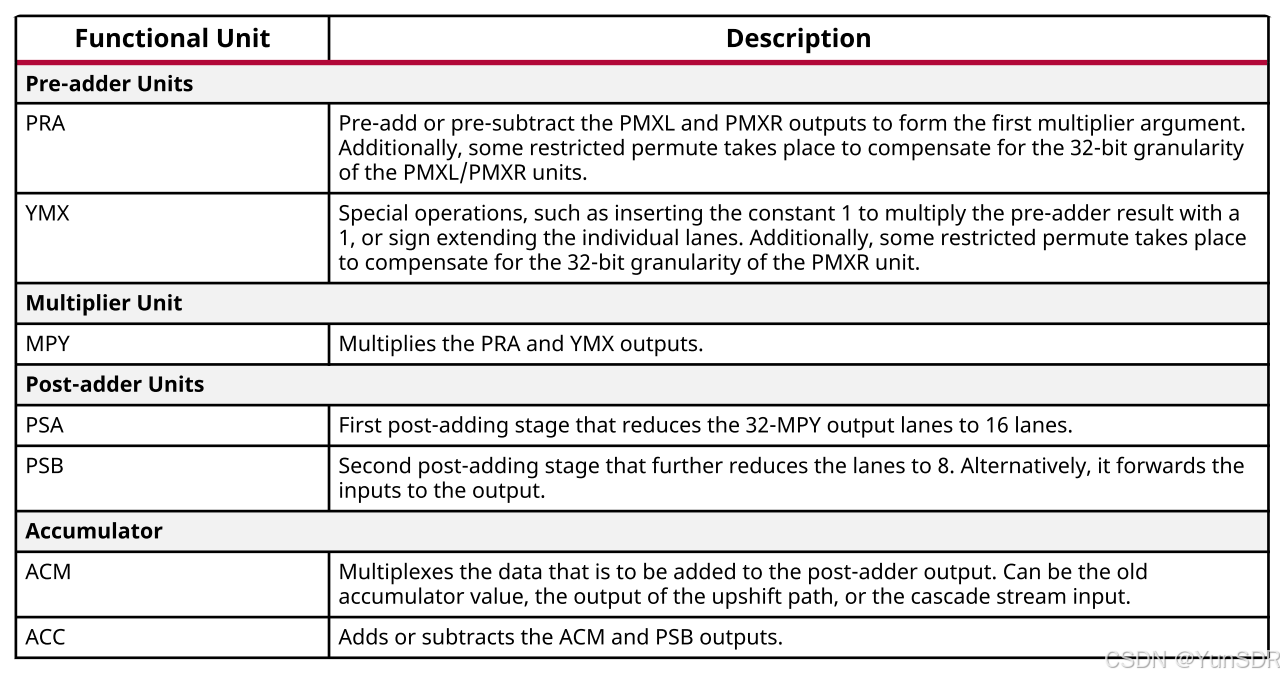
下表显示了升档路径中的功能单元。

下图是移位-舍入-饱和路径的流水线图。读取累加器寄存器,进行移位-舍入-饱和操作,输出写入任何向量寄存器或数据存储器。该值在E3阶段存储在存储器中,并在E6阶段到达存储器。
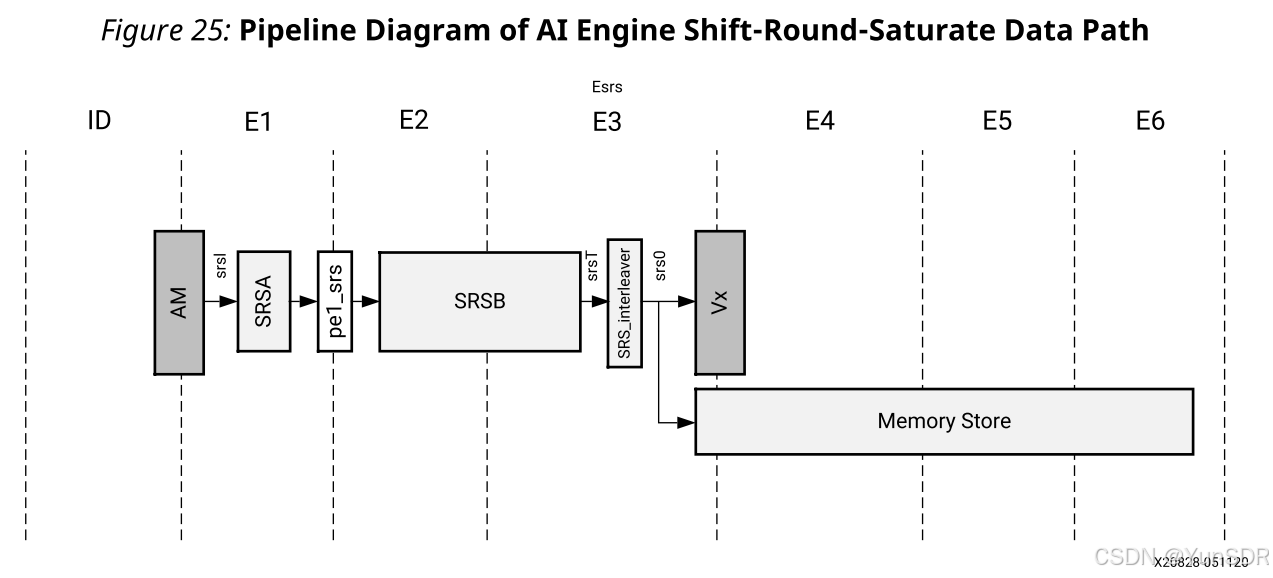 下表显示了移位-循环-饱和路径中的功能单元。
下表显示了移位-循环-饱和路径中的功能单元。

(2)浮点向量单元
AI引擎提供八个单精度浮点乘法和累加通道。该单元重用向量寄存器文件和定点数据路径的置换网络。通常,每个周期只能执行一条定点或浮点向量指令。
下图显示了单精度浮点数据流的管道图。与定点矢量单元相比,仅使用PMXL和PMC单元(PMXR单元被移除)。FPYMX是YMX的风格,FPYMX和PMXL的结果被转发到一个单精度乘法器单元(FPMPY),可以并行计算八个产品。FPMPY中的操作具有三个周期的延迟和一个周期的吞吐量。接下来,有一个FPSGN单元,它允许在每个通道的基础上对结果进行符号否定。
在FPSGN单元之后,有一个称为FPACC的两级累加器单元。它将乘法结果与来自各种源的值(例如零或直接来自另一个向量寄存器的值)进行累加。然而,不可能直接在同一向量内添加通道。累加器不支持减法,因为它由FPSGN单元处理。
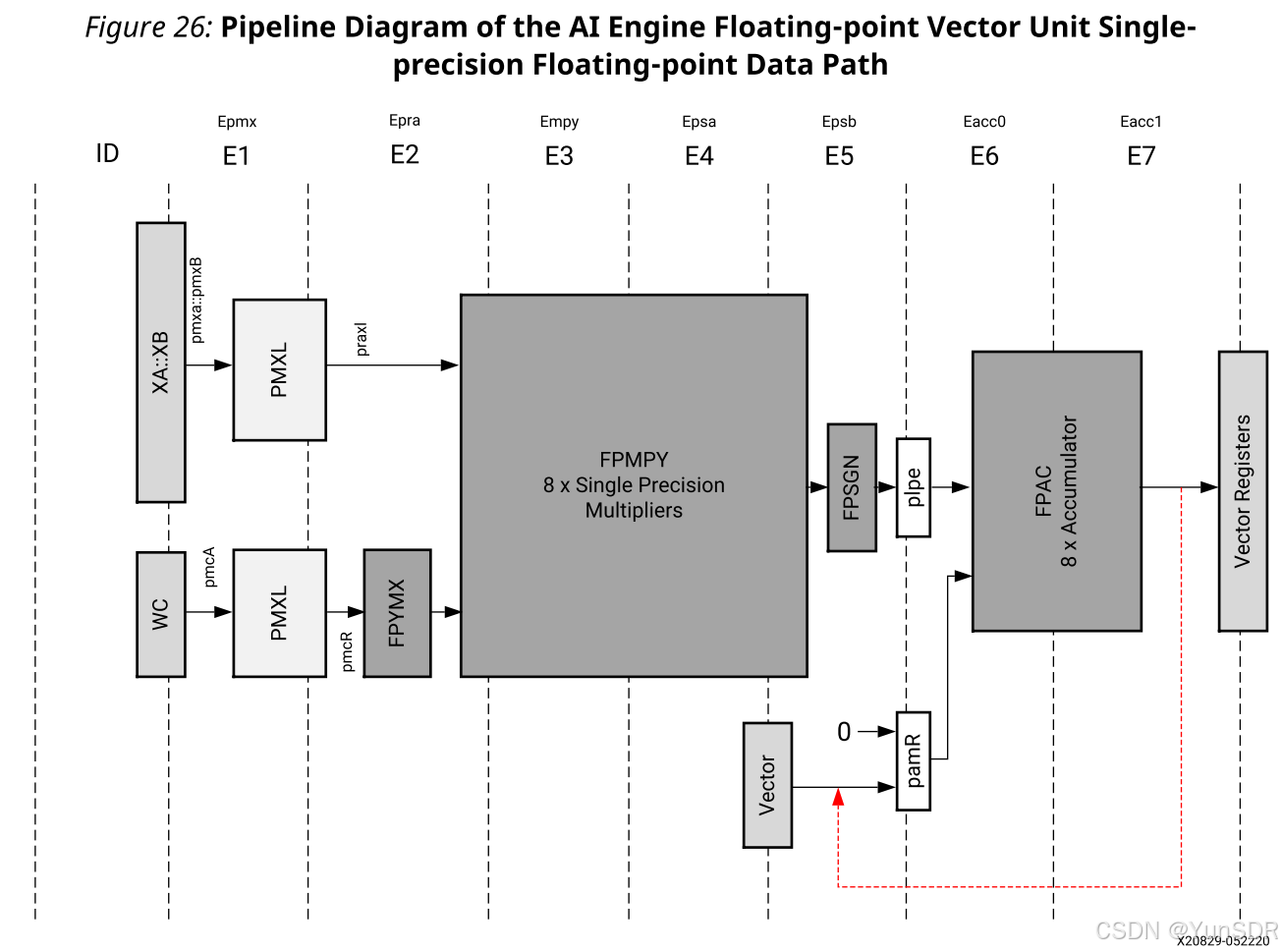
AI引擎支持浮点格式的几个向量基本函数。这些函数包括向量比较、最小值和最大值。它们以元素方式比较两个向量。所需的硬件与定点向量比较非常相似。定点单元PRA被扩展为处理浮点比较,并且操作与FPYMX块同时完成。浮点数据路径支持向量定点到单精度浮点转换以及浮点到定点转换的反向操作,但仅通过标量单元以较低的性能。在这种情况下,提取从向量中提取的元素,执行标量转换,并将结果推回到向量中。当在高效流水线环路中实现时,可以实现接近每周期一个采样的转换性能。
浮点单元可以发出对应于标准浮点异常的事件,并且状态寄存器MC跟踪事件。每个浮点功能单元有八个异常位。例外情况(从位0到7):零,无穷大,微小(下溢),巨大(上溢),不精确,巨大的整数和除以零。在这八个异常中,Tiny、Huge、Invalid和Divide by Zero可以转换为可以广播到AI Engine阵列接口的事件,然后作为中断发送到PS/PMC。
AI引擎浮点数据路径不支持某些功能。
•双精度运算
•半精度运算·自定义浮点格式,例如2位指数和14位尾数(E2:M14)
•乘法前的预加
•·乘法和累加器之间的后加
•提高乘法器和累加器之间的精度
•非规范化和次规范化浮点数
7.寄存器移动功能
本节介绍AI引擎的寄存器移动功能(有关寄存器类型命名的说明,请参阅寄存器文件部分。
•标量到标量:
○在R、M、P、C和特殊寄存器之间移动标量值
○将立即值移动到R、M、P、C和特殊寄存器
○将标量值移动到/从AXI 4流移动
•向量到向量:在一个周期内将一个128位V寄存器移动到任意V寄存器。它也适用于256位W寄存器和512位X寄存器。但是,向量大小在所有情况下必须相同。
•累加器到累加器:在一个周期内将一个384位累加器(AM)寄存器移动到另一个AM寄存器
•向量到累加器;有两种可能性:
○上移路径采用16或32位向量值并写入累加器
○使用正常乘法数据路径并将每个值乘以常数值1
•累加器到向量:移位循环饱和数据路径将累加器移动到向量寄存器
•累加器到级联流和级联到累加器:级联流以链的形式连接阵列中的AI引擎,并允许AI引擎将累加器寄存器(384位)从一个传输到下一个。输入和输出流上的小型两深384位宽FIFO允许在AI引擎之间的FIFO中存储多达四个值。
•标量到矢量:将标量值从R寄存器移动到向量寄存器
•向量到标量:从128位或256位向量寄存器提取任意8位、16位或32位值,并将结果写入标量R寄存器