C++——STL——容器deque(简单介绍),适配器——stack,queue,priority_queue
目录
1.deque(简单介绍)
1.1 deque介绍:
1.2 deque迭代器底层
1.2.1 那么比如说用迭代器实现元素的遍历,是如何实现的呢?
1.2.2 头插
1.2.3 尾插
1.2.4 实现+=
编辑
1.2.5 总结
2.stack
2.1 函数介绍
2.2 模拟实现:
3.queue
3.1 函数介绍
3.2 模拟实现:
3.3 为什么选择deque来作为他们的底层容器?
4.priority_queue
4.1 priority_queue的使用
4.2 仿函数
4.2.1 基本原理
4.3 priority_queue模拟实现
5.cpu缓存知识
1.deque(简单介绍)
咱们今天讲适配器以及deque,主要讲适配器,那么讲deque是因为,stack,queue的底层都是封装的容器deque。

Container就是适配器,可以看出,官方库中都是以deque为底层容器,那么为什么呢?今天咱们就来讨论一下。
deque与queue看着是不是很像,但千万别把他们给搞混了,deque是容器,而queue是容器适配器。
1.1 deque介绍:
deque(双端队列):是一种双开口的"连续"空间的数据结构,双开口的含义是:可以在头尾两端 进行插入和删除操作,且时间复杂度为O(1),与vector比较,头插效率高,不需要搬移元素;与 list比较,空间利用率比较高。它支持两端的高效插入与删除。
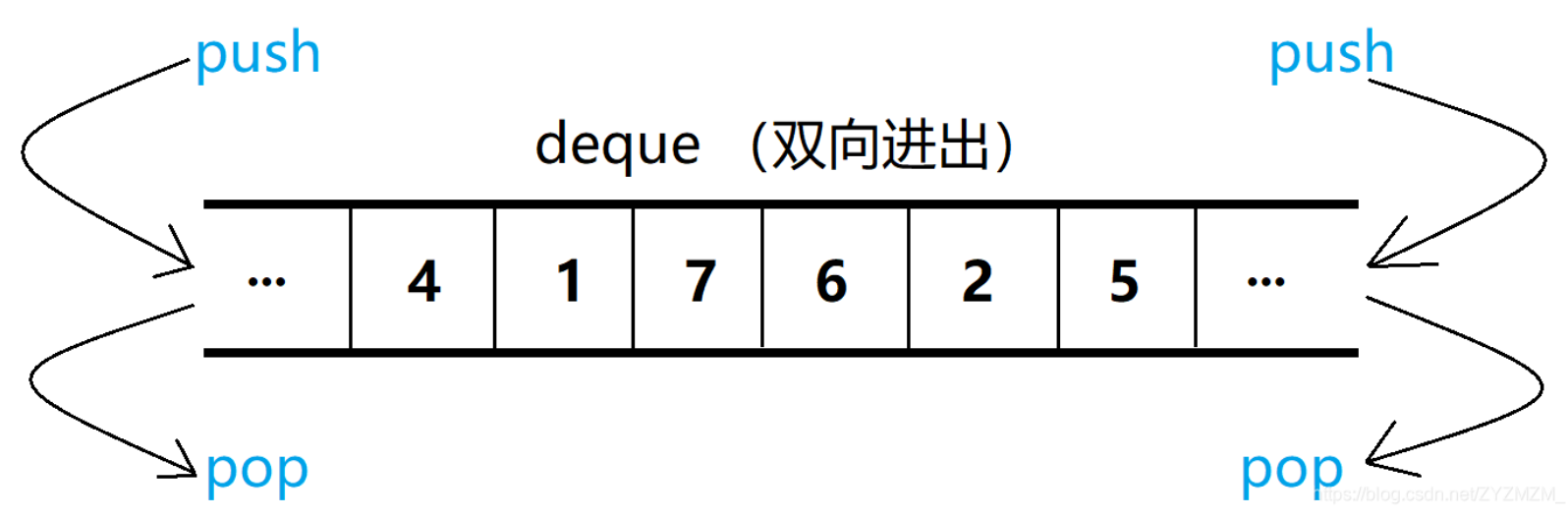
deque的功能也挺齐全的其实,基本上前面几个容器有的,它都具备。
-
核心操作:
-
push_back()和push_front():在两端插入元素。 -
pop_back()和pop_front():在两端删除元素。 -
operator[]或at():随机访问元素。 -
front()和back():访问两端元素。
-
那么接下来咱们呢进入重点部分,也就是deque的迭代器部分的讲解,听完这个,您就知道为什么stack与queue要选择deque作为他们的底层容器了。
1.2 deque迭代器底层
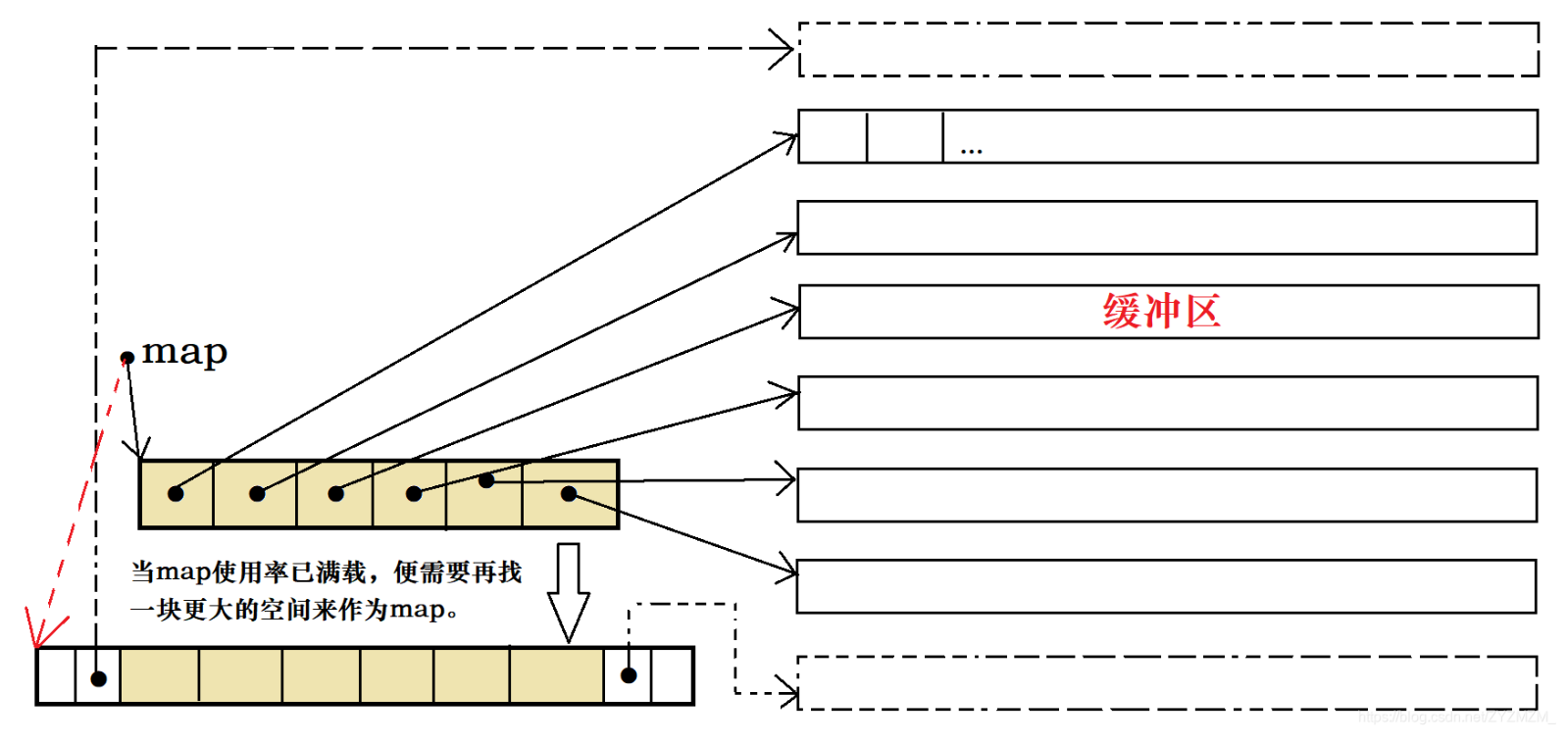
deque的迭代器更像是一块一块的动态内存块。例如上图,右方的就是他的一个一个的内存块,也可以叫缓冲区,那么这些内存块是由中间的那个中控指针数组map控制的。map中存的是指向每个内存块的指针,那么它们要是想移动内存块的时候,就只需要移动指向他们的指针即可。
当然,这个也需要扩容,但是只需要当中控数组满了的时候才去扩容,即扩容的对象就单一了。
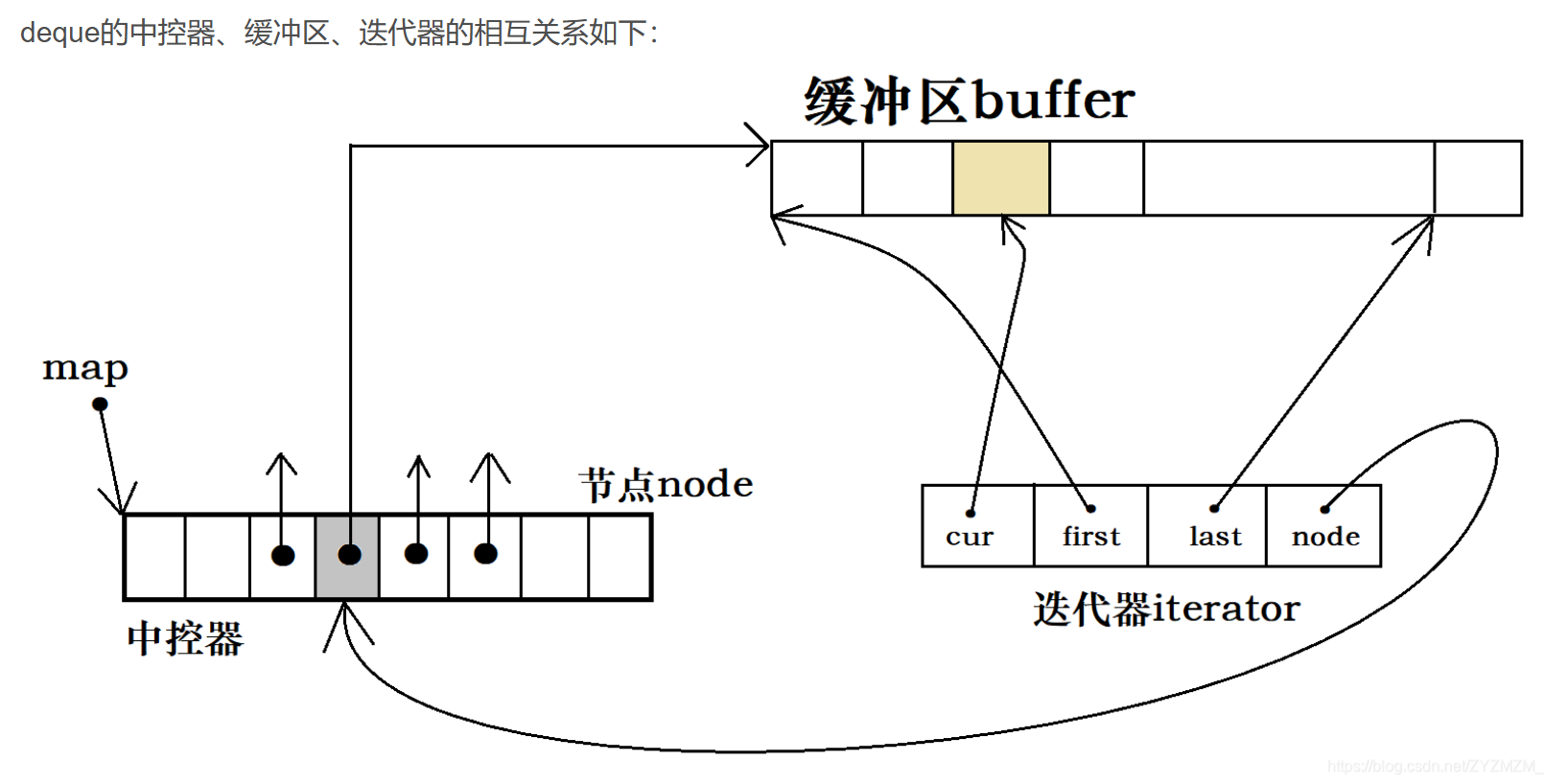
这个图更形象,因为这个图中有控制每一个内存块的迭代器。注意看,这个迭代器中有node,这个node是个二级指针,指向中控器中的元素(一级指针)。所以,内存块的移动就是对node进行的加加或者减减。那么cur指向的是当前元素的位置,而first指向的是开始,last指向的是结尾。
1.2.1 那么比如说用迭代器实现元素的遍历,是如何实现的呢?

咱们来看这一段代码,比较两个内存块是否相等,比较cur即可,因为每个内存块的first与last的位置都是相同的,所以无法比较这两个,只有比较你当前元素的位置才可以看出你两个内存块到底相不相等。这里面也是实现的operator++,
1.先让每一个块中的cur往后走,直至走完 。
2.如果说当前块中的元素遍历完了(cur==last),那么通过node来改变下一个要访问的内存块,之后更新first,last,cur的位置即可。
3.以此类推即可。
4.那么是不是可以看出遍历的时候,deque的迭代器要频繁的去检测其 是否移动到某段小空间的边界(cur==last),导致效率低下。所以说deque并不适合遍历。
1.2.2 头插
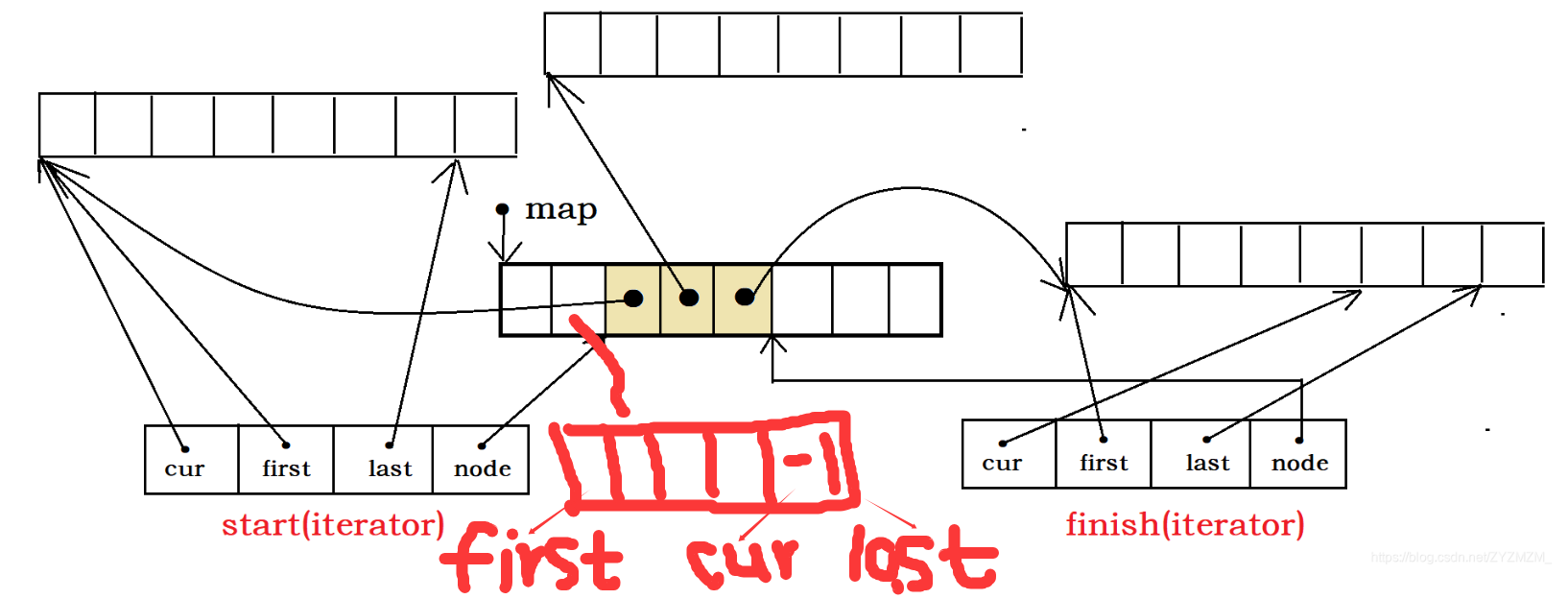
头插直接在map前面拿一个内存块,在后面插入数据即可,但之后别忘了更新位置。则,头插既不需要申请空间(因为map已有空间),也不需要反复挪动数据,很高效吧。
1.2.3 尾插
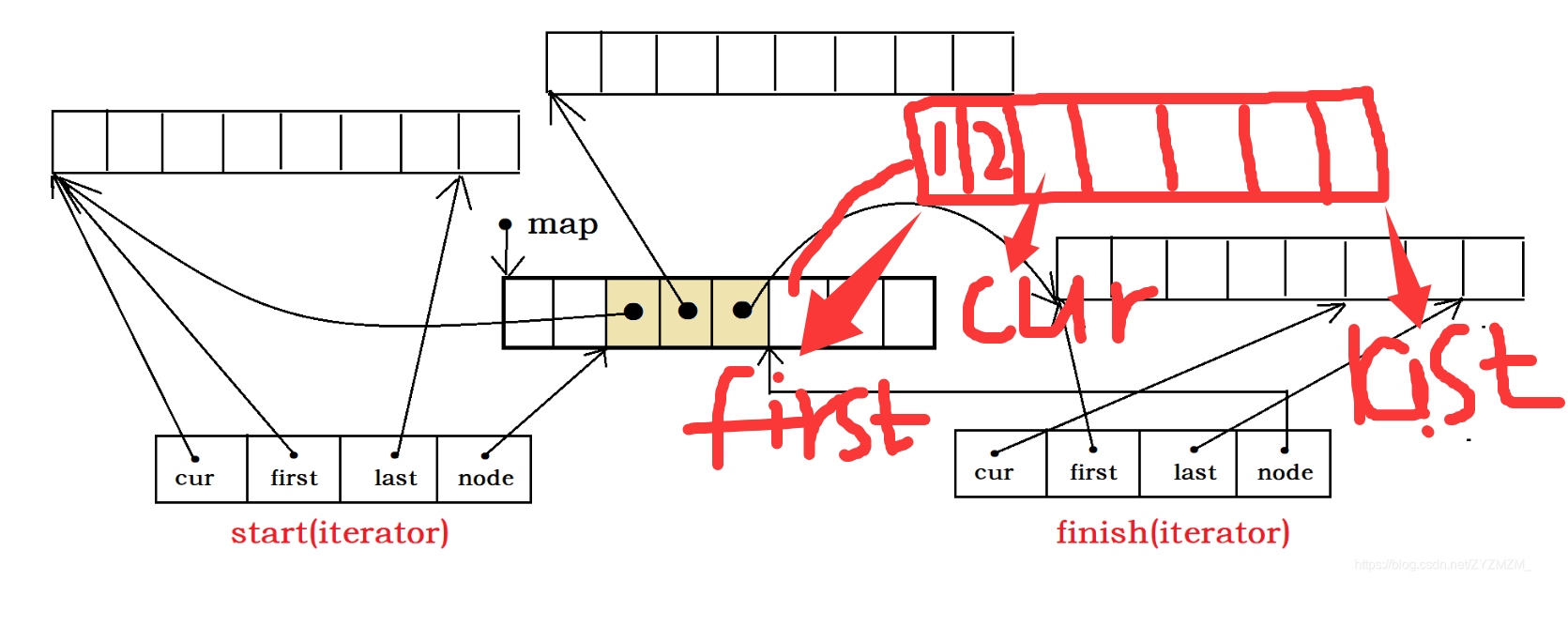 注意头插是从尾部开始插入,尾插是从头部开始插入,那么这里需要注意的是,cur在这里指向的当前元素的下一个位置,是因为,咱们的迭代器都是左闭右开的,所以说,左边的可以cur可以指向当前元素(头插),因为可以取到那个数据。但是右边的cur指向的当前元素的下一个位置(尾插),这样才可以确保可以取到已经插入的那个元素。
注意头插是从尾部开始插入,尾插是从头部开始插入,那么这里需要注意的是,cur在这里指向的当前元素的下一个位置,是因为,咱们的迭代器都是左闭右开的,所以说,左边的可以cur可以指向当前元素(头插),因为可以取到那个数据。但是右边的cur指向的当前元素的下一个位置(尾插),这样才可以确保可以取到已经插入的那个元素。
但尾插也是很高效的。因为他也是不需要申请空间,直接从map中拿就可以了。
1.2.4 实现+=

现在比如说咱们要加等一个数,那么面临的问题是跳过几个内存块?最后的位置要落在最后一个内存块的哪个位置?那么接下来,用除(/)去确定跳过几个内存块,用取模(%)去确定最后停在内存块的第几个位置处,您想想是不是这样的一个道理。当然这个只是简单的原理,具体的实现,比较复杂, 因为考虑了负数。
1.2.5 总结
OK,经过以上的讲解,大家应该知道deque的迭代器不适合用于遍历元素,因为需要频繁的判断边界是否相等。
所以,deque的缺陷:
1.与vector比较,deque的优势是:头部插入和删除时,不需要搬移元素,效率特别高,而且在扩 容时,也不需要搬移大量的元素,因此其效率是必vector高的。
2.与list比较,其底层是连续空间,空间利用率比较高,不需要存储额外字段。
3.但是,deque有一个致命缺陷:不适合遍历,因为在遍历时,deque的迭代器要频繁的去检测其 是否移动到某段小空间的边界,导致效率低下,而序列式场景中,可能需要经常遍历,因此在实 际中,需要线性结构时,大多数情况下优先考虑vector和list,deque的应用并不多,而目前能看 到的一个应用就是,STL用其作为stack和queue的底层数据结构。
咱们先来看stack与queue,最后再来说为什么选择deque作为底层容器,因为还得理解stack与queue的模拟实现。
2.stack
stack是个容器适配器,这是个新的概念,那么什么是容器适配器呢?容器适配器是建立在现有容器之上的抽象,提供不同的接口,但底层使用已有的容器实现。以我的个人见解就是这些stack,queue,priority_queue,这些的接口可以用其他的容器进行覆盖,就是说,这些容器适配器有的接口,那些对应的底层容器也是有的,这样就直接将那些底层容器封装起来,然后再实现一些这些容器适配器特有的接口,其实也是一种封装的体现。
即将底层的那些大的不同的封装起来,不让你看,让你看的就是那些自己的接口,这样虽然底层可能用不同的容器实现的,但是你表面看上去还是没什么不同,但是底层早已天差地别。这就是封装,不关心底层的实现,只关心自己的目前的接口。
2.1 函数介绍
stack():构造空的栈.
empty():检测stack是否为空.
size():返回stack中元素的个数.
top():返回栈顶元素的引用.
push():将元素val压入stack中.
pop():将stack中尾部的元素弹出.
这些看着是不是很眼熟,没错,就是咱们数据结构——栈和队列那一章实现的。
2.2 模拟实现:
template<class T, class Container = deque<T>>
class stack
{
public:
void push(const T& x)
{
_con.push_back(x);
}
void pop()
{
_con.pop_back();
}
T& top()
{
return _con.back();
}
const T& top() const
{
return _con.back();
}
bool empty() const
{
return _con.empty();
}
size_t size() const
{
return _con.size();
}
private:
Container _con;//用模板去实例化对象,这样_con可以是任何类的对象。
};
基本也就这些东西,唯一增加的就是一个容器适配器。
3.queue
1. 队列是一种容器适配器,专门用于在FIFO上下文(先进先出)中操作,其中从容器一端插入元 素,另一端提取元素。
2. 队列作为容器适配器实现,容器适配器即将特定容器类封装作为其底层容器类,queue提供 一组特定的成员函数来访问其元素。元素从队尾入队列,从队头出队列。
3. 底层容器可以是标准容器类模板之一,也可以是其他专门设计的容器类。该底层容器应至少 支持以下操作:
empty:检测队列是否为空
size:返回队列中有效元素的个数
front:返回队头元素的引用
back:返回队尾元素的引用
push_back:在队列尾部入队列
pop_front:在队列头部出队列
4. 标准容器类deque和list满足了这些要求。默认情况下,如果没有为queue实例化指定容器类,则使用标准容器deque。
3.1 函数介绍
queue():构造空的队列
empty():检测队列是否为空,是返回true,否则返回false
size():返回队列中有效元素的个数
front():返回队头元素的引用
back():返回队尾元素的引用
push():在队尾将元素val入队列
pop():将队头元素出队列
3.2 模拟实现:
template<class T, class Container = deque<T>>
class queue
{
public:
void push(const T& x)
{
_con.push_back(x);
}
void pop()
{
_con.pop_front();
}
T& front()
{
return _con.front();
}
const T& front() const
{
return _con.front();
}
T& back()
{
return _con.back();
}
const T& back() const
{
return _con.back();
}
bool empty() const
{
return _con.empty();
}
size_t size() const
{
return _con.size();
}
private:
Container _con;
};
3.3 为什么选择deque来作为他们的底层容器?
stack是一种后进先出的特殊线性数据结构,因此只要具有push_back()和pop_back()操作的线性 结构,都可以作为stack的底层容器,比如vector和list都可以;queue是先进先出的特殊线性数据 结构,只要具有push_back和pop_front操作的线性结构,都可以作为queue的底层容器,比如 list。但是STL中对stack和queue默认选择deque作为其底层容器,主要是因为:
1. stack和queue不需要遍历(因此stack和queue没有迭代器),只需要在固定的一端或者两端进 行操作。而经过咱们上边对deque迭代器原理的讲解,可知头插与尾插的效率很高。
2. 在stack中元素增长时,deque比vector的效率高(扩容时不需要搬移大量数据);queue中的 元素增长时,deque不仅效率高,而且内存使用率高。 结合了deque的优点,而完美的避开了其缺陷。
4.priority_queue

1. 优先队列是一种容器适配器,根据严格的弱排序标准,它的第一个元素总是它所包含的元素 中最大的。
2. 此上下文类似于堆,在堆中可以随时插入元素,并且只能检索最大堆元素(优先队列中位于顶 部的元素)。
3. 优先队列被实现为容器适配器,容器适配器即将特定容器类封装作为其底层容器类,queue 提供一组特定的成员函数来访问其元素。元素从特定容器的“尾部”弹出,其称为优先队列的 顶部。
4. 底层容器可以是任何标准容器类模板,也可以是其他特定设计的容器类。容器应该可以通过 随机访问迭代器访问,并支持以下操作:
empty():检测容器是否为空
size():返回容器中有效元素个数
front():返回容器中第一个元素的引用
push_back():在容器尾部插入元素
pop_back():删除容器尾部元素
5. 标准容器类vector和deque满足这些需求。默认情况下,如果没有为特定的priority_queue 类实例化指定容器类,则使用vector。
6. 需要支持随机访问迭代器,以便始终在内部保持堆结构。容器适配器通过在需要时自动调用 算法函数make_heap、push_heap和pop_heap来自动完成此操作。
这里的底层容器又变了,是vector,那么问什么是vector呢?因为priority_queue的底层是堆,而堆又是以顺序表为载体实现的(后面会讲)。所以说具体的原因是:
1. vector的连续内存布局,访问元素高效,缓存友好。
2. 尾部操作(push_back和pop_back)的高效性,这对堆的调整非常重要。
3. 动态扩容的均摊时间复杂度低。
4. 相比其他容器如deque或list,vector在堆操作中的综合性能更好。
4.1 priority_queue的使用
优先级队列默认使用vector作为其底层存储数据的容器,在vector上又使用了堆算法将vector中 元素构造成堆的结构,因此priority_queue就是堆,所有需要用到堆的位置,都可以考虑使用 priority_queue。注意:默认情况下priority_queue是大堆。如果想用小顶堆,就需要传入greater<T>这个仿函数。
priority_queue()/[riority_queue(first,last):构造一个空的优先级队列
empty():检测优先级队列是否为空,是返回true,否则返回false
top():返回优先级队列中最大(最小元素),即堆顶元素
push(x):在优先级队列中插入元素x
pop():删除优先级队列中最大(最小)元素,即堆顶元素
在看他的模拟实现之前,先学一个知识点:仿函数
4.2 仿函数
在 C++ 中,仿函数(Functor) 是一种通过重载 operator() 运算符,使得类的对象可以像函数一样被调用的机制。它是 STL(标准模板库)中实现自定义行为的核心工具之一,常用于算法(如 sort、transform)和容器(如 priority_queue、set)的自定义逻辑中。
4.2.1 基本原理
仿函数本质是一个类对象,但通过重载 operator(),可以像函数一样调用:
例如:
class Adder { public:int operator()(int a, int b) {return a + b;} };int main() {Adder add;cout << add(3, 5); // 输出 8:对象像函数一样被调用 }
仿函数与普通函数的比较:
| 特性 | 仿函数 | 普通函数 |
|---|---|---|
| 状态管理 | 可以保存状态(通过成员变量) | 无状态(全局变量除外) |
| 灵活性 | 可作为模板参数传递 | 需用函数指针或 std::function |
| 性能 | 通常可被编译器内联优化 | 函数指针可能无法内联 |
| 适配性 | 与 STL 算法/容器无缝集成 | 需额外适配(如 std::ptr_fun) |
现在仿函数用到的还比较少,因为博主现在看的关于仿函数的代码比较少。那么如何创建一个仿函数呢?
定义类:创建一个类,重载
operator()。实现逻辑:在
operator()中定义具体行为。传递对象:将类的实例传递给算法或容器。
OK,仿函数目前就讲这么多,接下来来看代码就可以看的懂了。
4.3 priority_queue模拟实现
template<class T>
class less
{
public:
bool operator()(const T & s1, const T & s2)//仿函数重载的是(),不是其他的符号
{
return s1 < s2;
}
};
/*template<class T>
class less<T*>
{
public:
bool operator()( T &*const s1, T & *const s2)
{
return *s1 < *s2;
}
};*/这个注释掉了
template<class T>
class greater
{
public:
bool operator()(const T & s1, const T & s2)
{
return s1 > s2;
}
};
template<class T, class Container = vector<T>, class Compare = less<T>>
//为什么在test.cpp中放开#include"priority_queue.h",vector就可以用了呢?
class priority_queue
{
public:
priority_queue()//一个类创建好了,别忘了构造
{}
void push(const T& x)
{
_con.push_back(x);
//底层是堆,所以不管插入还是删除数据,最后都别忘了再调整
adjustup(_con.size() - 1);
}
void pop()
{
swap(_con[0], _con[_con.size() - 1]);_con.pop_back();
adjustdown(0);
}
const T& top() const//这俩const是必须要加的,因为堆顶的元素是不允许
//被更改的,一旦更改,就全都乱了,堆中元素的顺序全都乱了
{
return _con[0];
}
size_t size() const//这个返回的是个数,是size类型,不是T类型
{
return _con.size();
}
bool empty()
{
return _con.empty();
}
private:
void adjustup(int child)//parent=(child-1)/2
//从谁开始调整,就传谁,这里先从孩子开上调整,所以先传孩子
{
Compare com;
int parent = (child - 1) / 2;
while (child > 0)
{
if (com( _con[parent], _con[child] ))
{
swap(_con[child], _con[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
void adjustdown(int parent)
{
Compare com;
size_t child = parent * 2 + 1;
while (child < _con.size())
{
if (child + 1 < _con.size() && com(_con[child] , _con[child + 1]))
{
child += 1;
}
if (com( _con[parent], _con[child] ))//这个地方是<,return x<y,所以注意com中的顺序
{
swap(_con[child], _con[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
private:
Container _con;
};
这里就不放代码图片了,因为截图的话,一整张字太小,看不清代码。
这里还要注意的是包的头文件,一般像这样的#include""的头文件放在using namespace std;后
,这样可以避免出现错误。
OK,以上关于三个容器适配器的内容讲完了,其实您看,也就多了一个容器适配器,以及模板,其余的用法啥的与前面的 容器基本类似。主要这部分还是在多写代码多应用,我在这嘴皮子磨冒烟了,您不写代码,还是没用。
5.cpu缓存知识
上面咱们老是提到缓存命中率高,啥的,这个到底是啥,那么今天我就来简单的介绍一下:
假如说有一段数据,那么这个数据是不是存放在内存中,当然也有的存放在缓存中。如果说cpu要访问一个数据,要看这个数据是否在缓存中,在就叫缓存命中,不在就叫缓存不命中。不命中,就要先将数据从内存加载到缓存中(一般都是加载一段数据)。然后再访问缓存。

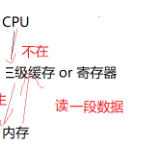
OK,咱们先来看vector,为什么说vector的缓存命中率高呢?
 假如说第一个数据不在缓存中,那么cpu就要读取一段数据到缓存中,又因为vector地址是连续的,所以说读一段数据到缓存中就很自然地将后面的数据全都读到缓存中并且全部读取出来。
假如说第一个数据不在缓存中,那么cpu就要读取一段数据到缓存中,又因为vector地址是连续的,所以说读一段数据到缓存中就很自然地将后面的数据全都读到缓存中并且全部读取出来。
但是list:缓存命中率低
它的地址不是连续的,所以说你读取一段数据的时候,可能读过来了,数据不是咱们想要的 。还可能读过来了,但不是咱们想要的数据,这就是缓存污染!
OK,本博主的粗略解释就这些,大家要是想看详细的。
与程序员相关的CPU缓存知识 | 酷 壳 - CoolShell
这是陈大佬写的一篇文章,大家可以去阅读一下。
本篇完...................