人工神经网络学习——前馈神经网络的反向传播算法(待完善
嗯....这是初稿,其实我自己也不是太懂,等我再学学,我会再改改,但是代码是可以运行的,是对的
第一步:激活函数定义

第二步:单层反向传播数学表达式
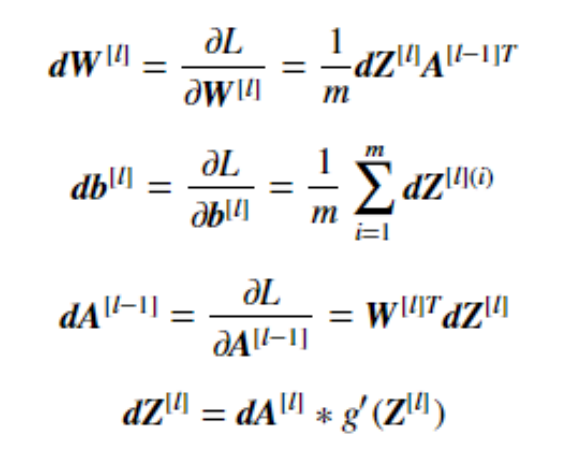
公式概念解释:
1.dW[l]公式
就像在搭积木的神经网络里,W[l] 是第 l 层积木连接的松紧程度(权重)。dW[l] 就是告诉我们,为了让积木搭得更符合我们想要的样子(损失函数最小 ),这个松紧程度该怎么调整。把误差 dZ[l] 和上一层积木搭好后的样子 A[l−1] 一起运算(乘起来再除以样本个数 m ),就能算出这个调整量。
2.db[l]公式
b[l] 可以看成是第 l 层积木搭建时的一个基础偏移量。db[l] 是说,要让整体积木造型更好(损失函数更小) ,这个基础偏移量得怎么变。把这一层每个样本的误差 dZ[l](i) 都加起来再除以样本数 m ,就得到了调整值。
3.dA[l−1]公式
A[l−1] 是上一层积木搭完后的样子,dA[l−1] 就是说为了让整体搭得更好,上一层积木样子得怎么改。用这一层积木连接的松紧程度 W[l] (转置后 )和这一层的误差 dZ[l] 乘起来,就知道上一层该怎么调整了。
4.dZ[l]公式
Z[l] 是第 l 层积木搭建前的一个中间状态。dZ[l] 是这一层积木搭建中出现的误差情况。用激活值的误差 dA[l] ,乘上激活函数在 Z[l] 这个状态下的变化快慢 g′(Z[l]) ,就能算出这一层的误差
5.梯度
梯度从本质来说,是一个向量,能表示函数在某一点处变化最快的方向和变化的速率。
第三步:用Python代码实现上述数学表达式
def single_layer_backward_propagation(dA_curr,W_curr,b_curr,Z_curr,A_prev,activation="relu"):m =A_prev.shape[1]# selection of activation functionif activation == "relu":backward_activation_func = relu_backwardelif activation == "sigmoid":backward_activation_func = sigmoid_backwardelse:raise Exception('Non-supported activation function')dZ_curr =backward_activation_func(dA_curr,Z_curr)dW_curr =np.dot(dZ_curr,A_prev.T)/mdb_curr = np.sum(dZ_curr, axis=1 ,keepdims=True) / mdA_prev= np.dot(W_curr.T,dZ_curr) #这里忘记转置了# return of calculated activation A and the intermediate Z matrixreturn dA_prev,dW_curr,db_curr
第四步:整个神经网络的反向传播计算
1. 前向传播
在进行反向传播之前,需要先完成前向传播,将输入数据通过神经网络的各层,计算出每一层的输出。这会得到每一层的线性组合结果和激活值
,这些中间结果在反向传播时会被用到。
- 输入层接收原始数据 X ,将其作为第一层的激活值
。
- 对于每一层 l (
) ,L 是网络的总层数 ),计算线性组合,再通过激活函数得
到激活值
,其中
是第 l 层的权重矩阵,
是第 l 层的偏置向量,
是第 l 层的激活函数。
2. 计算输出层误差项 ![dZ^{[L]}](https://latex.csdn.net/eq?dZ%5E%7B%5BL%5D%7D)
输出层的误差项是反向传播的起始点,它的计算依赖于损失函数和输出层的激活函数。常见的情况如下:
- 使用交叉熵损失函数和 Sigmoid 激活函数(二分类问题 ):
- 损失函数
,其中 y 是真实标签,
是输出层的激活值。
- 先计算
。
- 因为
,
根据链式法则
。
- 损失函数
- 使用 Softmax 激活函数和交叉熵损失函数(多分类问题 ):
,其中 Y 是真实标签的 One - Hot 编码。
3. 计算输出层参数的梯度
- 计算权重梯度
:根据公式
,其中 m 是样本数量,
是第
层的激活值。
- 计算偏置梯度
:根据公式
,即对
4. 反向逐层计算误差项和参数梯度
从倒数第二层开始,逐层向前计算每一层的误差项
和参数梯度
、 \
。
- 计算误差项 \(dZ^{[l]}\):根据链式法则
,其中
,
是第 l 层激活函数的导数。
- 计算权重梯度
:
。
- 计算偏置梯度
:
。
5. 更新参数
根据计算得到的梯度,使用优化算法(如梯度下降算法 )更新网络中的参数。
- 权重更新:
,其中
是学习率。
- 偏置更新:
。
6. 重复步骤 1 - 5
不断重复前向传播、反向传播和参数更新的过程,直到损失函数收敛或达到预设的迭代次数。
知识点:
一、交叉熵损失函数对输出层预测函数的偏导数
咱们把神经网络想象成一个会做预测的 “小专家”,反向传播就是这个 “小专家” 不断学习进步的过程。下面详细说说 -(np.divide(Y, Y_hat) - np.divide(1 - Y, 1 - Y_hat)) 在这个过程里的作用。
1. 发现预测错误
这个 “小专家” 做预测时,会有预测结果 Y_hat,而实际情况是 Y
-(np.divide(Y, Y_hat) - np.divide(1 - Y, 1 - Y_hat)) 就像是一个 “纠错小助手”,能算出 “小专家” 预测得有多不准。
- 当实际情况
Y是 1,也就是真实答案是 “是” 的时候,如果预测结果Y_hat离 1 很远,“纠错小助手” 就会给出一个比较大的数值,提醒 “小专家”:“嘿,你得把预测结果往 1 那边调一调啦!” - 当实际情况
Y是 0,也就是真实答案是 “否” 的时候,如果预测结果Y_hat离 0 很远,“纠错小助手” 就会给出一个比较小的数值(负数),告诉 “小专家”:“你得把预测结果往 0 那边调一调。”
2. 确定调整方向和力度
在反向传播里,我们要知道 “小专家” 内部的各种 “小零件”(也就是神经网络里的权重和偏置)该怎么调整,才能让预测更准。“纠错小助手” 算出的数值就是关键线索。
- 它先告诉输出层这个 “小零件集合”,预测错在哪了,误差有多大。这就像告诉一群工人,他们建的房子哪部分没达到要求,偏差是多少。
- 然后,输出层的 “工人” 根据这个误差,去计算和它相连的上一层 “小零件”(权重和偏置)该怎么调整。就好比建房子的工人根据房子的偏差,去调整上一道工序的施工参数。
- 这个过程会一层一层往前传递,每一层都根据下一层传来的误差信息,计算自己这层的 “小零件” 该怎么调整。
3. 不断学习进步
有了每层 “小零件” 的调整方案后,“小专家” 就会按照这个方案去更新自己的 “小零件”。就像建房子的工人按照新的施工参数去调整施工。
- 不断重复这个过程,“小专家” 每次做预测时,“纠错小助手” 都会算出误差,然后调整 “小零件”。
- 慢慢地,“小专家” 的预测就会越来越准确,就像房子建得越来越符合要求一样。
所以,-(np.divide(Y, Y_hat) - np.divide(1 - Y, 1 - Y_hat)) 在神经网络反向传播里,就像是一个 “纠错小助手”,帮助 “小专家” 发现错误、确定调整方向和力度,让 “小专家” 不断学习进步,做出更准确的预测。
二、再来理解理解-(np.divide(Y, Y_hat) - np.divide(1 - Y, 1 - Y_hat))


代码展示:
# -*-coding:utf-8 -*-
import numpy as np
from IPython.display import Image#1. 初始化神经网络层#1.1 网络结构
NN_ARCHITECTURE = [# 参考形式: {"input_dim": , "output_dim": , "activation": },{"input_dim": 2, # 输入特征维度"output_dim": 4, # 隐藏层神经元数量"activation": "relu"},# 第二层(隐藏层 → 输出层){"input_dim": 4, # 必须等于上一层的output_dim"output_dim": 1, # 输出层神经元数量"activation": "sigmoid"}
]#1.2 初始化网络层
def init_layers(nn_architecture, seed = 99):# random seed initiationnp.random.seed(seed)# number of layers in our neural networknumber_of_layers = len(nn_architecture)# parameters storage initiationparams_values = {}# iteration over network layersfor idx, layer in enumerate(nn_architecture):layer_idx =idx+1layer_input_size =layer["input_dim"]layer_output_size =layer["output_dim"]params_values['W' +str(layer_idx)] =np.random.randn(layer_output_size,layer_input_size)*0.1params_values['b'+str(layer_idx)] =np.random.randn(layer_output_size,1)*0.1return params_values#2. 激活函数定义def sigmoid(Z):return 1/(1+np.exp(-Z))def relu(Z):return np.maximum(0,Z)def sigmoid_backward(dA,Z):sig =sigmoid(Z)return dA *sig *(1-sig)def relu_backward(dA,Z):dZ =np.array(dA,copy = True)dZ[Z<=0] =0return dZ#3. 前向传播算法定义#3.1 单层前向传播算法
#A_prev: 公式中的A^{l-1}
#W_curr: 公式中的W
#b_curr: 公式中的b
def single_layer_forward_propagation(A_prev, W_curr, b_curr, activation="relu"):# calculation of the input value for the activation functionZ_curr = np.dot(W_curr , A_prev) +b_curr# selection of activation functionif activation == "relu":activation_func = reluelif activation == "sigmoid":activation_func =sigmoidelse:raise Exception('Non-supported activation function')# return of calculated activation A and the intermediate Z matrixreturn activation_func(Z_curr), Z_curr# 3. 反向传播算法定义# 3.1 单层反向传播算法
# A_prev: 公式中的A^{l-1}
# W_curr: 公式中的W
# b_curr: 公式中的b
# dA_curr: 公式中的dA^{l}
def single_layer_backward_propagation(dA_curr,W_curr,b_curr,Z_curr,A_prev,activation="relu"):m =A_prev.shape[1]# selection of activation functionif activation == "relu":backward_activation_func = relu_backwardelif activation == "sigmoid":backward_activation_func = sigmoid_backwardelse:raise Exception('Non-supported activation function')dZ_curr =backward_activation_func(dA_curr,Z_curr)dW_curr =np.dot(dZ_curr,A_prev.T)/mdb_curr = np.sum(dZ_curr, axis=1 ,keepdims=True) / mdA_prev= np.dot(W_curr.T,dZ_curr) #这里忘记转置了# return of calculated activation A and the intermediate Z matrixreturn dA_prev,dW_curr,db_curr#3.2 整个神经网络的反向传播算法def full_backward_propagation(Y_hat,Y,memory, params_values, nn_architecture):grads_values ={}m=Y.shape[1]Y=Y.reshape(Y_hat.shape)dA_prev = -(np.divide(Y,Y_hat) -np.divide(1-Y,1-Y_hat))for layer_idx_prev,layer in reversed(list(enumerate(nn_architecture))):layer_idx_curr =layer_idx_prev+1activ_function_curr = layer["activation"]dA_curr =dA_prevA_prev =memory["A"+str(layer_idx_prev)]Z_curr =memory["Z"+str(layer_idx_curr)]W_curr =params_values["W"+str(layer_idx_curr)]b_curr =params_values["b"+str(layer_idx_curr)]dA_prev,dW_curr,db_curr=single_layer_backward_propagation(dA_curr,W_curr,b_curr,Z_curr,A_prev,activ_function_curr)grads_values["dW"+str(layer_idx_curr)] =dW_currgrads_values["db"+str(layer_idx_curr)] =db_currreturn grads_values# 模型参数更新
def update(params_values ,grads_values ,nn_architecture ,learning_rate):for layer_idx ,layer in enumerate(nn_architecture,1):params_values["W" +str(layer_idx)] -=learning_rate * grads_values["dW"+str(layer_idx)]params_values["b" +str(layer_idx)] -=learning_rate * grads_values["db"+str(layer_idx)]return params_values# 3.2 整个神经网络的前向传播算法# params_values可以先简单表示为init_layers函数表示的形式。
def full_forward_propagation(X, params_values, nn_architecture):# creating a temporary memory to store the information needed for a backward stepmemory = {}# X vector is the activation for previous layerA_curr = X# iteration over network layers 遍历所有网络层,从输入层到输出层for idx, layer in enumerate(nn_architecture):# we number network layers from 1layer_idx = idx + 1# transfer the activation from the previous iterationA_prev = A_curr # 上一层的输出作为当前层输入# extraction of the activation function for the current layeractiv_function_curr = layer["activation"]# extraction of W for the current layerW_curr = params_values[f"W{layer_idx}"] # 权重参数# extraction of b for the current layerb_curr = params_values[f"b{layer_idx}"] # 偏置参数# calculation of activation for the current layerA_curr, Z_curr = single_layer_forward_propagation(A_prev, W_curr, b_curr, activ_function_curr)# saving calculated values in the memorymemory["A" + str(idx)] = A_prev # 存储上一层激活结果memory["Z" + str(layer_idx)] = Z_curr # 存储当前层未激活值# return of prediction vector and a dictionary containing intermediate valuesreturn A_curr, memory#4. 构建损失函数,并计算出精确度#4.1 计算损失值
def get_cost_value(Y_hat, Y):m =Y.shape[1]epsilon =1e-7#截断预测值到[epsilon,1-epsilon]Y_hat_clipped =np.clip(Y_hat,epsilon,1-epsilon)#二分类交叉熵损失函数cost =-(1/m)*np.sum(Y*np.log(Y_hat_clipped) + (1-Y)*np.log(1-Y_hat_clipped))return np.squeeze(cost)# an auxiliary function that converts probability into class
def convert_prob_into_class(probs):return np.where(probs >=0.5,1.0,0.0)#4.2 计算精确度
def get_accuracy_value(Y_hat, Y):Y_hat_ = convert_prob_into_class(Y_hat)assert Y_hat_.shape == Y.shape, f"形状不匹配: Y_hat {Y_hat_.shape} vs Y {Y.shape}"return (Y_hat_ == Y).all(axis=0).mean()# 5. 搭建前馈神经网络的前向传播计算框架def train(X, Y, nn_architecture, epochs, learning_rate, verbose=True, callback=None):# initiation of neural net parametersparams_values = init_layers(nn_architecture)# initiation of lists storing the history# of metrics calculated during the learning processcost_history = []accuracy_history = []# performing calculations for subsequent iterationsfor i in range(epochs):# step forwardY_hat, cache = full_forward_propagation(X,params_values,nn_architecture)# calculating metrics and saving them in historycost = get_cost_value(Y_hat, Y)cost_history.append(cost)accuracy = get_accuracy_value(Y_hat, Y)accuracy_history.append(accuracy)# Backward propagationgrads_values = full_backward_propagation(Y_hat, Y, cache, params_values, nn_architecture)# Update parametersparams_values = update(params_values, grads_values, nn_architecture, learning_rate)if(i % 50 == 0):if(verbose):print("Iteration: {:05} - cost: {:.5f} - accuracy: {:.5f}".format(i, cost, accuracy))if(callback is not None):callback(i, params_values)return params_values##前馈神经网络测试部分from sklearn.datasets import make_moons
from sklearn.model_selection import train_test_splitimport seaborn as sns
import matplotlib.pyplot as plt
from matplotlib import cm
sns.set_style("whitegrid")#1. 数据集的设置、生成与划分
# number of samples in the data set
N_SAMPLES = 1000
# ratio between training and test sets
TEST_SIZE = 0.1X, y =make_moons(n_samples= N_SAMPLES,noise=0.2,random_state=100)
X_train, X_test, y_train, y_test =train_test_split(X,y,test_size=TEST_SIZE,random_state=42)#2. 数据集可视化显示
# the function making up the graph of a dataset
def make_plot(X, y, plot_name, file_name=None, XX=None, YY=None, preds=None, dark=False):if(dark):plt.style.use('dark_background')else:sns.set_style('whitegrid')plt.figure(figsize=(16,12))axes =plt.gca()axes.set(xlabel="$X_1$" ,ylabel="$X_2$")plt.title(plot_name,fontsize=30)plt.subplots_adjust(left=0.20)plt.subplots_adjust(right=0.80)if(XX is not None and YY is not None and preds is not None):plt.contourf(XX,YY,preds.reshape(XX.shape),25,alpha =1 ,cmap =cm.Spectral)plt.contourf(XX, YY, preds.reshape(XX.shape), levels=[.5], cmap="Greys",vmin=0,vmax=.6)plt.scatter(X[:, 0],X[:, 1],c=y.ravel(),s=40,cmap=plt.cm.Spectral,edgecolors='black')if(file_name):plt.savefig(file_name)plt.show()make_plot(X, y, "Dataset", "vis.png")# 3. 前馈神经网络训练与测试# Training
params_values =train(np.transpose(X_train),np.transpose(y_train.reshape((y_train.shape[0],1))),NN_ARCHITECTURE,2000,0.01)# Prediction
Y_test_hat, _ =full_forward_propagation(np.transpose(X_test),params_values,NN_ARCHITECTURE)# Accuracy achieved on the test set
acc_test =get_accuracy_value(Y_test_hat,np.transpose(y_test.reshape((y_test.shape[0],1))))
print("Test set accuracy:{:.2f} -David".format(acc_test))