PageIndex:构建无需切块向量化的 Agentic RAG
引言
你是否对长篇专业文档的向量数据库检索准确性感到失望?传统的基于向量的RAG系统依赖于语义相似性而非真正的相关性。但在检索中,我们真正需要的是相关性——这需要推理能力。当处理需要领域专业知识和多步推理的专业文档时,相似度搜索常常不尽人意。
基于推理的RAG提供了更好的选择:让大语言模型能够思考和推理,找到最相关的文档部分。受AlphaGo启发,Vectify AI提出使用树搜索来执行结构化文档检索。
PageIndex 是一个文档索引系统,它从长文档构建搜索树结构,为基于推理的RAG做好准备。
由Vectify AI开发。
PageIndex是什么
PageIndex能将冗长的PDF文档转换为语义树结构,类似于*“目录”*但专为大语言模型(LLMs)优化。
它特别适用于:财务报告、监管文件、学术教科书、法律或技术手册,以及任何超出LLM上下文限制的文档。
主要特点
-
层次树结构
让大语言模型能够逻辑性地遍历文档——就像一个智能的、为LLM优化的目录。 -
精确页面引用
每个节点都包含其摘要和开始/结束页面的物理索引,实现精准检索。 -
无需人为分块
不使用任意分块。节点遵循文档的自然结构。 -
适用于大规模文档
设计用于轻松处理数百甚至上千页的文档。
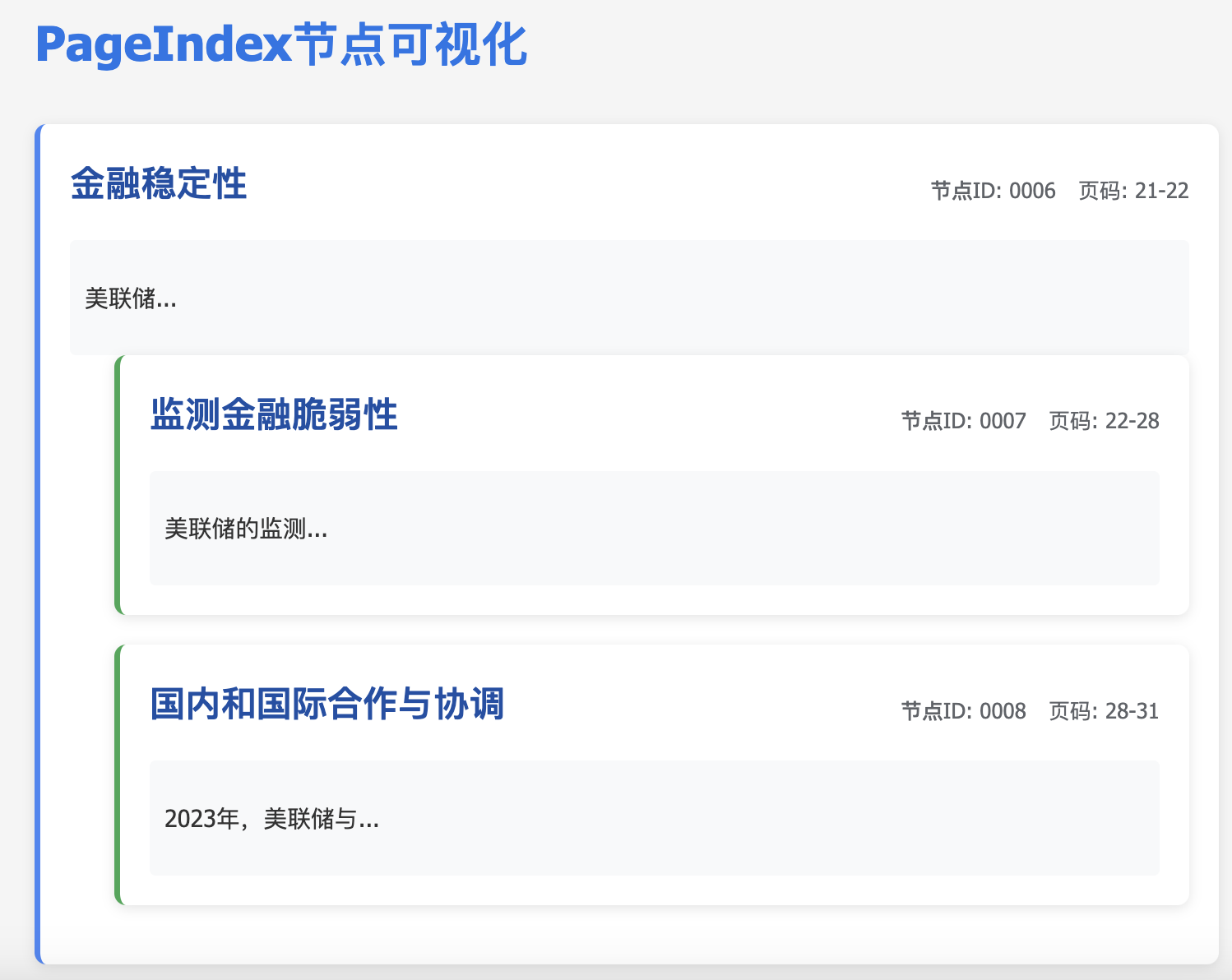
PageIndex格式
以下是输出示例。查看更多示例文档和生成的树结构。
...
{"title": "金融稳定性","node_id": "0006","start_index": 21,"end_index": 22,"summary": "美联储...","nodes": [{"title": "监测金融脆弱性","node_id": "0007","start_index": 22,"end_index": 28,"summary": "美联储的监测..."},{"title": "国内和国际合作与协调","node_id": "0008","start_index": 28,"end_index": 31,"summary": "2023年,美联储与..."}]
}
...
其实看到这里,我们会发现RAG之前很多框架或者算法都有类似的思想:
- 例如LlamaIndex的Node实现
- 比如Raptor的层级聚类
- 还有Mineru的PDF转换生成Markdown,然后我们可以解析成类似具有章节信息的json数据
那PageIndex的亮点在哪里呢,其实在最后一部分“使用PageIndex进行基于推理的RAG”的实现,相比之前的Advanced和Modular RAG,Agentic RAG更加智能,接着我们往下看怎么实现的?
使用方法
按照以下步骤从PDF文档生成PageIndex树结构。
1. 安装依赖项
pip3 install -r requirements.txt
2. 设置OpenAI API密钥
在根目录创建一个.env文件并添加你的API密钥:
CHATGPT_API_KEY=你的openai密钥
3. 对PDF运行PageIndex
python3 run_pageindex.py --pdf_path /path/to/your/document.pdf
你可以通过额外的可选参数自定义处理过程:
--model 使用的OpenAI模型 (默认: gpt-4o-2024-11-20)
--toc-check-pages 检查目录的页数 (默认: 20)
--max-pages-per-node 每个节点的最大页数 (默认: 10)
--max-tokens-per-node 每个节点的最大token数 (默认: 20000)
--if-add-node-id 添加节点ID (yes/no, 默认: yes)
--if-add-node-summary 添加节点摘要 (yes/no, 默认: no)
--if-add-doc-description 添加文档描述 (yes/no, 默认: yes)
云API (测试版)
不想自己部署?试试Vectify AI的PageIndex托管API。托管版本使用Vectify AI自定义的OCR模型更准确地识别PDF,为复杂文档提供更好的树结构。
在这个表单留下你的邮箱,免费获得1,000页处理额度。
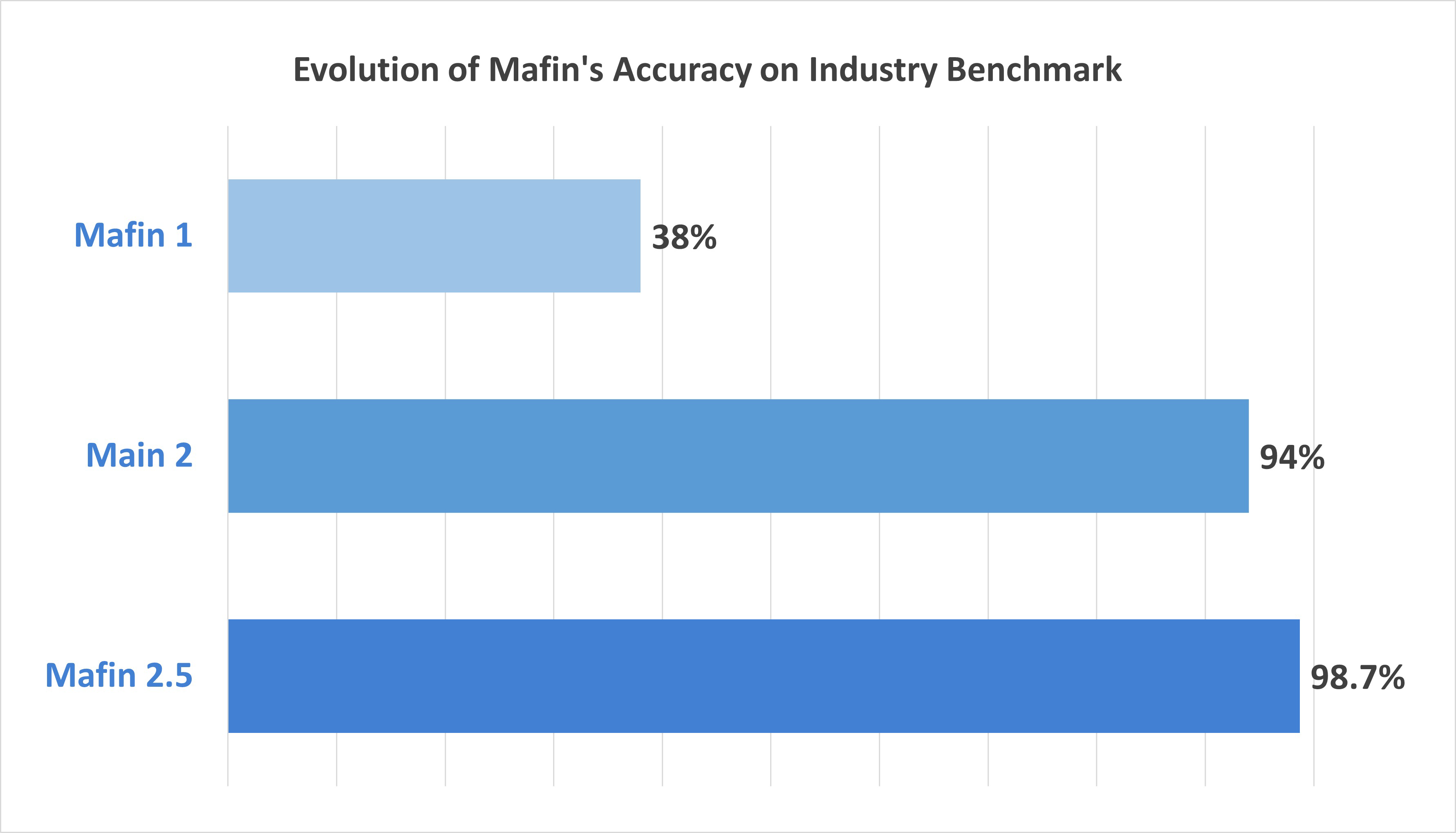
案例研究:Mafin 2.5
Mafin 2.5是一个专为财务文档分析设计的最先进基于推理的RAG模型。它基于PageIndex构建,在FinanceBench基准测试中达到了惊人的98.7%准确率——显著优于传统的基于向量的RAG系统。
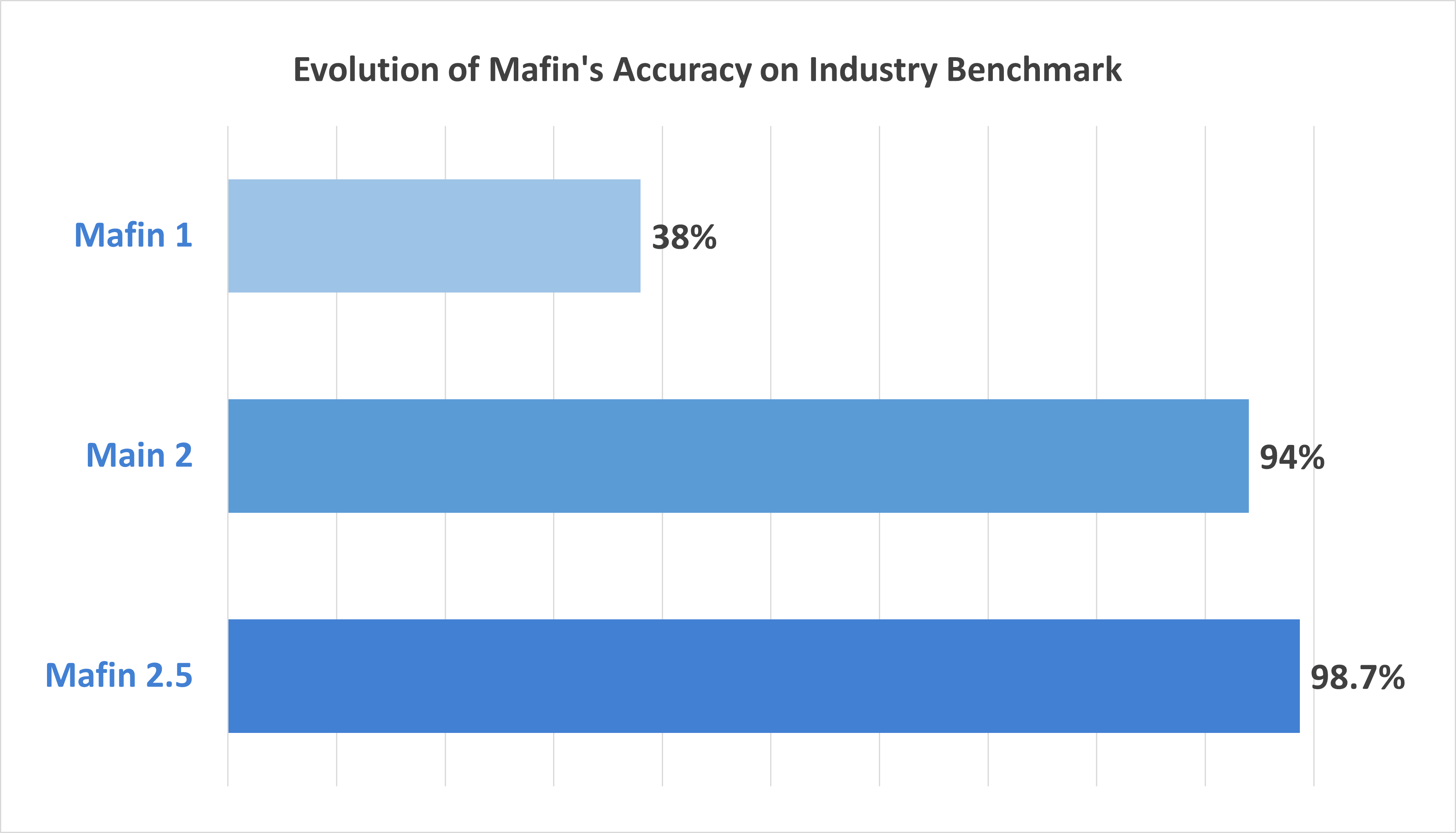
PageIndex的分层索引使得能够精确导航和提取复杂财务报告(如SEC文件和财报披露)中的相关内容。
👉 查看完整基准测试结果,了解详细比较和性能指标。
使用PageIndex进行基于推理的RAG
使用PageIndex构建基于推理的检索系统,无需依赖语义相似度。非常适合需要细微区分的领域特定任务。
🔖 预处理工作流示例
- 使用PageIndex处理文档,生成树结构。
- 将树结构及其对应的文档ID存储在数据库表中。
- 将每个节点的内容存储在单独的表中,通过节点ID和树ID进行索引。
🔖 基于推理的RAG框架示例
- 查询预处理:
- 分析查询以确定所需知识
- 文档选择:
- 搜索相关文档及其ID
- 从数据库获取相应的树结构
- 节点选择:
- 搜索树结构以识别相关节点
- LLM生成:
- 从数据库获取所选节点的相应内容
- 格式化并提取相关信息
- 将组装的上下文与原始查询一起发送给LLM
- 生成有依据的回答
🔖 节点选择的示例提示
prompt = f"""
给你一个问题和一个文档的树结构。
你需要找出所有可能包含答案的节点。问题: {question}文档树结构: {structure}请用以下JSON格式回复:
{{"thinking": <关于在哪里寻找的推理过程>,"node_list": [node_id1, node_id2, ...]
}}
"""
看到合理我们自然明白了,PageIndex不需要切块向量是因为通过将文档转换为节点,然后用大模型进行选择,之前RAG是检索+排序=现在的LLM Judge。
同时这个问题就是,当多文档或者文档篇幅比较多的时候,LLM去做选择成本比较高的。