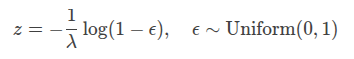深度学习中的“重参数化”总结
深度学习中的重参数化(Reparameterization)是一种数学技巧,主要用于解决模型训练过程中随机性操作(如采样)导致的梯度不可导问题。其核心思想是将随机变量的生成过程分解为确定性和随机性两部分,使得反向传播能够正常进行。
1. 问题背景:随机节点的梯度阻断
在涉及概率生成的任务中(如变分自编码器VAE),我们希望从潜在变量的分布中采样,这个分布通常是某种分布(例如高斯分布,参数化为均值 和方差
),传统的采样方法是从正态分布中直接采样(例如潜在变量
),例如:
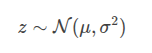
其中和
是模型生成的参数。
直接采样会导致问题:
-
采样操作不可导:梯度无法通过随机节点(如
)回传到
和
。
-
无法优化分布参数:模型无法通过反向传播学习如何调整
重参数化技巧通过引入一个独立的随机变量来解决这个问题,使得采样过程可导。
2. 重参数化的解决方案
通过引入一个外部独立随机变量(通常为标准分布,如标准正态分布),将随机性转移到外部,使采样过程变为可导操作。
重参数化的核心思想是将采样过程分解为两个部分:
-
从一个固定的分布(例如标准正态分布 N(0,1))中采样随机噪声。
-
通过一个确定性函数将这个随机噪声变换为所需的分布。
以高斯分布为例:
原采样过程:
重参数化后:
![]()
-
确定性部分:
-
随机性部分:ϵ来自与模型无关的标准正态分布。
其中 ϵ∼N(0,1) 是一个独立的标准正态分布随机变量。
通过这种方式,采样过程 就可以表示为
和
的函数,而 ϵ 是从固定分布中采样的。这样,梯度就可以通过
和
传播,从而实现端到端的训练。
3. 梯度传播路径
通过重参数化,梯度可通过确定性路径传递:
-
计算
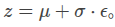
-
损失函数对 z 的梯度可正常计算。
-
梯度通过
4. 关键优势
-
保持计算图可导:梯度可流经
-
分离随机性:模型仅需学习确定性参数(
-
通用性:适用于多种分布(如高斯、拉普拉斯等),只需找到合适的重参数化形式。
5. 实际应用场景
变分自编码器(VAE)
-
编码器输出
。
-
采样:通过
生成潜在变量。 -
解码器 基于 z 重构输入数据。
强化学习(策略梯度方法)
-
策略网络输出动作分布的参数,通过重参数化采样动作,使梯度可传回策略网络。
生成对抗网络(GAN)
-
某些GAN变种通过重参数化生成器的输入噪声,提升训练稳定性。
6. 代码示例(VAE中的实现)
def reparameterize(mu, logvar):# logvar 是方差的对数形式(log σ²)std = torch.exp(0.5 * logvar) # σ = exp(0.5 * log σ²)eps = torch.randn_like(std) # 采样 ε ~ N(0, 1)z = mu + eps * std # z = μ + σ·εreturn z7.优点
-
可导性:通过将采样过程分解为确定性变换和随机噪声,使得整个采样过程可导。
-
稳定性:避免了直接对随机采样结果求导,提高了训练的稳定性。
-
灵活性:可以轻松扩展到其他分布(如伯努利分布)。
8. 其他分布的重参数化
- 均匀分布 Uniform(a,b):
![]()
- 指数分布 Exp(λ)Exp(λ):