第J5周:DenseNet+SE-Net实战
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
目标
- 将SE-Net注意力机制加入DenseNet模型中
- 将猴痘病识别率达到80%以上
具体实现
(一)环境
语言环境:Python 3.10
编 译 器: PyCharm
框 架: Pytorch
(二)具体步骤
1. 项目结构

数据目录:
2. dataset.py 数据集处理
import os
import shutil
from sklearn.model_selection import train_test_split
from torchvision import transforms def organize_dataset(src_dir, dest_dir, test_size=0.2, val_size=0.15, random_state=42): """ 组织数据集,将原始数据分割为训练集、验证集和测试集 参数: - src_dir: 原始数据目录,包含多个类别子目录 - dest_dir: 目标数据目录 - test_size: 测试集比例 - val_size: 验证集比例 - random_state: 随机种子 """ # 创建目标目录结构 os.makedirs(dest_dir, exist_ok=True) # 创建训练、验证和测试集目录 train_dir = os.path.join(dest_dir, 'train') val_dir = os.path.join(dest_dir, 'val') test_dir = os.path.join(dest_dir, 'test') os.makedirs(train_dir, exist_ok=True) os.makedirs(val_dir, exist_ok=True) os.makedirs(test_dir, exist_ok=True) # 获取原始数据中的类别目录 classes = [d for d in os.listdir(src_dir) if os.path.isdir(os.path.join(src_dir, d))] for cls in classes: # 创建对应类别的目录 os.makedirs(os.path.join(train_dir, cls), exist_ok=True) os.makedirs(os.path.join(val_dir, cls), exist_ok=True) os.makedirs(os.path.join(test_dir, cls), exist_ok=True) # 获取该类别下的所有图片 class_dir = os.path.join(src_dir, cls) images = [img for img in os.listdir(class_dir) if img.endswith(('.jpg', '.jpeg', '.png'))] # 首先分割出测试集 train_val_imgs, test_imgs = train_test_split(images, test_size=test_size, random_state=random_state) # 从剩余部分分割出验证集 train_imgs, val_imgs = train_test_split(train_val_imgs, test_size=val_size / (1 - test_size), random_state=random_state) # 复制图片到对应目录 for img in train_imgs: src_path = os.path.join(class_dir, img) dest_path = os.path.join(train_dir, cls, img) shutil.copy2(src_path, dest_path) for img in val_imgs: src_path = os.path.join(class_dir, img) dest_path = os.path.join(val_dir, cls, img) shutil.copy2(src_path, dest_path) for img in test_imgs: src_path = os.path.join(class_dir, img) dest_path = os.path.join(test_dir, cls, img) shutil.copy2(src_path, dest_path) # 统计数据集大小 print("数据集分割完成:") print(f"训练集: {sum(len(os.listdir(os.path.join(train_dir, cls))) for cls in classes)} 张图片") print(f"验证集: {sum(len(os.listdir(os.path.join(val_dir, cls))) for cls in classes)} 张图片") print(f"测试集: {sum(len(os.listdir(os.path.join(test_dir, cls))) for cls in classes)} 张图片") def get_data_transforms(): """ 获取数据增强和预处理的转换 返回: - 包含训练、验证和测试转换的字典 """ data_transforms = { 'train': transforms.Compose([ transforms.RandomResizedCrop(224), transforms.RandomHorizontalFlip(), transforms.RandomRotation(15), transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2), transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) ]), 'val': transforms.Compose([ transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) ]), 'test': transforms.Compose([ transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) ]), } return data_transforms # 如果直接运行此脚本,则执行数据集组织
if __name__ == '__main__': import argparse parser = argparse.ArgumentParser(description='组织数据集') parser.add_argument('--src_dir', type=str, required=True, help='原始数据目录') parser.add_argument('--dest_dir', type=str, default='data/monkeypox', help='目标数据目录') parser.add_argument('--test_size', type=float, default=0.2, help='测试集比例') parser.add_argument('--val_size', type=float, default=0.15, help='验证集比例') args = parser.parse_args() organize_dataset(args.src_dir, args.dest_dir, args.test_size, args.val_size)
3. models.py 模型实现
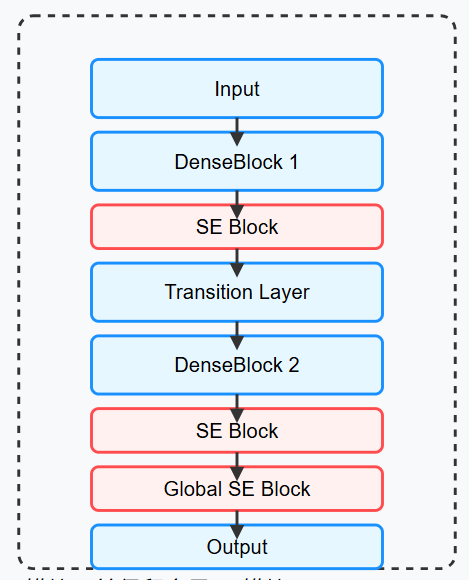
总体思路:在每次一个DenseBlock后面添加一个SE模块,最后全局再加一个SE模块,实现如下:
import torch
import torch.nn as nn
import torch.nn.functional as F
import math class SELayer(nn.Module): """ SE-Net注意力机制模块 参数: - channel: 输入特征图的通道数 - reduction: 降维比例,用于控制SE模块的复杂度 """ def __init__(self, channel, reduction=16): super(SELayer, self).__init__() # 全局平均池化,将每个通道的特征压缩为一个数值 self.avg_pool = nn.AdaptiveAvgPool2d(1) # 两个全连接层,形成"瓶颈"结构 self.fc = nn.Sequential( nn.Linear(channel, channel // reduction, bias=False), nn.ReLU(inplace=True), nn.Linear(channel // reduction, channel, bias=False), nn.Sigmoid() ) def forward(self, x): b, c, _, _ = x.size() # 全局平均池化 y = self.avg_pool(x).view(b, c) # 通过全连接层得到通道注意力权重 y = self.fc(y).view(b, c, 1, 1) # 将权重应用到原始特征图上 return x * y.expand_as(x) class _DenseLayer(nn.Module): """ DenseNet的基本层,包含BN-ReLU-Conv结构 """ def __init__(self, num_input_features, growth_rate, bn_size, drop_rate): super(_DenseLayer, self).__init__() # DenseNet的基本卷积结构:BN-ReLU-Conv(1x1) -> BN-ReLU-Conv(3x3) self.norm1 = nn.BatchNorm2d(num_input_features) self.relu1 = nn.ReLU(inplace=True) self.conv1 = nn.Conv2d(num_input_features, bn_size * growth_rate, kernel_size=1, stride=1, bias=False) self.norm2 = nn.BatchNorm2d(bn_size * growth_rate) self.relu2 = nn.ReLU(inplace=True) self.conv2 = nn.Conv2d(bn_size * growth_rate, growth_rate, kernel_size=3, stride=1, padding=1, bias=False) self.drop_rate = drop_rate def forward(self, x): new_features = self.conv1(self.relu1(self.norm1(x))) new_features = self.conv2(self.relu2(self.norm2(new_features))) if self.drop_rate > 0: new_features = F.dropout(new_features, p=self.drop_rate, training=self.training) # DenseNet的特点:将输入和输出进行拼接 return torch.cat([x, new_features], 1) class _DenseBlock(nn.Module): """ DenseNet的密集块,由多个_DenseLayer组成 """ def __init__(self, num_layers, num_input_features, bn_size, growth_rate, drop_rate): super(_DenseBlock, self).__init__() self.layers = nn.ModuleList() for i in range(num_layers): layer = _DenseLayer( num_input_features + i * growth_rate, growth_rate=growth_rate, bn_size=bn_size, drop_rate=drop_rate ) self.layers.append(layer) def forward(self, x): for layer in self.layers: x = layer(x) return x class _Transition(nn.Module): """ DenseNet中的过渡层,用于降低特征图的尺寸和通道数 """ def __init__(self, num_input_features, num_output_features): super(_Transition, self).__init__() self.norm = nn.BatchNorm2d(num_input_features) self.relu = nn.ReLU(inplace=True) self.conv = nn.Conv2d(num_input_features, num_output_features, kernel_size=1, stride=1, bias=False) self.pool = nn.AvgPool2d(kernel_size=2, stride=2) def forward(self, x): x = self.norm(x) x = self.relu(x) x = self.conv(x) x = self.pool(x) return x class ImprovedDenseNet_SE(nn.Module): """ 改进的DenseNet结合SE-Net的完整网络结构 在每个DenseBlock后添加SE模块,而不是每个层 """ def __init__(self, growth_rate=32, block_config=(6, 12, 24, 16), num_init_features=64, bn_size=4, drop_rate=0, num_classes=1000, use_se=True, se_reduction=16): super(ImprovedDenseNet_SE, self).__init__() self.use_se = use_se self.se_reduction = se_reduction # 初始卷积层 self.features = nn.Sequential() self.features.add_module('conv0', nn.Conv2d(3, num_init_features, kernel_size=7, stride=2, padding=3, bias=False)) self.features.add_module('norm0', nn.BatchNorm2d(num_init_features)) self.features.add_module('relu0', nn.ReLU(inplace=True)) self.features.add_module('pool0', nn.MaxPool2d(kernel_size=3, stride=2, padding=1)) # DenseBlock和Transition层 num_features = num_init_features for i, num_layers in enumerate(block_config): # 添加DenseBlock block = _DenseBlock( num_layers=num_layers, num_input_features=num_features, bn_size=bn_size, growth_rate=growth_rate, drop_rate=drop_rate ) self.features.add_module(f'denseblock{i + 1}', block) num_features = num_features + num_layers * growth_rate # 添加SE模块在每个DenseBlock后 if use_se: # 根据特征图通道数动态调整降维比例 actual_reduction = max(4, num_features // se_reduction) se_block = SELayer(num_features, reduction=actual_reduction) self.features.add_module(f'se_block{i + 1}', se_block) # 除了最后一个block,其他block后面都跟一个transition层 if i != len(block_config) - 1: trans = _Transition( num_input_features=num_features, num_output_features=num_features // 2 ) self.features.add_module(f'transition{i + 1}', trans) num_features = num_features // 2 # 最后的BatchNorm self.features.add_module('norm_final', nn.BatchNorm2d(num_features)) self.features.add_module('relu_final', nn.ReLU(inplace=True)) # 如果需要,在网络最后添加一个全局SE模块(类似TensorFlow版本) if use_se: self.global_se = SELayer(num_features, reduction=16) else: self.global_se = None # 全局平均池化和分类器 self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) self.classifier = nn.Linear(num_features, num_classes) # 参数初始化 self._initialize_weights() def _initialize_weights(self): for m in self.modules(): if isinstance(m, nn.Conv2d): nn.init.kaiming_normal_(m.weight) elif isinstance(m, nn.BatchNorm2d): nn.init.constant_(m.weight, 1) nn.init.constant_(m.bias, 0) elif isinstance(m, nn.Linear): if hasattr(m, 'bias') and m.bias is not None: nn.init.constant_(m.bias, 0) def forward(self, x): features = self.features(x) # 应用全局SE模块(如果存在) if self.global_se is not None: features = self.global_se(features) out = self.avgpool(features) out = torch.flatten(out, 1) out = self.classifier(out) return out def improved_densenet121_se(pretrained=False, **kwargs): """ 改进的DenseNet-121模型集成SE注意力机制 """ model = ImprovedDenseNet_SE( growth_rate=32, block_config=(6, 12, 24, 16), num_init_features=64, use_se=True, **kwargs) return model def improved_densenet169_se(pretrained=False, **kwargs): """ 改进的DenseNet-169模型集成SE注意力机制 """ model = ImprovedDenseNet_SE( growth_rate=32, block_config=(6, 12, 32, 32), num_init_features=64, use_se=True, **kwargs) return model
4. train.py 训练脚本
import time
import copy
import torch
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix, classification_report
import seaborn as sns
from torch.optim.lr_scheduler import CosineAnnealingLR, ReduceLROnPlateau
import torch.nn.functional as F # 参考网上资料与代码
def train_model_improved(model, dataloaders, criterion, optimizer, device, num_epochs=25, model_path='checkpoints/densenet_se_improved_best.pth', mixup_alpha=0.2, label_smoothing=0.1): """ 优化的训练模型函数,增加了学习率调度器、Mixup数据增强和标签平滑 参数: - model: 待训练的模型 - dataloaders: 训练和验证数据加载器 - criterion: 损失函数 - optimizer: 优化器 - device: 训练设备(CPU/GPU) - num_epochs: 训练轮数 - model_path: 保存最佳模型的路径 - mixup_alpha: Mixup增强的alpha参数 - label_smoothing: 标签平滑系数 返回: - model: 训练好的模型 """ since = time.time() # 用于保存训练历史 history = { 'train_loss': [], 'val_loss': [], 'train_acc': [], 'val_acc': [] } best_model_wts = copy.deepcopy(model.state_dict()) best_acc = 0.0 # 使用Cosine退火学习率 # scheduler = CosineAnnealingLR(optimizer, T_max=num_epochs, eta_min=1e-6) # 使用动态学习率调度器 scheduler = ReduceLROnPlateau(optimizer, mode='min', factor=0.2, patience=3, verbose=True) for epoch in range(num_epochs): print(f'Epoch {epoch + 1}/{num_epochs}') print('-' * 10) # 每个epoch都包含训练和验证阶段 for phase in ['train', 'val']: if phase == 'train': model.train() # 设置模型为训练模式 else: model.eval() # 设置模型为评估模式 running_loss = 0.0 running_corrects = 0 # 用于记录预测结果和真实标签 all_preds = [] all_labels = [] # 遍历数据 for inputs, labels in dataloaders[phase]: inputs = inputs.to(device) labels = labels.to(device) # 梯度清零 optimizer.zero_grad() # 前向传播 # 只有在训练模式下才启用梯度计算 with torch.set_grad_enabled(phase == 'train'): # 应用Mixup数据增强(仅在训练阶段) if phase == 'train' and mixup_alpha > 0: inputs, labels_a, labels_b, lam = mixup_data(inputs, labels, mixup_alpha, device) outputs = model(inputs) _, preds = torch.max(outputs, 1) # 使用Mixup标签 loss = mixup_criterion(criterion, outputs, labels_a, labels_b, lam) else: outputs = model(inputs) _, preds = torch.max(outputs, 1) # 应用标签平滑(仅在训练阶段) if phase == 'train' and label_smoothing > 0: loss = cross_entropy_with_label_smoothing(outputs, labels, label_smoothing) else: loss = criterion(outputs, labels) # 如果是训练阶段,则反向传播+优化 if phase == 'train': loss.backward() # 梯度裁剪,防止梯度爆炸 torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0) optimizer.step() # 统计 running_loss += loss.item() * inputs.size(0) # 如果是Mixup,使用原始标签计算准确率 if phase == 'train' and mixup_alpha > 0: _, original_preds = torch.max(outputs, 1) running_corrects += torch.sum(original_preds == labels.data) else: running_corrects += torch.sum(preds == labels.data) # 收集结果用于计算混淆矩阵 if phase == 'val': # 只在验证阶段收集 all_preds.extend(preds.cpu().numpy()) all_labels.extend(labels.cpu().numpy()) # 计算损失和准确率 epoch_loss = running_loss / len(dataloaders[phase].dataset) epoch_acc = running_corrects.double() / len(dataloaders[phase].dataset) # 记录历史 if phase == 'train': history['train_loss'].append(epoch_loss) history['train_acc'].append(epoch_acc.cpu().numpy()) else: history['val_loss'].append(epoch_loss) history['val_acc'].append(epoch_acc.cpu().numpy()) # 学习率调整 scheduler.step(epoch_loss) print(f'{phase} Loss: {epoch_loss:.4f} Acc: {epoch_acc:.4f}') # 如果是验证阶段,且准确率提高,则保存最佳模型 if phase == 'val' and epoch_acc > best_acc: best_acc = epoch_acc best_model_wts = copy.deepcopy(model.state_dict()) # 保存最佳模型 torch.save(best_model_wts, model_path) print(f'Best model saved with accuracy: {best_acc:.4f}') # 计算混淆矩阵 cm = confusion_matrix(all_labels, all_preds) # 绘制混淆矩阵 plt.figure(figsize=(10, 8)) sns.heatmap(cm, annot=True, fmt='d', cmap='Blues') plt.title(f'Confusion Matrix (Epoch {epoch + 1})') plt.ylabel('True Label') plt.xlabel('Predicted Label') plt.savefig(f'confusion_matrix_improved_epoch_{epoch + 1}.png') plt.close() # 打印分类报告 print("\nClassification Report:") print(classification_report(all_labels, all_preds)) print() time_elapsed = time.time() - since print(f'Training complete in {time_elapsed // 60:.0f}m {time_elapsed % 60:.0f}s') print(f'Best val Acc: {best_acc:.4f}') # 绘制训练过程 plot_training(history, num_epochs) # 加载最佳模型权重 model.load_state_dict(best_model_wts) return model def mixup_data(x, y, alpha=0.2, device=None): """ Mixup数据增强 """ if alpha > 0: lam = np.random.beta(alpha, alpha) else: lam = 1 batch_size = x.size()[0] index = torch.randperm(batch_size).to(device) mixed_x = lam * x + (1 - lam) * x[index, :] y_a, y_b = y, y[index] return mixed_x, y_a, y_b, lam # 参考网上资料
def mixup_criterion(criterion, pred, y_a, y_b, lam): """ Mixup损失函数 """ return lam * criterion(pred, y_a) + (1 - lam) * criterion(pred, y_b) def cross_entropy_with_label_smoothing(outputs, targets, smoothing=0.1): """ 带标签平滑的交叉熵损失 """ batch_size = targets.size(0) num_classes = outputs.size(1) # 将标签转换为one-hot编码 targets_one_hot = torch.zeros(batch_size, num_classes, device=outputs.device) targets_one_hot.scatter_(1, targets.unsqueeze(1), 1) # 应用标签平滑 targets_smooth = (1 - smoothing) * targets_one_hot + smoothing / num_classes # 计算损失 log_probs = F.log_softmax(outputs, dim=1) loss = -(targets_smooth * log_probs).sum(dim=1).mean() return loss def plot_training(history, num_epochs): """ 绘制训练和验证损失/准确率变化曲线 参数: - history: 训练历史字典 - num_epochs: 训练轮数 """ epochs = range(1, num_epochs + 1) # 绘制损失曲线 plt.figure(figsize=(12, 4)) plt.subplot(1, 2, 1) plt.plot(epochs, history['train_loss'], 'b-', label='Training Loss') plt.plot(epochs, history['val_loss'], 'r-', label='Validation Loss') plt.title('Training and Validation Loss') plt.xlabel('Epochs') plt.ylabel('Loss') plt.legend() # 绘制准确率曲线 plt.subplot(1, 2, 2) plt.plot(epochs, history['train_acc'], 'b-', label='Training Accuracy') plt.plot(epochs, history['val_acc'], 'r-', label='Validation Accuracy') plt.title('Training and Validation Accuracy') plt.xlabel('Epochs') plt.ylabel('Accuracy') plt.legend() plt.tight_layout() plt.savefig('training_history_improved.png') plt.close() print("Training visualization saved as 'training_history_improved.png'")
5. main.py 主文件
import argparse
import os
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
import random
import numpy as np
from tqdm import tqdm from improved_models import improved_densenet121_se
from train_improved import train_model_improved
from predict import predict
from evaluate import evaluate_model, eval_class_accuracy def seed_everything(seed=42): """设置随机种子以确保实验可重复性""" random.seed(seed) os.environ['PYTHONHASHSEED'] = str(seed) np.random.seed(seed) torch.manual_seed(seed) torch.cuda.manual_seed(seed) torch.backends.cudnn.deterministic = True torch.backends.cudnn.benchmark = False def main(): # 设置随机种子 seed_everything(42) # 添加调试信息 print("启动程序...") print(f"当前工作目录: {os.getcwd()}") # 参数解析 parser = argparse.ArgumentParser(description='改进的DenseNet-SE图像分类模型') parser.add_argument('--data_dir', type=str, default='./data', help='数据集路径') parser.add_argument('--batch_size', type=int, default=32, help='批量大小') parser.add_argument('--num_epochs', type=int, default=50, help='训练轮数') parser.add_argument('--lr', type=float, default=0.001, help='学习率') parser.add_argument('--num_classes', type=int, default=2, help='类别数量') parser.add_argument('--pretrained', action='store_true', help='是否使用预训练模型') parser.add_argument('--mode', type=str, default='train', choices=['train', 'predict', 'test'], help='运行模式:训练、预测或测试') parser.add_argument('--model_path', type=str, default='checkpoints/densenet_se_improved_best.pth', help='模型路径') parser.add_argument('--test_dir', type=str, default=None, help='测试集目录路径,默认为data_dir/test') parser.add_argument('--test_image', type=str, default=None, help='预测单张图片的路径') parser.add_argument('--device', type=str, default=None, help='使用的设备(cpu/cuda)') parser.add_argument('--mixup_alpha', type=float, default=0.2, help='Mixup增强的alpha系数') parser.add_argument('--label_smoothing', type=float, default=0.1, help='标签平滑系数') parser.add_argument('--weight_decay', type=float, default=1e-4, help='权重衰减系数') args = parser.parse_args() # 设置测试集目录 if args.test_dir is None: args.test_dir = os.path.join(args.data_dir, 'test') # 检查数据目录是否存在 print(f"检查数据目录是否存在: {os.path.exists(args.data_dir)}") if os.path.exists(args.data_dir): print(f"数据目录内容: {os.listdir(args.data_dir)}") train_dir = os.path.join(args.data_dir, 'train') val_dir = os.path.join(args.data_dir, 'val') if os.path.exists(train_dir): print(f"训练集类别: {os.listdir(train_dir)}") if os.path.exists(val_dir): print(f"验证集类别: {os.listdir(val_dir)}") # 数据转换 data_transforms = { 'train': transforms.Compose([ transforms.RandomResizedCrop(224), transforms.RandomHorizontalFlip(), transforms.RandomRotation(15), transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2), transforms.RandomAffine(degrees=0, translate=(0.1, 0.1)), transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) ]), 'val': transforms.Compose([ transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) ]), 'test': transforms.Compose([ transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) ]), } # 检查设备 if args.device: device = torch.device(args.device) else: device = torch.device("cuda" if torch.cuda.is_available() else "cpu") print(f"Using device: {device}") # 创建模型 print("创建改进的DenseNet-SE模型...") model = improved_densenet121_se(pretrained=args.pretrained, num_classes=args.num_classes) model = model.to(device) # 运行模式判断 if args.mode == 'train': # 创建数据集 try: print("加载数据集...") image_datasets = { x: datasets.ImageFolder(os.path.join(args.data_dir, x), data_transforms[x]) for x in ['train', 'val'] } # 使用带进度条的数据加载器 dataloaders = { x: DataLoader( image_datasets[x], batch_size=args.batch_size, shuffle=True, num_workers=4, pin_memory=True ) for x in ['train', 'val'] } except Exception as e: print(f"加载数据集时出错: {e}") print("请确保数据集目录结构如下:") print("data/") print("├── train/") print("│ ├── class1/") print("│ └── class2/") print("└── val/") print(" ├── class1/") print(" └── class2/") return dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'val']} class_names = image_datasets['train'].classes print(f"类别名称: {class_names}") print(f"训练集大小: {dataset_sizes['train']}") print(f"验证集大小: {dataset_sizes['val']}") # 创建检查点目录 os.makedirs('checkpoints', exist_ok=True) # 定义损失函数和优化器 criterion = nn.CrossEntropyLoss() # 使用Adam优化器,加入权重衰减 optimizer = optim.Adam(model.parameters(), lr=args.lr, weight_decay=args.weight_decay) # 训练模型 print(f"开始训练改进版DenseNet-SE模型...") print(f"训练配置: 批量大小={args.batch_size}, 学习率={args.lr}, 权重衰减={args.weight_decay}") print(f"数据增强: Mixup alpha={args.mixup_alpha}, 标签平滑={args.label_smoothing}") train_model_improved( model, dataloaders, criterion, optimizer, device, num_epochs=args.num_epochs, model_path=args.model_path, mixup_alpha=args.mixup_alpha, label_smoothing=args.label_smoothing ) elif args.mode == 'test': # 加载模型权重 if os.path.exists(args.model_path): model.load_state_dict(torch.load(args.model_path, map_location=device)) print(f"已加载模型: {args.model_path}") # 执行测试集评估 if os.path.exists(args.test_dir): print(f"在测试集上评估模型: {args.test_dir}") # 整体评估 accuracy, _, _ = evaluate_model( model, args.test_dir, device, data_transforms['test'], batch_size=args.batch_size ) # 每个类别的评估 eval_class_accuracy( model, args.test_dir, device, data_transforms['test'], batch_size=args.batch_size ) print(f"\n总体测试准确率: {accuracy:.4f}") else: print(f"错误: 测试集目录 '{args.test_dir}' 不存在!") else: print(f"错误: 模型文件 '{args.model_path}' 不存在!") elif args.mode == 'predict': # 加载模型权重 if os.path.exists(args.model_path): model.load_state_dict(torch.load(args.model_path, map_location=device)) print(f"Loaded model from {args.model_path}") # 执行预测 if args.test_image: predict(model, args.test_image, device, data_transforms['test']) else: print("请提供测试图像路径") else: print(f"模型文件 {args.model_path} 不存在") if __name__ == '__main__': main()
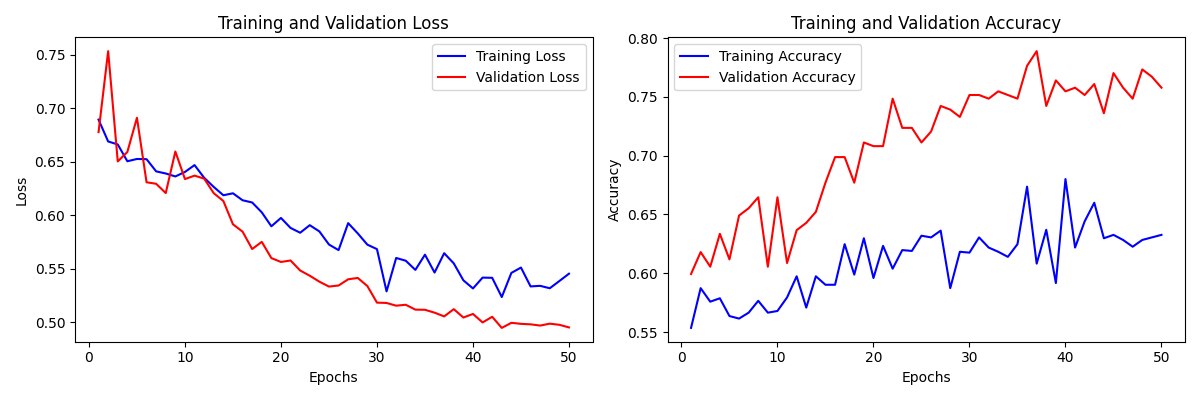
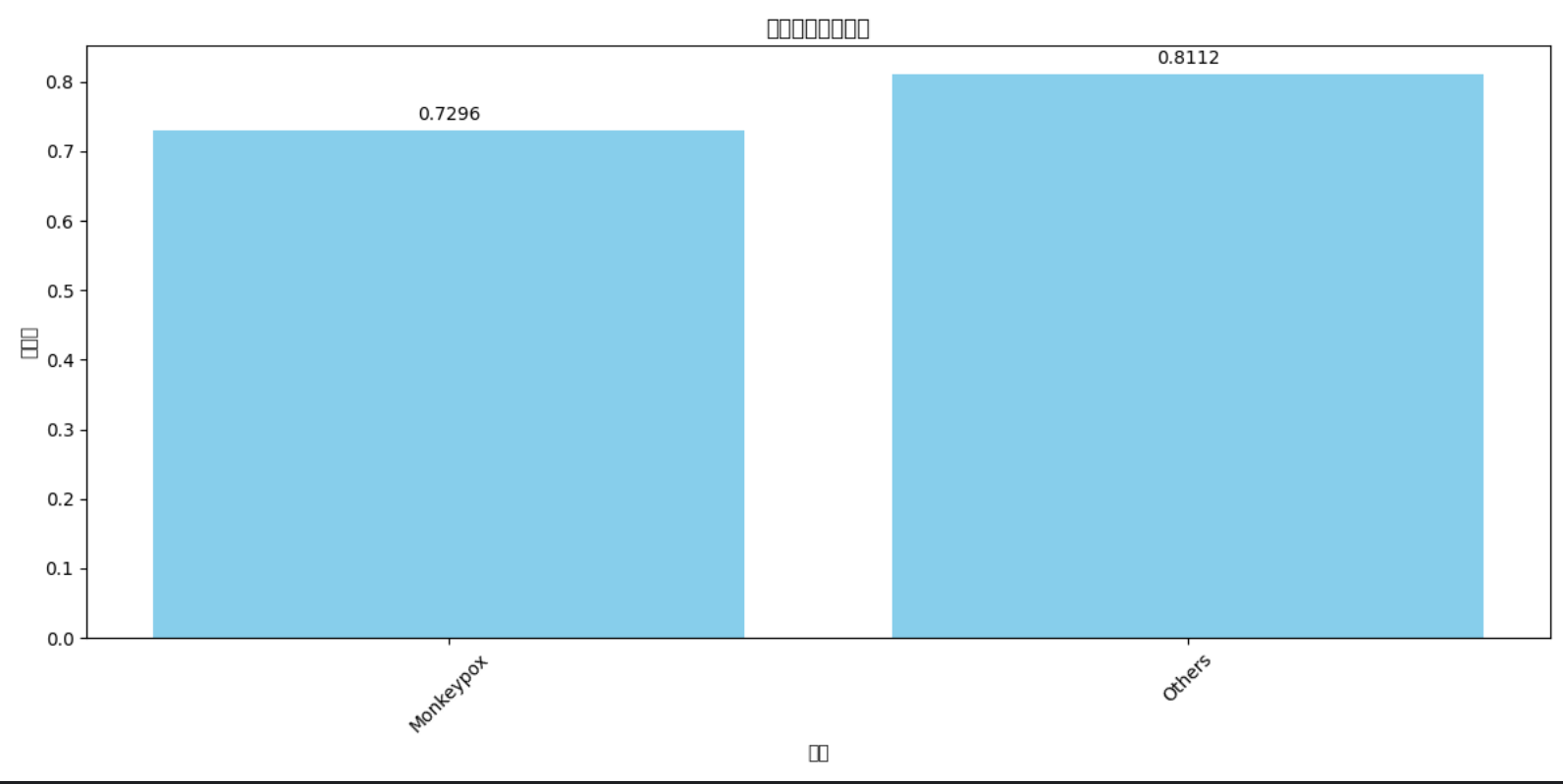
测试集准确率是77%,没有达到80%
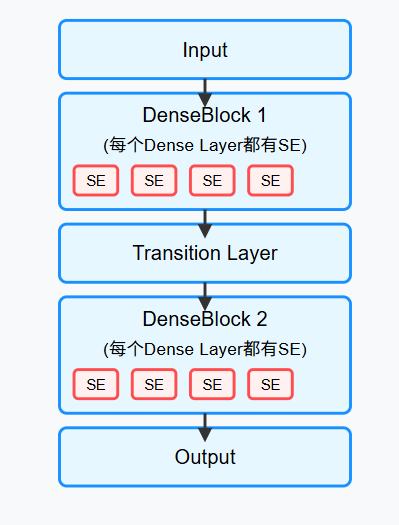
6. 改进models.py
思路:在每一个DenseBlock中的每个Dense Layer上加一个SE模块试试:
import torch
import torch.nn as nn
import torch.nn.functional as F
import math class SELayer(nn.Module): """ SE-Net注意力机制模块 参数: - channel: 输入特征图的通道数 - reduction: 降维比例,用于控制SE模块的复杂度 """ def __init__(self, channel, reduction=16): super(SELayer, self).__init__() # 全局平均池化,将每个通道的特征压缩为一个数值 self.avg_pool = nn.AdaptiveAvgPool2d(1) # 两个全连接层,形成"瓶颈"结构 self.fc = nn.Sequential( nn.Linear(channel, channel // reduction, bias=False), nn.ReLU(inplace=True), nn.Linear(channel // reduction, channel, bias=False), nn.Sigmoid() ) def forward(self, x): b, c, _, _ = x.size() # 全局平均池化 y = self.avg_pool(x).view(b, c) # 通过全连接层得到通道注意力权重 y = self.fc(y).view(b, c, 1, 1) # 将权重应用到原始特征图上 return x * y.expand_as(x) class _DenseLayer(nn.Module): """ DenseNet的基本层,包含BN-ReLU-Conv结构,并集成SE注意力机制 """ def __init__(self, num_input_features, growth_rate, bn_size, drop_rate, use_se=True, reduction=16): super(_DenseLayer, self).__init__() self.use_se = use_se # DenseNet的基本卷积结构:BN-ReLU-Conv(1x1) -> BN-ReLU-Conv(3x3) self.norm1 = nn.BatchNorm2d(num_input_features) self.relu1 = nn.ReLU(inplace=True) self.conv1 = nn.Conv2d(num_input_features, bn_size * growth_rate, kernel_size=1, stride=1, bias=False) self.norm2 = nn.BatchNorm2d(bn_size * growth_rate) self.relu2 = nn.ReLU(inplace=True) self.conv2 = nn.Conv2d(bn_size * growth_rate, growth_rate, kernel_size=3, stride=1, padding=1, bias=False) # SE注意力机制层 if use_se: self.se = SELayer(growth_rate, reduction) self.drop_rate = drop_rate def forward(self, x): new_features = self.conv1(self.relu1(self.norm1(x))) new_features = self.conv2(self.relu2(self.norm2(new_features))) # 添加SE注意力机制 if self.use_se: new_features = self.se(new_features) if self.drop_rate > 0: new_features = F.dropout(new_features, p=self.drop_rate, training=self.training) # DenseNet的特点:将输入和输出进行拼接 return torch.cat([x, new_features], 1) class _DenseBlock(nn.Sequential): """ DenseNet的密集块,由多个_DenseLayer组成 """ def __init__(self, num_layers, num_input_features, bn_size, growth_rate, drop_rate, use_se=True, reduction=16): super(_DenseBlock, self).__init__() for i in range(num_layers): layer = _DenseLayer( num_input_features + i * growth_rate, growth_rate=growth_rate, bn_size=bn_size, drop_rate=drop_rate, use_se=use_se, reduction=reduction ) self.add_module('denselayer%d' % (i + 1), layer) class _Transition(nn.Sequential): """ DenseNet中的过渡层,用于降低特征图的尺寸和通道数 """ def __init__(self, num_input_features, num_output_features): super(_Transition, self).__init__() self.norm = nn.BatchNorm2d(num_input_features) self.relu = nn.ReLU(inplace=True) self.conv = nn.Conv2d(num_input_features, num_output_features, kernel_size=1, stride=1, bias=False) self.pool = nn.AvgPool2d(kernel_size=2, stride=2) class DenseNet_SE(nn.Module): """ DenseNet结合SE-Net的完整网络结构 """ def __init__(self, growth_rate=32, block_config=(6, 12, 24, 16), num_init_features=64, bn_size=4, drop_rate=0, num_classes=1000, use_se=True, reduction=16): super(DenseNet_SE, self).__init__() # 初始卷积层 self.features = nn.Sequential( nn.Conv2d(3, num_init_features, kernel_size=7, stride=2, padding=3, bias=False), nn.BatchNorm2d(num_init_features), nn.ReLU(inplace=True), nn.MaxPool2d(kernel_size=3, stride=2, padding=1), ) # DenseBlock和Transition层 num_features = num_init_features for i, num_layers in enumerate(block_config): # 添加DenseBlock block = _DenseBlock( num_layers=num_layers, num_input_features=num_features, bn_size=bn_size, growth_rate=growth_rate, drop_rate=drop_rate, use_se=use_se, reduction=reduction ) self.features.add_module('denseblock%d' % (i + 1), block) num_features = num_features + num_layers * growth_rate # 除了最后一个block,其他block后面都跟一个transition层 if i != len(block_config) - 1: trans = _Transition( num_input_features=num_features, num_output_features=num_features // 2 ) self.features.add_module('transition%d' % (i + 1), trans) num_features = num_features // 2 # 最后的BatchNorm self.features.add_module('norm5', nn.BatchNorm2d(num_features)) # 分类器 self.classifier = nn.Linear(num_features, num_classes) # 参数初始化 for m in self.modules(): if isinstance(m, nn.Conv2d): nn.init.kaiming_normal_(m.weight) elif isinstance(m, nn.BatchNorm2d): nn.init.constant_(m.weight, 1) nn.init.constant_(m.bias, 0) elif isinstance(m, nn.Linear): # 确保bias存在才进行初始化 if hasattr(m, 'bias') and m.bias is not None: nn.init.constant_(m.bias, 0) def forward(self, x): features = self.features(x) out = F.relu(features, inplace=True) out = F.adaptive_avg_pool2d(out, (1, 1)) out = torch.flatten(out, 1) out = self.classifier(out) return out def densenet121_se(pretrained=False, **kwargs): """ DenseNet-121模型集成SE注意力机制 """ model = DenseNet_SE( growth_rate=32, block_config=(6, 12, 24, 16), num_init_features=64, use_se=True, **kwargs) return model def densenet169_se(pretrained=False, **kwargs): """ DenseNet-169模型集成SE注意力机制 """ model = DenseNet_SE( growth_rate=32, block_config=(6, 12, 32, 32), num_init_features=64, use_se=True, **kwargs) return model def densenet201_se(pretrained=False, **kwargs): """ DenseNet-201模型集成SE注意力机制 """ model = DenseNet_SE( growth_rate=32, block_config=(6, 12, 48, 32), num_init_features=64, use_se=True, **kwargs) return model
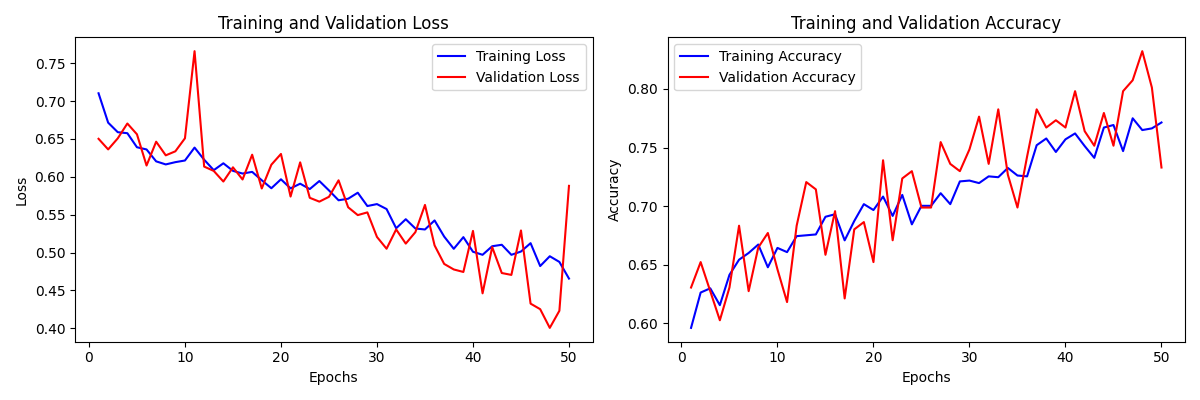
还是没有超过80%的识别率。