Doris表设计与分区策略:让海量数据管理更高效
在大数据时代,面对每日激增的PB级数据,如何设计高效的数据表结构,成为每个数据工程师的必修课。Apache Doris作为实时分析领域的明星产品,其独特的分区、分桶策略和智能管理能力,能帮助企业轻松应对海量数据挑战。本文将带你解锁Doris分区设计的核心技巧,让你的数据查询效率提升10倍!
数据分布概述
为了确保数据均匀分布在各 BE 节点,避免数据倾斜导致部分节点过载,Doris 引入了分区和分桶两层逻辑对数据进行划分。分区和传统数据库没有本质的区别,主要是从业务逻辑的角度对数据进行划分;而分桶则是基于 Hash 或 Random 算法直接将数据从物理层面进一步打散。
- 数据写入时,Doris 根据表的分区策略将数据行分配到对应的分区,并根据分桶策略将数据进一步映射到分区内的具体分片,从而确定数据行的存储位置。分片是 Doris 中数据管理的最小单元,也是数据移动和复制的基本单位;
- 数据查询时,Doris 优化器会根据分区和分桶策略裁剪数据,减少数据扫描范围。
分区和分桶策略
Doris 分区支持两种类型:
- Range 分区:根据分区列的值范围将数据行分配到对应分区,适用于时间和序列号等单向递增数据类型;
- List 分区:根据分区列的具体值将数据行分配到对应的分区,适用于取值范围比较固定的数据类型,比如省份和地区等。
分桶也支持两种方式:
- Hash 分桶:通过计算分桶列值的 crc32 哈希值,对分桶数取模,将数据行均匀分布到分片中;
- Random 分桶:不依赖于某个字段的 Hash 值,随机分配数据行到分片中。Random 分桶能够确保数据均匀分散,避免由于分桶健选择不当而引发的数据倾斜问题。
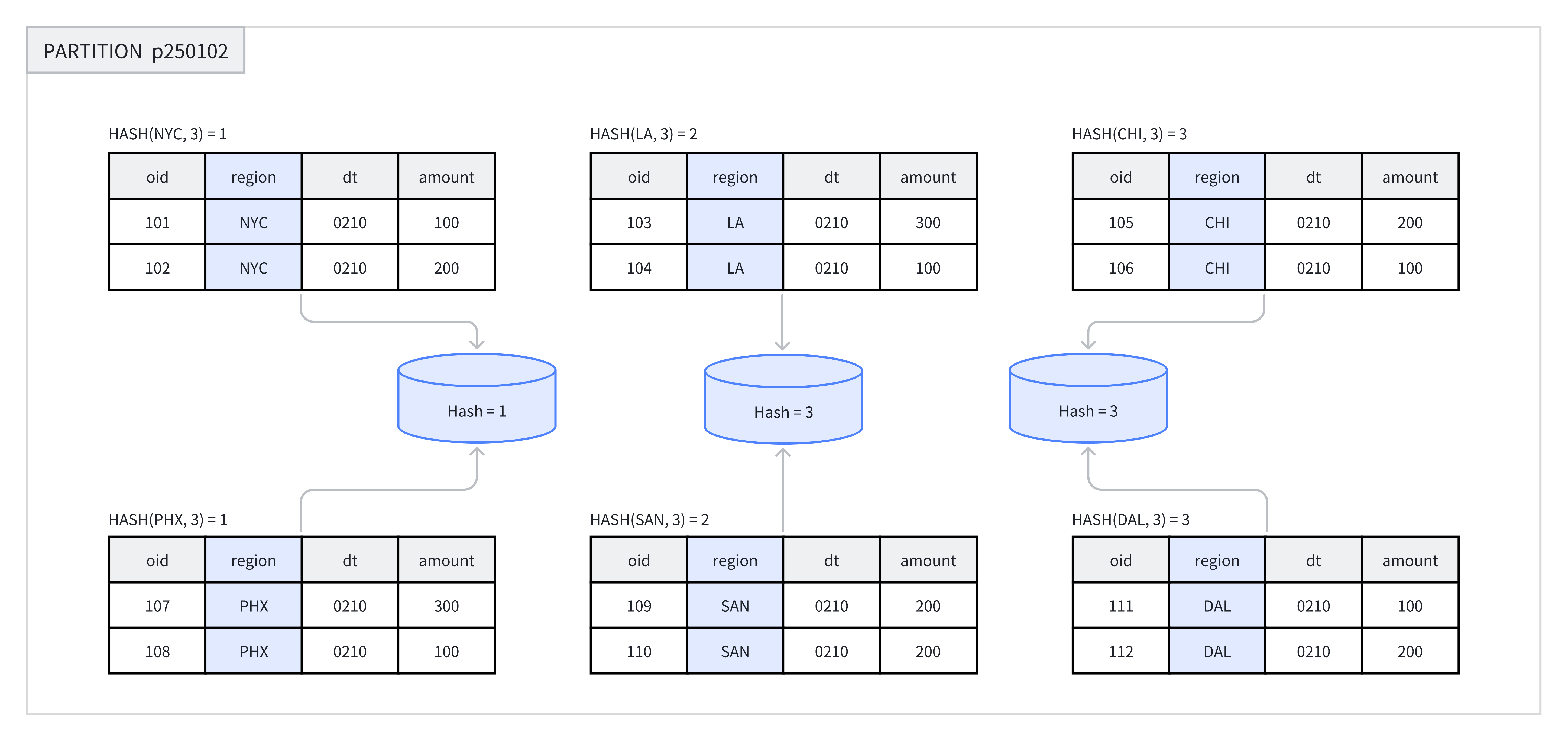
Doris 中一个分桶 (bucket) 会被存储为一个独立的数据文件 (tablet),一个表的 tablet 数量等于分区数乘以分桶数。不支持对分桶类型、分桶键和已创建的分桶数量进行修改。
分区管理方式上支持手工分区、自动分区和动态分区等三种类型:
- 手工分区:类似于传统数据库中的普通分区,分区的创建和删除等维护操作需要管理员手工进行;
- 自动分区:类似于 Oracle 数据库中的 Interval 分区,支持按照指定的范围或时间周期自动创建新的分区,当插入的数据还没有对应分区时会自动创建出来;
- 动态分区:能够按照设定的规则,滚动添加和删除分区,从而实现对表分区的生命周期管理(TTL),减少数据存储的压力。日志管理和时序数据管理等场景非常适合使用动态分区管理。
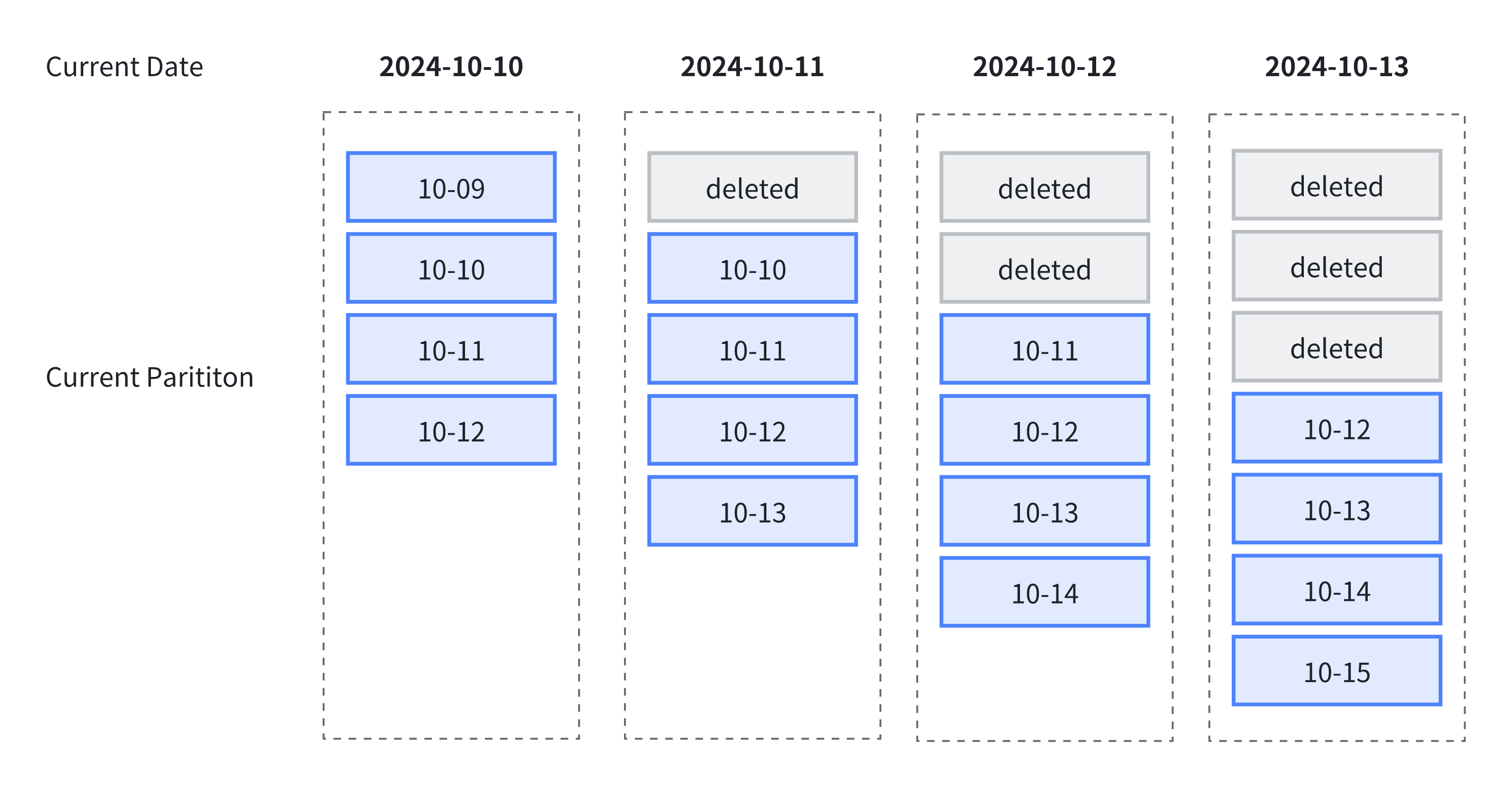
分区设计黄金原则
- 选择合适的分区键
对于时序数据场景推荐选择时间字段创建 Range 分区,对于地域、业务线等离散值的场景,推荐创建 List 分区。分区键的选择要避免高基数列,如用户 ID,同时禁止使用非稳定字段,如订单状态。
- 控制合理分区粒度
分区粒度上要避免粒度过细而导致分区数量过多,分桶数量不建议超过 128 个。通常来说,热数据的分区大小建议不要超过 5GB,温数据的分区大小不要超过 10-50GB,冷数据则控制在 100GB 左右。
- 拥抱动态分区管理
动态分区无需手工添加分区,支持自动清理历史数据释放存储,通过配置相关的策略,能够实现数据冷热分层存放及历史分区按需加载,实在是全自动分区运维的利器!
总体来说,通过精心设计和管理分区分桶策略,Doris 能够高效地支持大规模数据的存储与查询处理,满足各种复杂业务需求。
写在最后
分布式并行处理是 MPP 架构数据库的优势之一,Doris 通过分区分桶策略将数据进一步打散,以更好的发挥其并行处理能力,尤其是分桶更是将这种能力发挥到了极致。
以前专注在 Oracle 时,觉得 Oracle 就是世界上最好的数据库。这两年开始学习其他数据库,发现也有很多惊艳的设计,这些产品大大推动了数据库技术的发展,也值得从业人员深入的学习和研究!