数据库系统概论(五)关系模型的数据结构及形式化
数据库系统概论(五)关系模型的数据结构及形式化
- 前言
- 一、关系:从“表格”说起
- 1.1 关系数据模型中的“关系”是什么?
- 1.2 域(Domain):数据的“类型限定”
- 1.3 笛卡尔积(Cartesian Product):“所有可能的组合”
- 1.4 关系(Relation):笛卡尔积中有意义的“子集”
- 二、关系模式:表格的“设计蓝图”
- 2.1 关系模式是什么?
- 2.2 主属性、非码属性、全码:关于“码”的重要概念
- (1)码(Key):唯一标识一条记录的“身份证”
- (2)主属性(Prime Attribute)
- (3)非码属性(Non-Key Attribute)
- (4)全码(All-Key)
- 三、关系数据库:多个表格的“集合”
- 3.1 关系数据库的概念
- 3.2 关系数据库模式(Database Schema)
- 3.3 相关概念:外码(Foreign Key)
- 四、关系数据库的存储结构:数据怎么存到电脑里?
- 4.1 表文件(Table File)
- 4.2 索引(Index):数据的“目录”
- 4.3 数据字典(Data Dictionary):元数据的“户口本”
- 4.4 其他存储结构(进阶了解)
- 总结:
前言
- 在数据库系统概论的系列学习中,我们已经逐步揭开了数据库的神秘面纱,从基础概念到核心理论,每一步都在为深入理解数据世界搭建桥梁。
- 作为系列的第五篇,本文将聚焦关系模型的数据结构及形式化定义—— 这是理解数据库如何组织和管理数据的关键,更是后续学习数据库设计、查询优化的重要基石。
我的个人主页,欢迎来阅读我的其他文章
https://blog.csdn.net/2402_83322742?spm=1011.2415.3001.5343
我的数据库系统概论专栏
https://blog.csdn.net/2402_83322742/category_12911520.html?spm=1001.2014.3001.5482
一、关系:从“表格”说起
1.1 关系数据模型中的“关系”是什么?
简单来说,“关系”就是一张二维表格,比如学生信息表、成绩表。但在数据库里,它有更严谨的定义,我们从最基础的概念开始:
1.2 域(Domain):数据的“类型限定”
- 定义:域是一组具有相同数据类型的值的集合。
比如:- “性别”域 = {男,女}
- “年龄”域 = {0, 1, 2, …, 150}(限定整数)
- “姓名”域 = {所有合法的字符串}(比如不超过20个字符)
作用:确保表格里每一列的数据“合法”,比如年龄列不能填字母。
1.3 笛卡尔积(Cartesian Product):“所有可能的组合”
假设我们有两个域:
- 姓名域 = {张三,李四}
- 年龄域 = {18,20}
它们的笛卡尔积就是 所有可能的“姓名+年龄”组合,形成一张表:
| 姓名 | 年龄 |
|---|---|
| 张三 | 18 |
| 张三 | 20 |
| 李四 | 18 |
| 李四 | 20 |
特点:笛卡尔积会列出两个域的所有组合,不管是否有实际意义(比如“张三20岁”可能存在,但“李四18岁”也可能存在)。
1.4 关系(Relation):笛卡尔积中有意义的“子集”
现实中的表格不会包含所有无意义的组合,而是只保留“有效数据”。
关系 = 笛卡尔积中满足特定条件的子集。
比如真实的学生表可能只有:
| 学号 | 姓名 | 年龄 |
|---|---|---|
| 1 | 张三 | 18 |
| 2 | 李四 | 20 |
关系的三个类型:
- 基本表(Base Table):实际存储数据的表,比如学生表、成绩表。
- 查询表(Query Table):查询结果临时生成的表(比如“筛选年龄>18的学生”得到的表)。
- 视图表(View Table):虚拟表,通过现有表定义的“逻辑表”(比如“学生+成绩”的联合视图,不实际存储数据)。
关系的性质(表格的“规矩”):
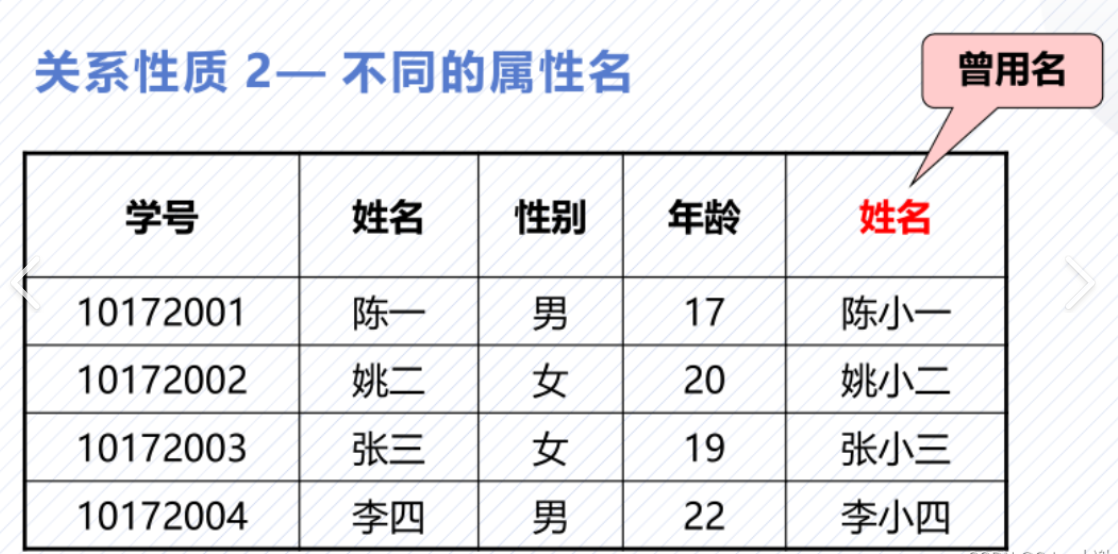
- 字段(列)无序:交换“姓名”和“年龄”列的顺序,表的意义不变。
- 记录(行)唯一:不能有完全相同的两行(比如两个学号相同的学生)。
- 字段有唯一名称:同一表中不能有两个“年龄”列。
- 字段值不可分割:每个单元格只能存一个值(比如“地址”列不能同时存“北京”和“朝阳”)。
二、关系模式:表格的“设计蓝图”
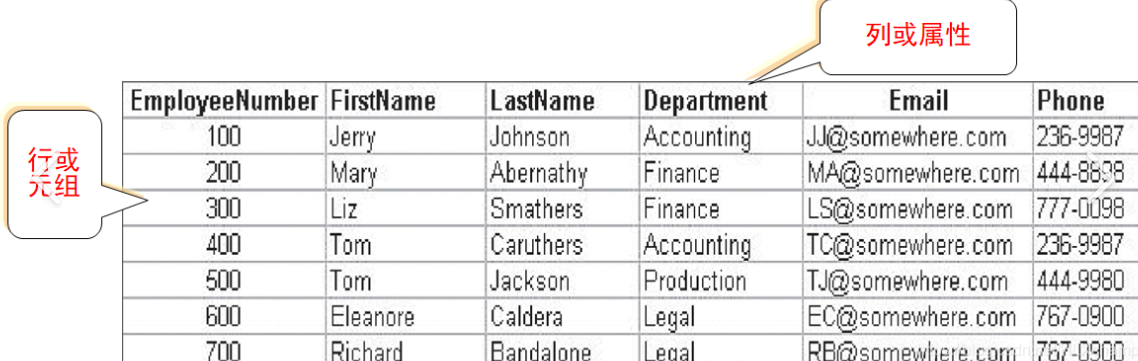
2.1 关系模式是什么?
关系模式 = 表格的结构定义,就像盖房子前的设计图,规定了表格有哪些列、列的类型、约束等。
比如学生表的关系模式可以表示为:
学生表(学号, 姓名, 年龄, 班级)
- 学生表是表名,
- 括号里的内容是列(属性)的名称。
2.2 主属性、非码属性、全码:关于“码”的重要概念
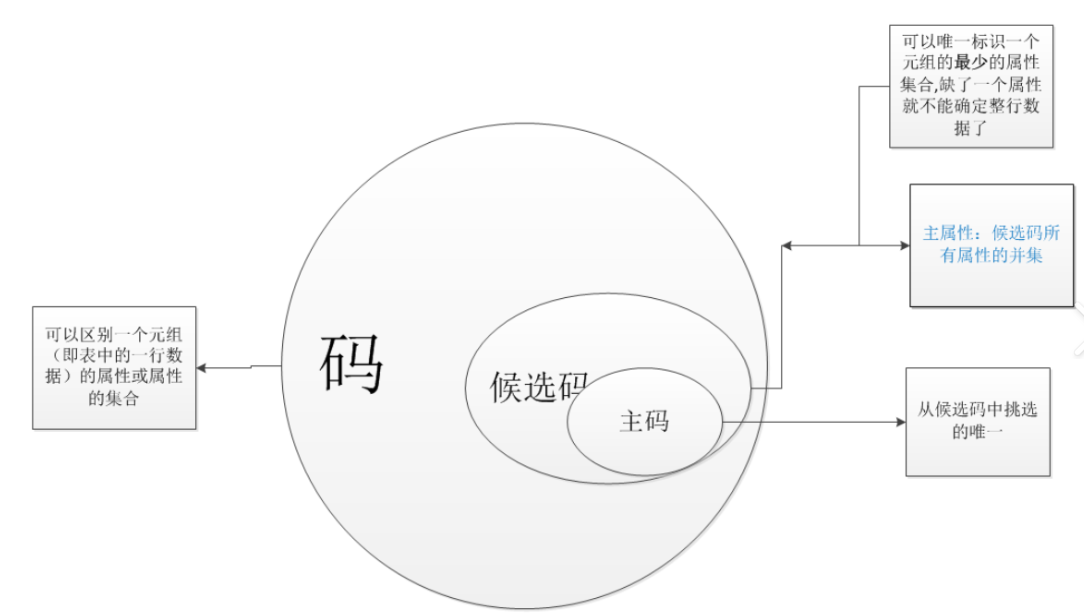
(1)码(Key):唯一标识一条记录的“身份证”
- 主码(Primary Key):能唯一标识一条记录的最小属性组。
比如“学号”可以作为学生表的主码(每个学号对应唯一学生)。 - 候选码(Candidate Key):可能成为主码的多个属性(主码是候选码的一个)。
比如学生表中如果“身份证号”也唯一,那么“学号”和“身份证号”都是候选码。
(2)主属性(Prime Attribute)
包含在任何一个候选码中的属性。
比如“学号”和“身份证号”是主属性(因为它们是候选码),而“姓名”可能不是(可能有重名)。
(3)非码属性(Non-Key Attribute)
不包含在任何候选码中的属性。
比如学生表中的“年龄”,即使年龄相同,只要学号不同,就是不同记录。
(4)全码(All-Key)
当表的候选码是“所有属性的组合”时,称为全码。
比如“学生选课表”有三个属性:学生(学号)、课程(课程号)、成绩。
此时,“学号+课程号”共同作为主码(单独一个无法唯一标识一条选课记录),所以它们都是主属性,这种情况不算全码。
全码的例子:如果有一个表只有“学生”和“朋友”两个属性(表示学生和朋友的关系),且每对关系唯一(比如“张三-李四”和“李四-张三”视为不同记录),那么主码就是“学生+朋友”,即全码(所有属性都是主码的一部分)。
三、关系数据库:多个表格的“集合”
3.1 关系数据库的概念
关系数据库 = 多个“关系”(表格)的集合,这些表格通过“关联”(比如共享主码)组织在一起。
比如一个学校的数据库可能包含:
- 学生表(记录学生信息,主码:学号)
- 课程表(记录课程信息,主码:课程号)
- 成绩表(记录学生选课成绩,主码:学号+课程号)
3.2 关系数据库模式(Database Schema)
所有关系模式的“总设计图”,定义了整个数据库的结构。
比如上面的例子,数据库模式包括:
学生表(学号, 姓名, 年龄, 班级)
课程表(课程号, 课程名, 学分)
成绩表(学号, 课程号, 成绩)
3.3 相关概念:外码(Foreign Key)
外码是一个表中的属性,它引用另一个表的主码,用于建立表之间的关联。
比如成绩表中的“学号”引用学生表的“学号”(主码),“课程号”引用课程表的“课程号”(主码)。
作用:确保数据一致性(比如成绩表中的学号必须存在于学生表中,否则选课记录无效),这就是“参照完整性”(之前讲过的概念)。
四、关系数据库的存储结构:数据怎么存到电脑里?
数据库最终要把数据存到硬盘上,存储结构决定了数据如何组织和读取。以下是常见的存储结构:
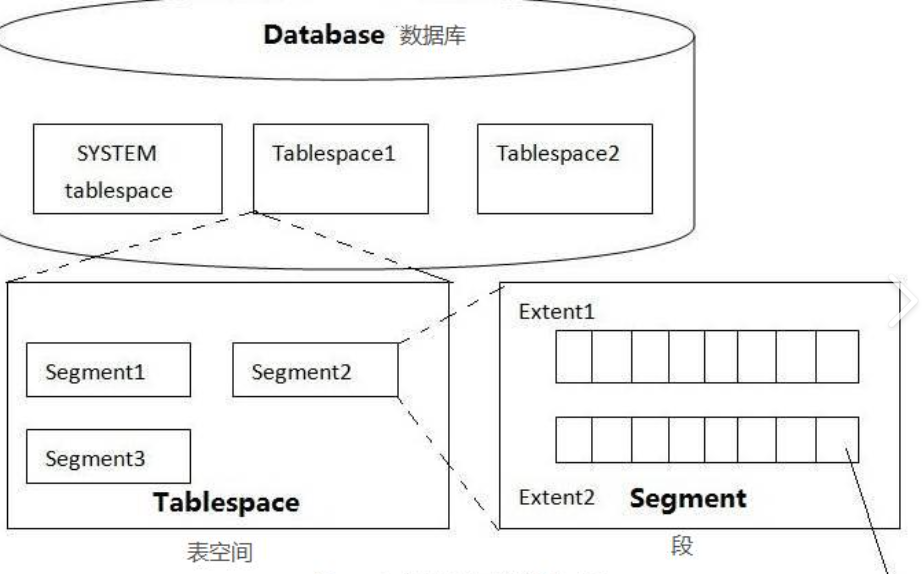
4.1 表文件(Table File)
最基本的存储单位,一个表对应一个或多个文件。
- 存储形式:
- 可以是简单的文本文件(如CSV,每行一条记录,逗号分隔列),但数据库通常用更高效的二进制格式(如MySQL的
.ibd文件)。 - 例子:学生表的数据会按行存储,每个字段的类型(如整数、字符串)对应特定的二进制格式。
- 可以是简单的文本文件(如CSV,每行一条记录,逗号分隔列),但数据库通常用更高效的二进制格式(如MySQL的
优点:结构清晰,直接对应表格。
缺点:如果表很大,查找数据会很慢(比如找“年龄=20”的学生,可能要扫描整个文件)。
4.2 索引(Index):数据的“目录”
为快速查询创建的“数据字典”,就像书的目录,记录了某个值对应的存储位置。
- 例子:给学生表的“学号”建索引,索引会记录“学号1→存储位置0x123”,“学号2→存储位置0x456”,这样查学号时不用扫描全表,直接通过索引定位。
- 类型:
- 单值索引(如按“学号”“年龄”建索引)
- 组合索引(如按“班级+年龄”建索引,加快同时筛选这两个条件的查询)。
优点:大幅提升查询速度。
缺点:占用额外存储空间,添加/修改数据时需要更新索引,影响写入速度。
4.3 数据字典(Data Dictionary):元数据的“户口本”
存储数据库自身信息的“元数据”,比如:
- 每个表的结构(有哪些列,列的类型、约束)
- 索引的定义(哪个表的哪个列有索引)
- 用户权限(谁能访问哪个表)
例子:在MySQL中,数据字典存放在系统库information_schema中,比如查询COLUMNS表可以看到所有表的列信息。
作用:数据库管理系统(如MySQL、Oracle)通过数据字典知道如何管理数据,就像老师知道每个学生的档案才能更好地管理班级。
4.4 其他存储结构(进阶了解)
- 聚簇存储(Clustering):把相关表的数据放在一起(比如学生表和成绩表按学号排序存储),加快关联查询。
- 分区(Partitioning):把大表分成多个小文件(如按年份分区存储订单表),方便管理和查询。
总结:
- 关系:最基础的“表格”,由域和笛卡尔积定义,有严格的性质(如记录唯一、列无序)。
- 关系模式:表格的设计蓝图,定义了主码、主属性等,确保数据结构合理。
- 关系数据库:多个表格的集合,通过外码关联,形成完整的数据体系。
- 存储结构:数据在硬盘上的组织方式,表文件存数据,索引加速查询,数据字典记录元数据,让数据库高效运行。
以上就是这篇博客的全部内容,下一篇我们将继续探索更多精彩内容。
我的个人主页,欢迎来阅读我的其他文章
https://blog.csdn.net/2402_83322742?spm=1011.2415.3001.5343
我的数据库系统概论专栏
https://blog.csdn.net/2402_83322742/category_12911520.html?spm=1001.2014.3001.5482
| 非常感谢您的阅读,喜欢的话记得三连哦 |
