c++学习小结
内存分配
空间
栈区(stack)。编译器⾃动分配与释放,主要存放函数的参数值,局部变量值等,连续的内存空 间,由⾼地址向低地址扩展。
堆区(heap) 。由程序员分配与释放;不连续的空间,通过空闲链表进⾏连接。堆是低地址向⾼ 地址扩展,空间较⼤。频繁地分配和释放不同⼤⼩的堆空间将会产⽣堆内碎块。
静态存储区。存放全局变量和静态变量;分为全局初始化区和全局未初始化区。
常量存储区。存放常量字符串;对于全局常量,编译器⼀般不分配内存,放在符号表中以提⾼访问 效率。
程序代码区。存放函数体的⼆进制代码。
对象内存分配方式
class Base {public:Base(){cout << "Hello, world!base base" << "\n";}~Base(){cout << "Hello, world!base ~base" << "\n";}void go() {cout << "Hello, world!base go" << "\n";}
};class Player : public Base{public:Player(){cout << "Hello, world!player base" << "\n";}~Player(){cout << "Hello, world!player ~base" << "\n";}void go() {cout << "Hello, world!player" << "\n";}
};栈空间分配
1函数结束而回收(会调用析构函数) 创建时会调用构造函数
int main()
{Base base;return 0;
}输出

new 堆空间分配
1. 分配未初始化的内存空间(malloc)。若出现问题则抛出异常
2. 使⽤对象的构造函数进⾏初始化。若出现异常则⾃动调⽤delete释放内存
3 使用delete回收(会调用析构函数) 创建时会调用构造函数
int main()
{Base *base = new Base;base->go();delete base;return 0;
}输出
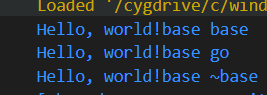
malloc 堆空间分配
1 通过 brk() 系统调⽤从堆分配内存:如果⽤户分配的内存⼩于 128 KB,就是通过 brk() 函 数将「堆顶」指针向⾼地址移动,获得新的内存空间。free 释放内存的时候,并不会把内存归还给 操作系统,⽽是缓存在 malloc 的内存池中,待下次使⽤;
2 通过 mmap() 系统调⽤在⽂件映射区域分配内存。free 释放内存的时候,会把内存归还给 操作系统,内存得到真正的释放
3 使用free回收
int main()
{Base *base = (Base*)malloc(sizeof(Base));base->go();free(base);return 0;
}输出
![]()
构造函数和析构函数
class Base {public:Base(){cout << "Hello, world!base base" << "\n";}~Base(){cout << "Hello, world!base ~base" << "\n";}void go() {cout << "Hello, world!base go" << "\n";}
};如果在栈空间分配 那么声明时就调用构造函数
函数结束时调用析构函数
如果是用new在堆空间分配
new时会调用构造函数
delete时会调用析构函数
子类和父类
class Base {public:Base(){cout << "Hello, world!base base" << "\n";}~Base(){cout << "Hello, world!base ~base" << "\n";}void go() {cout << "Hello, world!base go" << "\n";}
};class Player : public Base{public:Player(){cout << "Hello, world!player base" << "\n";}~Player(){cout << "Hello, world!player ~base" << "\n";}void go() {cout << "Hello, world!player" << "\n";}
};int main()
{Player *player = new Player;delete player;return 0;
}输出 可以发现构造函数是先调用父类的再调用子类的
析构函数则相反 先子类再父类的
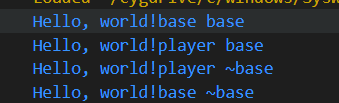
子类实例化父类
int main()
{Base *base = new Player;base->go();delete base;return 0;
}输出 可以看到构造函数还是会父类加子类的 但是本质上base还是Base类的对象 所以go函数调用的还是父类的接口
析构函数调用的是父类的
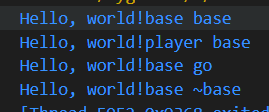
虚函数
若类可能被继承,且需通过基类指针管理派生类对象,基类析构函数必须为虚函数
也就是父类想调用子类的函数 那么就使用虚函数
class Base {public:Base(){cout << "Hello, world!base base" << "\n";}virtual ~Base(){cout << "Hello, world!base ~base" << "\n";}virtual void go() {cout << "Hello, world!base go" << "\n";}
};int main()
{Base *base = new Player;base->go();delete base;return 0;
}输出
可以看到构造函数还是 父类加子类的
但是go函数调用的是子类的接口
然后析构函数是子类再加父类的 因为父类的析构函数也是虚函数
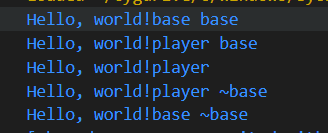
虚函数也会占用对象的内存大小
volatile、extern区别
volatile int i=10;
在cpu内核中有l1 l2 l3缓存
每个核心拥有自己的l2 每个核心的超线程拥有自己的l1 所有核心共享l3
那么l1 和内存就有相同数据的多份拷贝
volatile的变量就是每次读就是读内存中的数据 不读l缓存的数据
extern声明的对象或者函数 表明读取全局的对象 有外部连接性 表示使用的是其他文件的对象
预处理、编译、汇编、链接
预处理阶段:预处理器根据 # 开头的命令,修改原始的程序,如把头⽂件插⼊到程序⽂本中,删除所有 的注释等。
编译阶段:编译过程就是把预处理完的⽂件进⾏⼀系列的词法分析、语法分析、语义分析等,最终产⽣ 相应的汇编语⾔⽂件,不同的⾼级语⾔翻译的汇编语⾔相同。编译是对源⽂件分别进⾏的,每个源⽂件 都产⽣⼀个⽬标⽂件。
汇编阶段:把汇编语⾔代码翻译成⽬标机器指令。
链接阶段:将有关的⽬标⽂件和库⽂件相连接,使得所有的这些⽂件成为⼀个能够被操作系统装⼊执⾏ 的统⼀整体。链接处理可分为两种: 静态链接:函数的代码将从其所在的静态链接库中被拷⻉到最终的可执⾏⽂件中。这样程序在被执 ⾏时会将其装⼊到该进程的虚拟地址空间中。
静态链接库实际上是⼀个⽬标⽂件的集合,其中的每 个⽂件含有库中的⼀个或者⼀组相关函数的代码。
动态链接:函数的代码被 放到 称作是动态链接库或共享对象的某个⽬标⽂件中。
链接程序要做的 只是在最终的可执⾏⽂件中记录下相对应的信息。在可执⾏⽂件被执⾏时,根据可执⾏程序中记录 的信息,将动态链接库的全部内容映射到相应运⾏进程的虚拟地址空间上。 对于可执⾏⽂件中的函数调⽤,可分别采⽤动态链接或静态链接的⽅法。使⽤动态链接能够使最终的可 执⾏⽂件⽐较短⼩,并且当共享对象被多个进程使⽤时能节约⼀些内存,因为在内存中只需要保存⼀份 此共享对象的代码。但并不是使⽤动态链接就⼀定⽐使⽤静态链接要优越
数据结构
数组
int arr[5] = {1, 2, 3, 4, 5};
cout << arr[0]; // 输出第一个元素结构体
struct Person {string name;int age;
};
Person p = {"Alice", 25};
cout << p.name << endl; // 输出 Alice栈
stack<int> s;
s.push(1);
s.push(2);
cout << s.top(); // 输出 2
s.pop();队列
queue<int> q;
q.push(1);
q.push(2);
cout << q.front(); // 输出 1
q.pop();哈希表
unordered_map<string, int> hashTable;
hashTable["apple"] = 10;
cout << hashTable["apple"]; // 输出 10映射
map<string, int> myMap;
myMap["apple"] = 10;
cout << myMap["apple"]; // 输出 10集合
set<int> s;
s.insert(1);
s.insert(2);
cout << *s.begin(); // 输出 1动态数组
vector<int> v;
v.push_back(1);
v.push_back(2);
cout << v[0]; // 输出 1