【大模型】图像生成 - Stable Diffusion 深度解析:原理、应用与实战指南
Stable Diffusion 深度解析:原理、应用与实战指南
- 1. 什么是 Stable Diffusion?
- 关键特性
- 2. 核心原理:扩散模型与潜在空间
- 扩散模型(Diffusion Model)
- 潜在扩散(Latent Diffusion)
- 条件控制
- 3. 应用场景
- 4. 实战指南:本地部署与运行
- 环境配置
- 基础生成代码
- 参数调优
- 5. 常见问题与解决方案
- 问题1:显存不足(CUDA Out of Memory)
- 问题2:生成图像与文本不符
- 问题3:生成速度慢
- 6. 相关论文与技术资源
- 7. 总结与展望
1. 什么是 Stable Diffusion?
Stable Diffusion 是一种基于 扩散模型(Diffusion Model) 的生成式人工智能模型,主要用于生成高质量图像。其核心思想是通过逐步添加和去除噪声的过程,从随机噪声中合成逼真图像。与传统的 GAN(生成对抗网络)相比,Stable Diffusion 在生成多样性、图像质量和训练稳定性上表现更优。
关键特性
- 开源免费:代码与预训练模型公开,支持本地部署。
- 高效性:通过潜在空间(Latent Space)压缩图像,降低计算成本。
- 多功能性:支持文本到图像(Text-to-Image)、图像修复(Inpainting)、图像扩展(Outpainting)等任务。
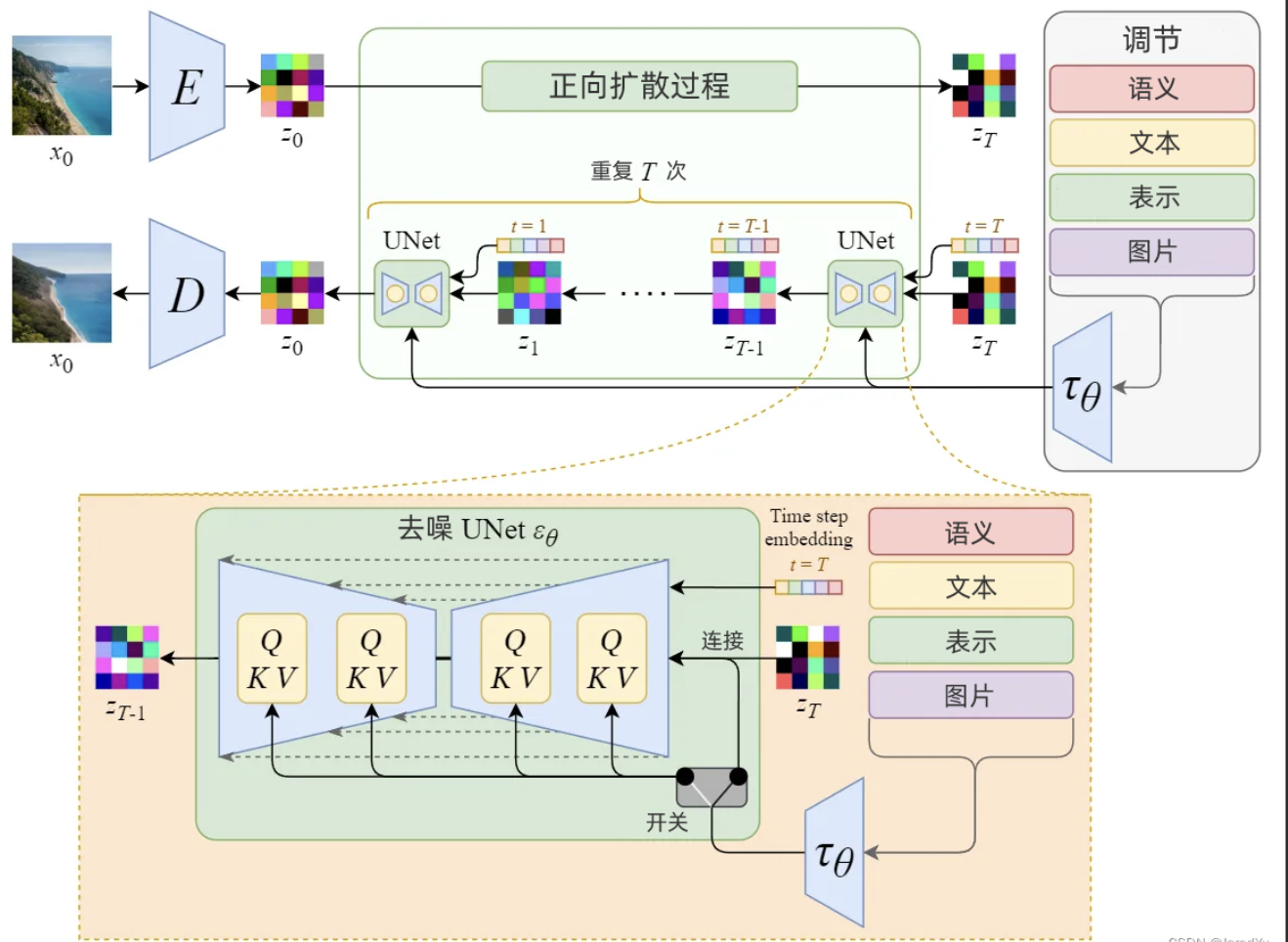
2. 核心原理:扩散模型与潜在空间
扩散模型(Diffusion Model)
扩散模型的训练分为两个阶段:
- 前向过程(加噪):
逐步向输入图像添加高斯噪声,直到图像完全变为随机噪声。 - 反向过程(去噪):
训练一个神经网络(如 U-Net)学习如何从噪声中逐步恢复原始图像。
潜在扩散(Latent Diffusion)
Stable Diffusion 的创新在于引入 潜在空间:
- 编码器(VAE):将高分辨率图像压缩到低维潜在空间(如 64×64)。
- 扩散过程:在潜在空间中执行加噪和去噪,大幅减少计算量。
- 解码器(VAE):将潜在表示解码回像素空间生成最终图像。
条件控制
通过 文本编码器(如 CLIP),将文本提示(Prompt)转化为嵌入向量,指导生成过程:
3. 应用场景
- 文本到图像生成
输入描述性文本(如“赛博朋克风格的未来城市”),生成符合语义的图像。 - 图像修复与编辑
擦除或修改图像中的特定区域(如去除水印、替换背景)。 - 超分辨率重建
将低分辨率图像提升至高分辨率。 - 艺术创作
生成插画、概念设计、游戏素材等。 - 科学研究
生成合成数据以增强数据集(如医学影像)。
4. 实战指南:本地部署与运行
环境配置
# 安装依赖库
pip install diffusers transformers accelerate torch
基础生成代码
from diffusers import StableDiffusionPipeline
import torch# 加载预训练模型(需Hugging Face账号登录)
model_id = "runwayml/stable-diffusion-v1-5"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to("cuda")# 输入提示词生成图像
prompt = "A futuristic city under the neon lights, cyberpunk style"
image = pipe(prompt).images[0]
image.save("output.png")
参数调优
num_inference_steps:去噪步数(默认50,步数越多细节越丰富,但耗时增加)。guidance_scale:文本引导强度(7-15为常用范围,值越高越贴近文本描述)。negative_prompt:负向提示词(排除不想要的内容,如“blurry, low quality”)。
5. 常见问题与解决方案
问题1:显存不足(CUDA Out of Memory)
- 解决方法:
- 启用低显存模式:
pipe.enable_attention_slicing()。 - 使用 FP16 精度:加载模型时指定
torch_dtype=torch.float16。 - 缩小图像尺寸:如生成 512×512 而非 1024×1024。
- 启用低显存模式:
问题2:生成图像与文本不符
- 解决方法:
- 优化提示词:添加细节描述(如“4K, ultra-detailed, cinematic lighting”)。
- 调整
guidance_scale至更高值(如12)。 - 使用负面提示词排除干扰特征。
问题3:生成速度慢
- 解决方法:
- 减少
num_inference_steps(可尝试20-30步)。 - 使用更快的调度器(如
DPMSolverMultistepScheduler)。
- 减少
6. 相关论文与技术资源
-
核心论文
- High-Resolution Image Synthesis with Latent Diffusion Models
Robin Rombach et al., 2021
提出潜在扩散模型,奠定 Stable Diffusion 的理论基础。
- High-Resolution Image Synthesis with Latent Diffusion Models
-
扩展阅读
- Diffusion Models Beat GANs on Image Synthesis
- CLIP: Connecting Text and Images
-
工具与社区
- Hugging Face Diffusers:官方模型库与代码实现。
- Stable Diffusion WebUI:开源图形界面(推荐 Automatic1111 WebUI)。
7. 总结与展望
Stable Diffusion 凭借其开源性、灵活性和高质量的生成能力,已成为 AIGC(生成式 AI)领域的标杆工具。未来发展方向可能包括:
- 实时生成优化:降低硬件需求,提升生成速度。
- 多模态控制:结合语音、草图等多条件输入。
- 伦理与安全:解决版权、深度伪造等社会问题。
通过不断迭代与社区贡献,Stable Diffusion 有望在艺术、教育、科研等领域发挥更大价值。