【漫话机器学习系列】227.信息检索与数据挖掘中的常用加权技术(TF-IDF)
在自然语言处理(NLP)、信息检索(IR)和数据挖掘(DM)领域中,TF-IDF 是一种非常经典且常用的加权技术。
无论是搜索引擎排序、文本挖掘,还是特征工程,TF-IDF都扮演着重要角色。
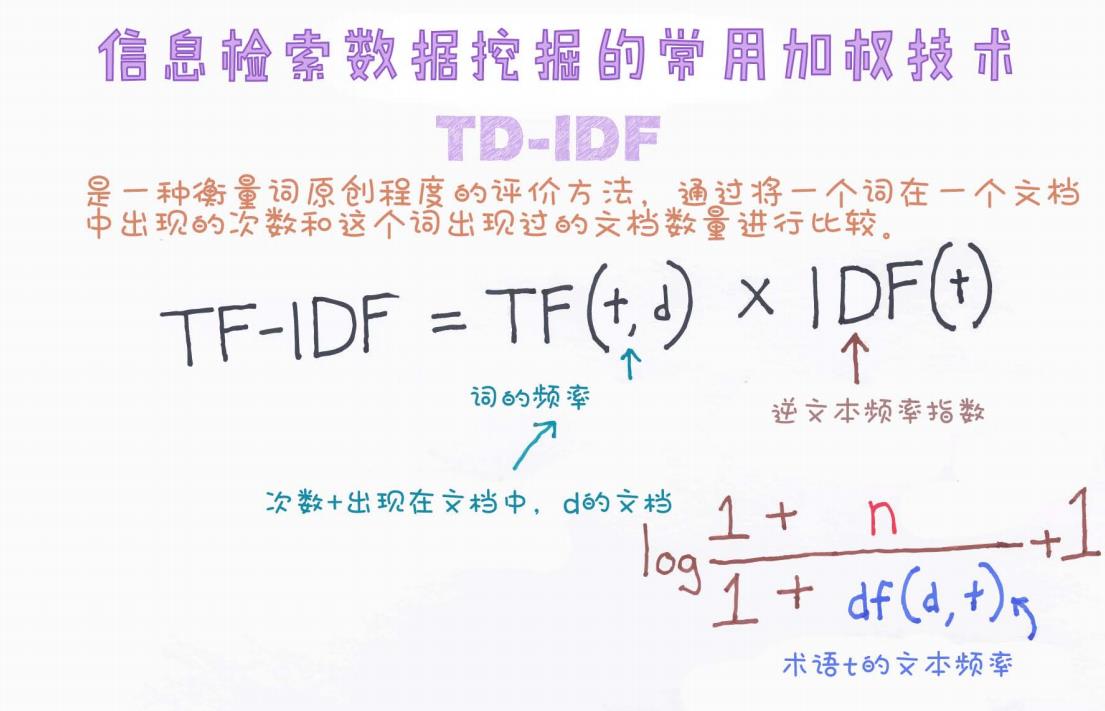
今天,我们通过一张手绘图(见下方)出发,详细理解TF-IDF的定义、公式推导及实际意义。
一、什么是TF-IDF?
TF-IDF(Term Frequency - Inverse Document Frequency),中文通常翻译为词频-逆文档频率,是一种用于评估一个词语对于一个文档集合中的某份文档的重要程度的方法。
它综合考虑了:
-
词在当前文档中出现的频率(TF)
-
词在所有文档中出现的广泛程度(IDF)
从而在文本处理中,突出那些能较好区分不同文档的关键词。
二、公式详解
根据手绘图内容,TF-IDF的标准公式如下:
其中:
-
t:词项(term)
-
d:文档(document)
接下来分别拆开解释:
1. 词频(TF, Term Frequency)
表示词t在文档d中出现的频率。
通常定义为该词在文档中出现的次数除以文档的总词数。
在手绘图中,蓝色箭头标注了:
次数 + 出现在文档中d的文档
这里强调的是,词频关注的是“在单一文档内部”,某个词出现了多少次。
2. 逆文档频率(IDF, Inverse Document Frequency)
其中:
-
n:语料库中所有文档数量
-
df(t):包含词ttt的文档数量(Document Frequency)
手绘图中,棕色箭头标注了逆文档频率的具体推导公式,并解释了每个变量的含义。
通过引入逆文档频率(IDF),可以有效降低出现在大多数文档中的常用词(比如“的”“是”等)的权重,同时提高那些在少数文档中出现、具有区分性的词的重要性。
注意:
加1操作(如公式中的 1+n、1+df(t))是为了避免分母为零或对数中出现非法运算的问题。
三、为什么要使用TF-IDF?
直接使用词频(TF)容易出现的问题是:常见但不具备实际意义的词(如"的"、"是"、"and"、"the")会有很高的频率,从而被错误地认为非常重要。
而引入逆文档频率(IDF)后,可以:
-
抑制常见词的权重
-
提升稀有词的重要性
-
更好地反映词语对特定文档的区分能力
总之,TF-IDF 是一种简单有效、广泛应用的文本特征权重评估方法。
四、应用场景
TF-IDF的应用非常广泛,包括但不限于:
-
搜索引擎:根据TF-IDF评分,返回最相关的搜索结果。
-
文本分类:作为特征向量输入到分类器(如SVM、朴素贝叶斯)。
-
关键词提取:从文档中自动提取重要关键词。
-
推荐系统:基于内容的推荐中提取文章或商品描述的关键特征。
五、举个简单例子
假设我们有三篇文档:
| 文档 | 内容 |
|---|---|
| d1 | 我 爱 自然语言处理 |
| d2 | 自然语言处理 是 人工智能 的 重要 分支 |
| d3 | 我 爱 人工智能 |
关键词 "自然语言处理":
-
在d1出现1次,在d2出现1次,在d3未出现。
-
词频TF在各自文档中可计算。
-
文档频率df为2(出现在2篇文档中)。
-
IDF根据总文档数(n=3)进行计算。
最后通过TF × IDF,就能得到每个文档中该词的重要性得分。
六、总结
-
TF-IDF是一种衡量词在文档集合中重要性的方法。
-
综合了词频(TF)和逆文档频率(IDF)两部分。
-
能有效提升文本特征的区分能力。
-
应用范围广,是文本处理领域的基础技能之一。
掌握好TF-IDF,不仅可以帮助理解传统NLP任务,也为后续深入学习如词向量(Word2Vec)、BERT等打下坚实基础!
如果这篇文章对你有帮助,欢迎点赞 👍、收藏 ⭐ 和留言讨论哦!
后续我将继续分享更多文本处理、自然语言理解的实战经验,欢迎关注~