多视觉编码器协同与高低分辨率特征融合技术综述
本文主要介绍(论文发表时间:24.03-25.01)在多模态中使用多个视觉编码器如何进行特征融合操作(之所以用多视觉编码器,主要用途在于:有些视觉编码器可能只能提取到部分信息,就想通过另外一个编码器去捕捉之前编码器所没有捕捉得到的信息;另外一种情况就是:同时输入两类输入图像:1、高分辨率图像;2、低分辨率图像。去将这两类图像编码之后图如何处理这两部分图像信息),因为视觉编码器处理的特征都是“相同”的(都是视觉维度上的内容)因此在拼接上所处理的操作也会比较单一,比如说下面这类操作:
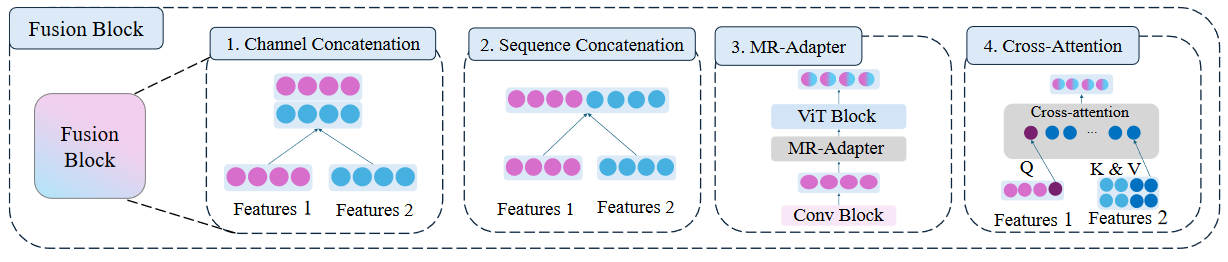
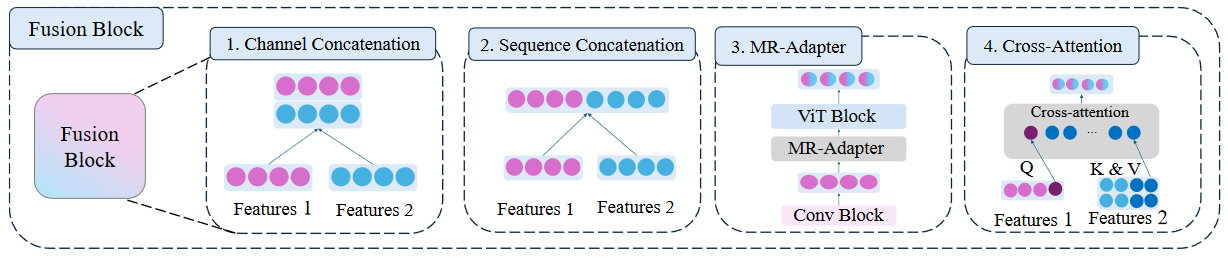
对于每类操作都会有一篇论文进行介绍:
1、Channel Concatenation:纵向拼接(Image-Encoder-1:1x4;Image-Encoder-2:1x4;得到2x4)
2、Sequence Concatenation:横向拼接(Image-Encoder-1:1x4;Image-Encoder-2:1x4;得到1x8)
3、MR-Adapter:融合拼接
4、Cross-Attention:注意力拼接
1、LEO
LEO: Boosting Mixture of Vision Encoders for Multimodal Large Language Models
From: https://arxiv.org/pdf/2501.06986
模型框架:
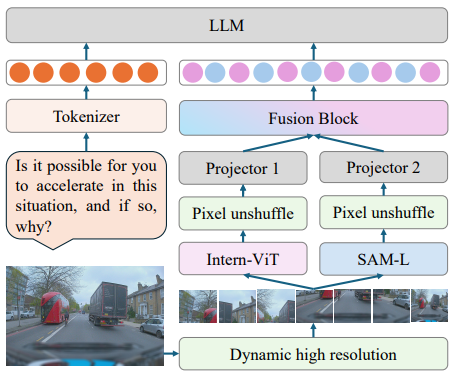
套路还是往常老套路,输入图像以及问题文本然后分别将两种模态信息进行编码然后进行拼接输入到LLM中进行处理。在处理图像过程中一如既往的使用动态分辨率操作,划分得到不同的小patch之后,就会输入到视觉编码器中,这里使用的是两种:1、Intern-Vit;2、SAM-L通过编码器处理然后通过Pixel unshuffle操作(主要是为了减少token数量)。文章中关键两点在于特征融合模块。
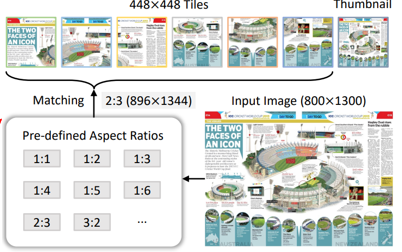
动态分辨率:首先提前设定切分图像的块的大小以及需要划分块的数量,比如说:切割的每块的分辨率为:224x224以及切分块的数量为:6,而后计算输入图像(假设:800x1300)如果切分到指定块需要修改的分辨率,比如说:224x6/800≈2那么对于宽扩展2倍,类似的长就会扩展3倍,这样分辨率就会变为:896x1344
特征融合:对图像进行encoder之后,类似很多多模态中进行操作一样都会通过一个Projector(也就是简单的线性层进行处理),多视觉编码器处理完毕之后后续关键就是如何将编码后内容进行组合,在本文中所采用的方式是:Sequence Concatenation。也就是直接将内容进行横向拼接(比如说:image-encoder-1:1x4;image-encoder-2:1x4。那么拼接得到结果为:1x8)
2、EAGLE
EAGLE: Exploring The Design Space for Multimodal LLMs with Mixture of Encoders
From: https://arxiv.org/pdf/2408.15998
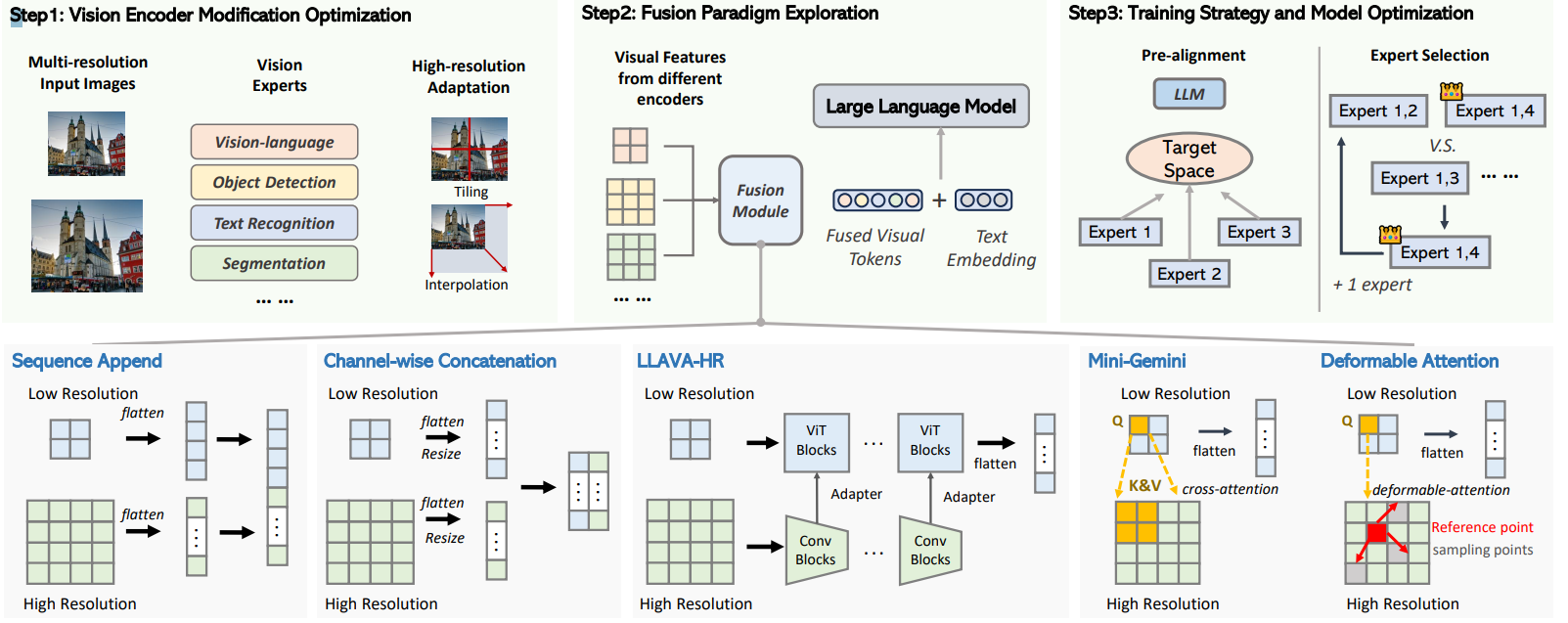
本文就是一个研究实验报告主要是讨论了:1、各种视觉编码器进行组合效果;2、各类特征融合效果。因此对于该篇论文只需要介绍解实验结果以及实验过程:
- 1、视觉编码器类型
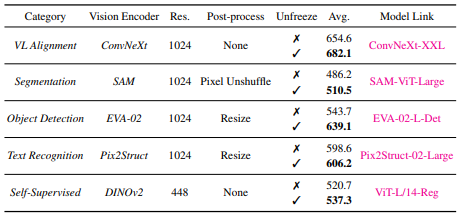
本文主要是分别使用了如下几类视觉编码器:
- 2、特征融合策略
本文主要是分别使用了如下几类特征融合策略:
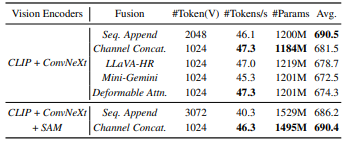
从结果上,发现Channel Concat得到的效果是最好的(对比那些花里胡哨的各种混合策略而言)
3、LLaVA-HR
Feast Your Eyes: Mixture-of-Resolution Adaptation for Multimodal Large Language Models
From: https://arxiv.org/pdf/2403.03003
模型框架:
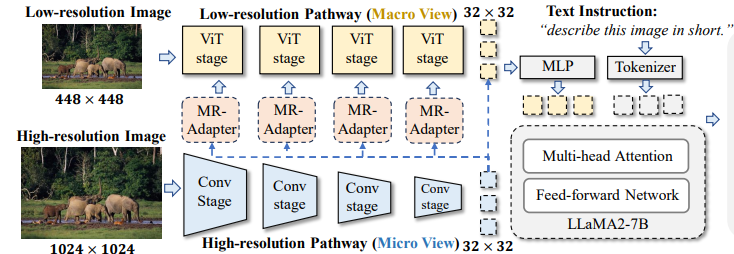
本文出发点在于:如何去处理多模态模型对于“细微”信息的捕捉能力(比如说图像中很细小的一个内容,如何争对这部分内容,模型能否捕捉到这部分信息),比较常见的作法就是:用高分辨率图像作为输入。使用高分辨率图像就会带来许多问题,比如说分辨率增加就会导致计算增加等。本文就提出:混合分辨率操作(Mixture-of-Resolution Adaptation)
本文作法也比较简单:对于高分辨率图像使用:卷积进行操作;对于低分辨率图像使用:Vit进行操作。这样做的目的在于Vit是全局注意力,视觉感受野比较大,如果用到高分辨率图像上形成的token数量就会比较多。而卷积是局部感受野,能够高效捕捉到局部特征,并且计算量上也不会太高。
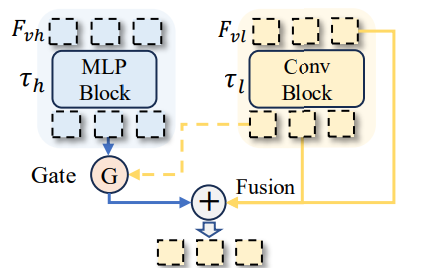
本文中使用的 MR-Adapter 操作: F v l = F v l + f l ( F v l ) + g × f h ( F v h ) F_{vl}=F_{vl}+f_l(F_{vl})+g\times f_h(F_{vh}) Fvl=Fvl+fl(Fvl)+g×fh(Fvh)。处理思路也比较简答,通过公式也可以很直观理解(其中: v l vl vl 代表低分辨率; v h vh vh :代表高分辨率, f l , f h f_l, f_h fl,fh:则是分别代表卷积block和 MLP layer)值得注意的是其中的gate定义为:
g = δ ( W 2 σ ( W 1 f v ) ) , f v = 1 h × w ∑ i h ∑ j w [ f l ( F v l ) i , j , f h ( F v h ) i , j ] \begin{aligned} & g=\delta(W_{2}\sigma(W_{1}f_{v})), \\ & f_{v}=\frac{1}{h\times w}\sum_{i}^{h}\sum_{j}^{w}[f_{l}(\mathbf{F}_{vl})^{i,j},f_{h}(\mathbf{F}_{vh})^{i,j}] \end{aligned} g=δ(W2σ(W1fv)),fv=h×w1i∑hj∑w[fl(Fvl)i,j,fh(Fvh)i,j]
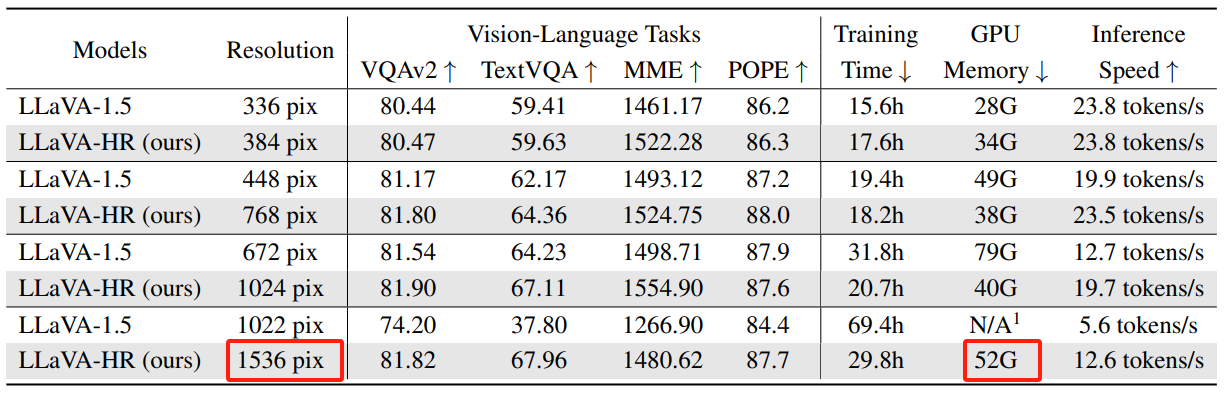
总的来说本文亮点在于使用高分辨率同时在推理速度以及显存占用上都是比较少的:
4、Mini-Gemini
Mini-Gemini: Mining the Potential of Multi-modality Vision Language Models
From: https://arxiv.org/pdf/2403.18814
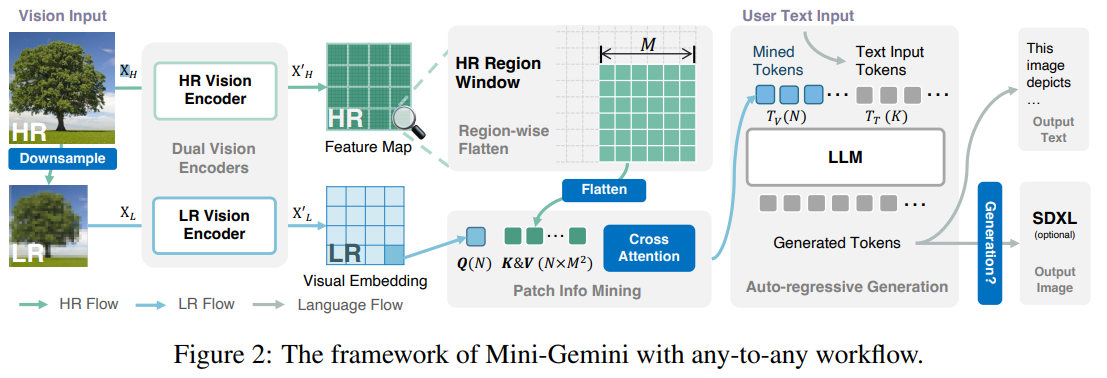
在介绍的 LLaVA-HR 中使用的是结合高分辨率图像和低分辨率图像作为输入,本文也是采用高分辨率+低分辨率(直接对高分辨率图像通过bilinear来降低分辨率)作为输入,在高/低分辨率处理上也是相似的(高分辨率:卷积网络处理;低分辨率:ViT)。不过在本文中对于不同分辨率图像“预处理”和前一篇论文有点区别,本文处理分辨率图像,假设输入高分辨率图像: X H = H × W × C X_H = H\times W\times C XH=H×W×C。低分辨率图像: X L = h × w × C X_L= h\times w\times C XL=h×w×C。低分辨率通过Vit模型处理得到: X L = N × C X_L=N\times C XL=N×C 其中 N N N 代表patch数量,对于高分辨图像处理得到: X H = N × N × C X_H=N\times N\times C XH=N×N×C 其中 N = H / 4 × W / 4 = N × M 2 N=H/4 \times W/4=N\times M^2 N=H/4×W/4=N×M2。也就是说在地分辨中的每个patch都会有一块高分辨率图像作为“信息补偿”
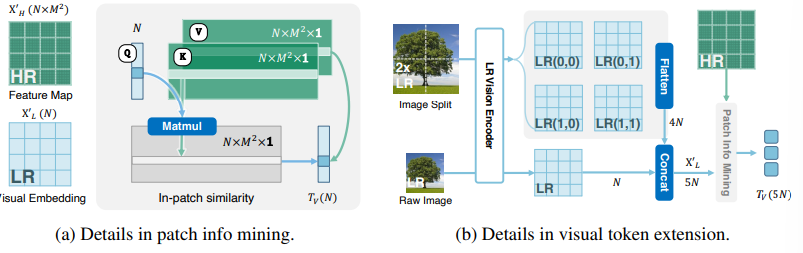
特征融合直接通过注意力方式融合即可,其中Q为低分辨率的图像信息,K/V都来自高分辨率图像信息: T V = M L P ( Q + A t t e n t i o n ( Q , K , V ) ) T_V=MLP(Q+Attention(Q,K,V)) TV=MLP(Q+Attention(Q,K,V))
总结
本文主要介绍了多视觉内容处理思路:1、多视觉编码器处理同一张图像如何将处理后图像特征进行融合;2、高/低分辨率图像如何将两部分信息进行融合。其中第2点工作(高低分辨率)具有的借鉴意义更加大。
参考
1、LEO: Boosting Mixture of Vision Encoders for Multimodal Large Language Models
2、InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks
3、BRAVE : Broadening the visual encoding of vision-language models
4、EAGLE: Exploring The Design Space for Multimodal LLMs with Mixture of Encoders
5、Mini-Gemini: Mining the Potential of Multi-modality Vision Language Models