「Mac畅玩AIGC与多模态01」架构篇01 - 展示层到硬件层的架构总览
一、概述
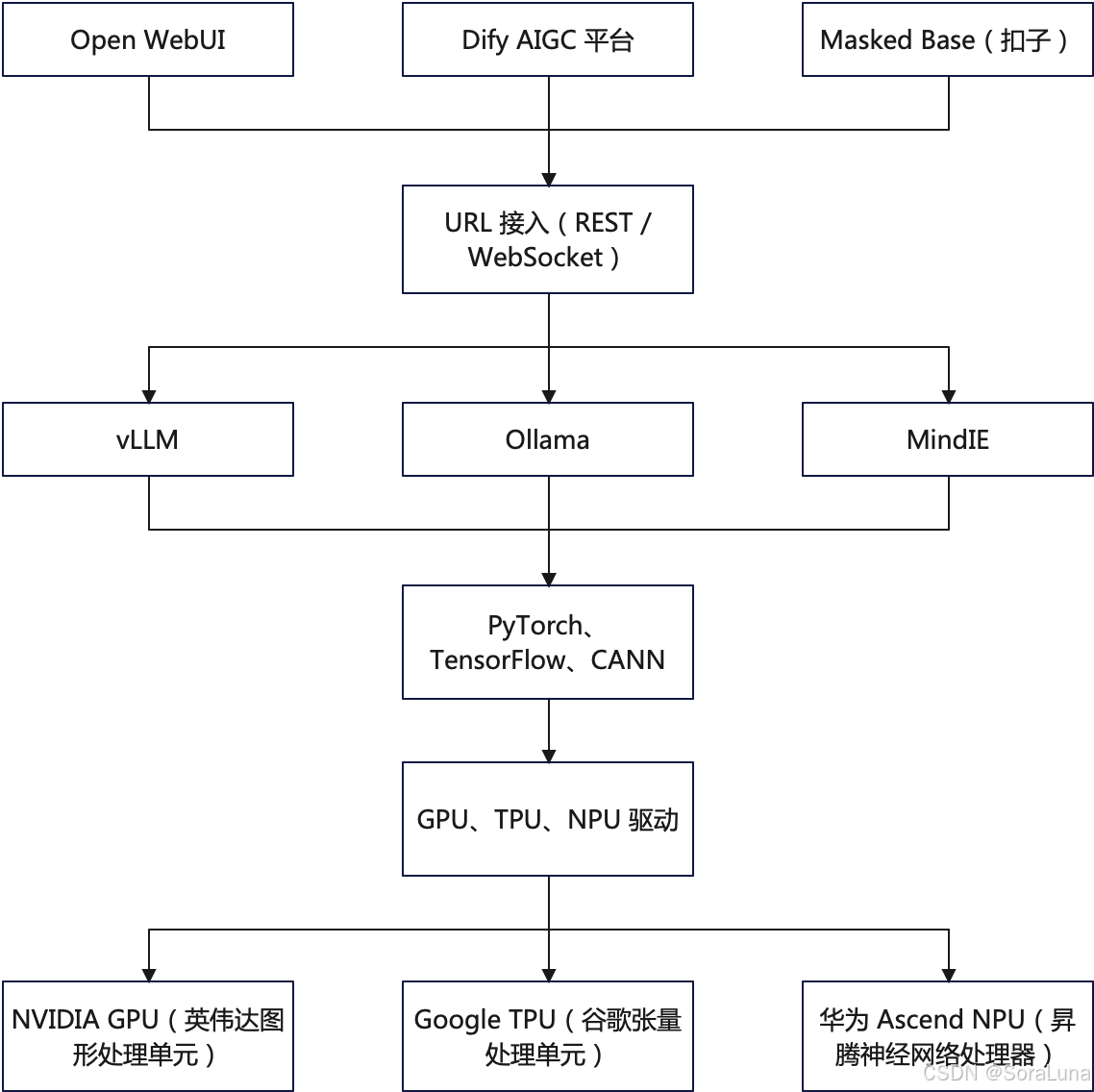
AIGC(AI Generated Content)系统由多个结构层级组成,自上而下涵盖交互界面、API 通信、模型推理、计算框架、底层驱动与硬件支持。本篇梳理 AIGC 应用的六层体系结构,明确各组件在系统中的职责与上下游关系,为后续部署与开发提供整体视角。
二、AIGC 系统六层结构
1. 展示层(交互层)
提供用户与模型交互的可视化界面,支持内容生成、问答对话与插件调用:
- Open WebUI:本地可部署的统一聊天界面,支持对接 vLLM 或 Ollama 模型,兼容 OpenAI 格式。
- Dify AIGC 平台:具备模型调用、工作流编排、知识库问答、插件扩展等功能。
- Masked Base(扣子):国产无代码智能体平台,适用于图形化构建复杂逻辑与流程交互。
2. API 接入层
实现前后端或多端之间的数据通信,统一模型调用接口协议:
- URL 接入(REST / WebSocket):采用标准化接口协议,适配前端页面、插件系统、自动化工具等多种访问方式。
3. 模型服务层
承载主力推理模型,负责处理输入、生成输出并返回:
- vLLM:高吞吐大语言模型推理引擎,兼容 OpenAI API 接口,适合多轮问答场景。
- Ollama:轻量本地推理平台,支持 llama、mistral、deepseek 等模型快速部署。
- MindIE:融合规则引擎与知识图谱的智能推理系统,支持增强问答、多源融合等复杂任务。
4. 计算框架层
支撑模型执行的基础平台,负责张量计算与资源调度:
- PyTorch:主流深度学习框架,支持研究开发与推理部署。
- TensorFlow:工业级部署方案,适用于大规模模型上线与分布式执行。
- CANN:华为昇腾平台的异构计算框架,支持 NPU 高效推理。
5. 驱动层
提供计算框架与物理硬件之间的接口,实现设备控制与指令转译:
- GPU 驱动(如 CUDA):为 PyTorch、TensorFlow 等框架提供加速计算支持。
- TPU 驱动:配合 Google 云 TPU 使用,适用于大规模训练与推理。
- NPU 驱动(如 Ascend Driver):支撑华为昇腾芯片的异构指令调度。
6. 硬件层
提供实际算力支撑,决定系统的并发性能与响应速度:
- NVIDIA GPU(英伟达图形处理单元):主流 AI 训练与推理平台。
- Google TPU(谷歌张量处理单元):优化大模型任务的定制芯片。
- 华为 Ascend NPU(昇腾神经网络处理器):面向边缘计算与企业部署场景。
三、结构示意图
四、数据流与交互路径简述
- 用户通过 Open WebUI、Dify 或扣子界面提出请求
- API 接入层解析请求并转发至后端模型服务
- 模型服务(如 vLLM、Ollama)完成推理并生成结果
- 结果返回前端界面展示,或进入后续插件流程(如图文生成、自动回复等)
五、总结与展望
本篇从系统架构视角,概括了 AIGC 应用的六大核心层级,涵盖从交互到硬件的全流程组件。这一分层结构为后续的实际部署、模型接入、插件调用与性能优化等任务提供了统一参考框架。接下来将在后续章节中逐步展开 vLLM 部署、Open WebUI 使用、Dify 场景实践等内容,逐层落地。