VLM-E2E:通过多模态驾驶员注意融合增强端到端自动驾驶——论文阅读
《VLM-E2E Enhancing End-to-End Autonomous Driving with Multimodal Driver Attention Fusion》2025年2月发表,来自香港科大广州分校、理想汽车和厦门大学的论文。
一、核心问题与动机
现有端到端(E2E)自动驾驶系统直接从传感器输入映射到控制信号,但缺乏对驾驶员注意力语义的显式建模,导致在复杂场景(如密集车流、路口交互)中决策能力受限。人类驾驶员通过动态关注关键信息(如交通信号灯、行人)进行决策,而现有系统难以模拟这种能力。论文提出利用视觉语言模型(VLMs)的高层次语义理解能力,将文本描述与鸟瞰图(BEV)特征融合,以增强自动驾驶系统的语义感知和决策能力。
二、核心贡献与创新 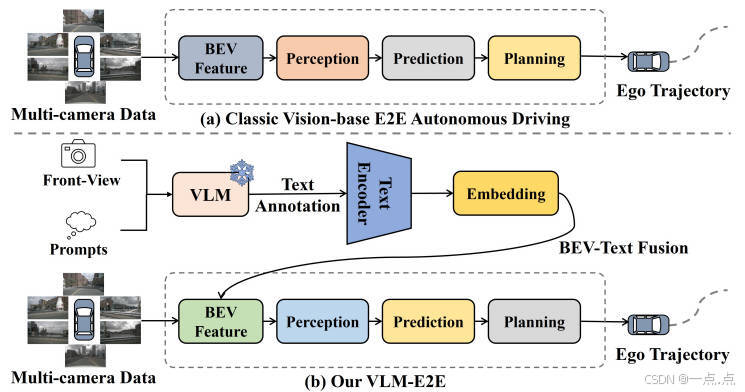
-
VLM-E2E框架
将VLMs与BEV模块直接集成,而非仅用于决策模块,实现几何特征(BEV)与语义特征(文本)的深度融合,增强场景理解的全面性。 -
BEV-Text可学习加权融合策略
通过动态调整BEV与文本特征的权重(公式4),根据任务需求自适应分配模态重要性(如车道保持优先BEV,红灯检测优先文本),解决多模态融合中的重要性不平衡问题。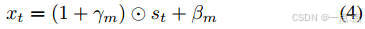
-
语义修正机制
针对VLM的幻觉问题(生成不准确描述),结合真值(GT)标签和高层机动意图(如转向、直行)修正文本描述,确保语义与驾驶任务对齐。 -
实验验证
在nuScenes数据集上,VLM-E2E在感知(IoU)、预测(PQ/RQ/SQ)和规划(L2距离、碰撞率)任务中均超越基线模型(如ST-P3),尤其在长期规划(3秒碰撞率降低至1.17%)表现突出。
三、方法详述
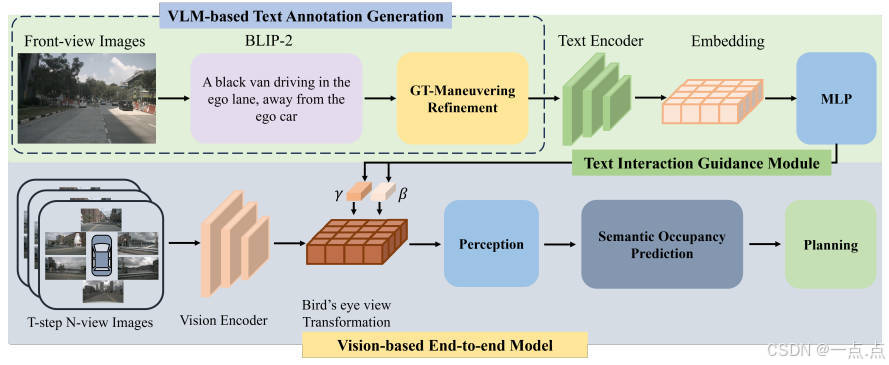
-
VLM-Based文本标注生成
-
输入:前端摄像头图像 + 任务提示(如“注意行人”)。
-
流程:
-
使用BLIP-2生成初步文本描述(公式1),提取关键语义(如“前方红灯”)。
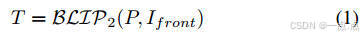
-
利用GT标签和机动意图修正描述,过滤无关信息(如广告牌)。
-
通过CLIP模型编码文本为特征向量(公式2),对齐BEV视觉特征。

-
-
-
BEV-Text动态融合
-
文本编码:CLIP模型生成低维文本特征(77维),计算缩放因子(γ)和偏置(β)(公式3)。
-
特征调制:对BEV特征进行加权调整(公式4),保留残差连接以稳定训练:
-
动态权重:模型根据场景需求自动分配模态权重(如复杂路口增强文本特征)。
-
-
时空BEV感知与预测
-
BEV构建:多摄像头图像通过EfficientNet-b4提取特征,结合深度估计投影到3D空间,聚合为BEV表示(公式5-7)。

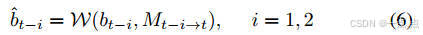
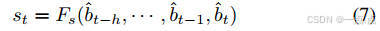
-
时序建模:对齐历史BEV帧(公式6),通过时空Transformer捕捉动态演化(公式7)。

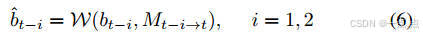
- 概率未来预测:使用条件变分框架(公式8-10)生成多模态轨迹,优化KL散度损失以覆盖可能未来。
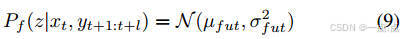
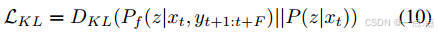
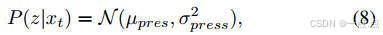
-
-
注意力引导规划
-
轨迹生成:基于BEV-Text融合特征生成候选轨迹,结合占用场和地图信息计算安全得分(公式11)。
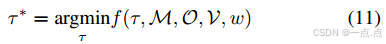
-
动态调整:利用前端摄像头特征(如交通信号灯)通过GRU网络迭代优化轨迹,确保符合交规。
-
四、实验与结果
-
感知任务
-
IoU提升:车辆检测(0.75%↑)、行人检测(24.4%↑),关键类别显著优化。
-
原因:文本语义增强对动态目标的关注(如遮挡行人)。
-
-
预测任务
-
PQ(全景质量):29.83(ST-P3为27.56),表明实例分割与语义分类更精准。
-
时序一致性:通过历史BEV对齐,减少动态目标误检。
-
-
规划任务
-
碰撞率:3秒碰撞率1.17%(基线为1.83%),长期安全性提升。
-
L2距离:3秒误差2.68(接近人类驾驶),轨迹更平滑自然。
-
五、局限性及未来方向
-
模态限制:当前仅融合视觉与文本,未来可扩展至激光雷达/雷达。
-
实时性:VLM推理可能增加延迟,需优化轻量化部署(如模型蒸馏)。
-
长尾场景:需进一步验证极端天气/罕见事件的泛化性。
六、总结
VLM-E2E通过语义-几何联合建模与动态多模态融合,显著提升自动驾驶系统在复杂场景下的感知与决策能力。其核心创新在于将VLMs的高层语义理解与BEV的几何感知结合,模拟人类驾驶员的注意力机制,为端到端自动驾驶提供更安全、可解释的解决方案。