计算机视觉——通过 OWL-ViT 实现开放词汇对象检测
介绍
传统的对象检测模型大多是封闭词汇类型,只能识别有限的固定类别。增加新的类别需要大量的注释数据。然而,现实世界中的物体类别几乎无穷无尽,这就需要能够检测未知类别的开放式词汇类型。对比学习(Contrastive Learning)使用成对的图像和语言数据,在这一挑战中备受关注。著名的模型包括 CLIP,但将其应用于物体检测,如在训练过程中处理未见类别,仍然是一个挑战。
本文使用标准视觉转换器(ViT)建立了一个开放词汇对象检测模型——开放世界定位视觉转换器(OWL-ViT),只做了极少的修改。该模型在大型图像-文本对的对比学习预训练和端到端检测的微调方面表现出色。特别是,使用类名嵌入可以实现对未学习类别的零检测。
OWL-ViT 在单次检测方面也很强大,因为它可以使用图像嵌入和文本作为查询。特别是在 COCO 数据集中,对于未经训练的类别,OWL-ViT 比以前的一流模型有了显著的性能提升。这一特性对于检测难以描述的对象(如特殊部件)非常有用。
我们还证明,增加预训练时间和模型大小能持续提高检测性能。特别是,我们发现,即使图像-文本对的数量超过 200 亿,开放词汇检测的性能改善仍在继续。此外,通过在检测微调中适当使用数据扩展和正则化,即使使用简单的训练配方,也能实现较高的零次和单次检测性能。
建议方法
OWL-ViT 是一个两阶段的学习过程,具体如下:
- 使用大型图像-文本对进行对比预训练。
- 将学习过渡到检测任务。
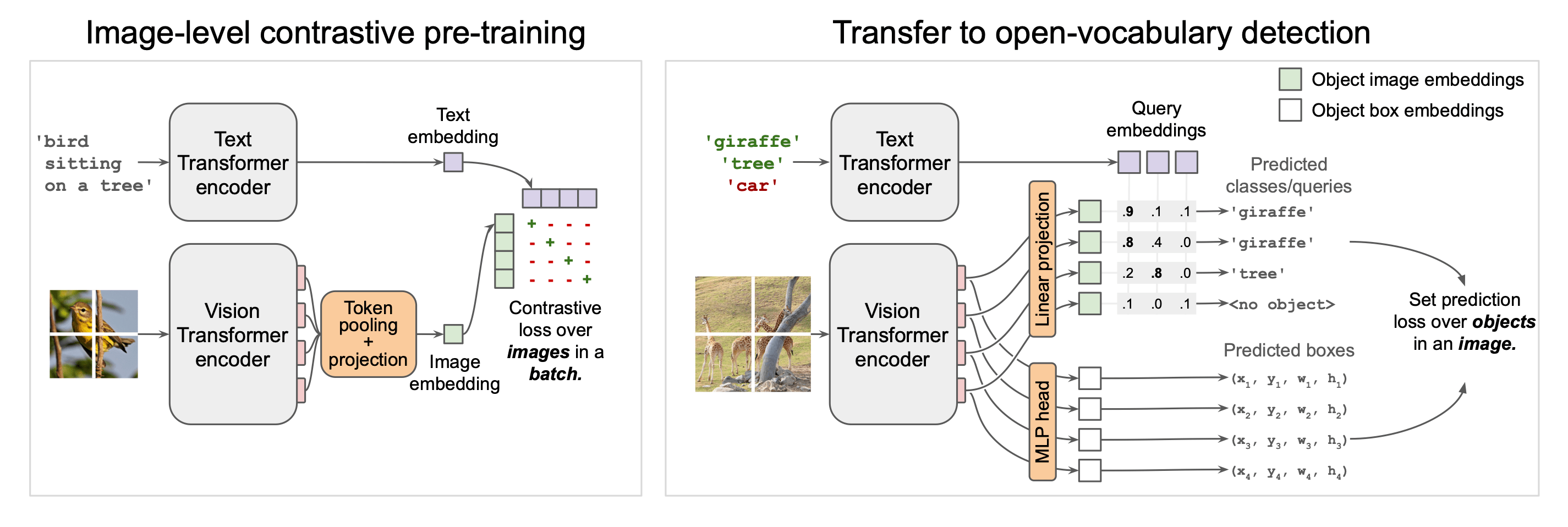
使用大型图像-文本对进行对比预训练
这样做的目的是将视觉和语言模式映射到一个统一的表示空间中。学习过程使用图像和文本编码器进行训练,以处理每种模态,使相关的图像和文本嵌入相互靠近,并使不相关的图像和文本嵌入相互远离。
图像编码器采用视觉变换器(ViT)架构,该架构具有可扩展性和强大的表示能力。图像被划分为多个片段,每个片段都作为一个标记进行处理,从而实现具有空间关系的特征提取。在这一过程中,ViT 标记化过程将图像转换成一串固定长度的标记,并通过变换器层学习各补丁之间的关系。另一方面,文本编码器处理标记化的句子,并生成浓缩整个句子含义的嵌入。文本表示通常是通过转换器最后一层的句末标记(EOS 标记)输出获得的。
OWL-ViT 预训练的一个重要设计特点是图像和文本编码器是独立的。这种设计允许预先计算查询文本和图像的嵌入,从而大大提高了推理过程中的计算效率。这种独立性还为在同一架构中处理查询(无论是文本还是图像)提供了灵活性。
将学习过渡到检测任务
在这里,首先去掉了 ViT 中最后的标记池层(通常用于提取整个图像的表示)。取而代之的是,将一个小型分类头和一个盒式回归头直接连接到每个输出标记。这种设计确保了 ViT 中的每个输出标记都与图像中的不同空间位置相对应,每个标记都代表一个潜在的候选对象。分类头预测物体类别,而方框回归头则估算相应边框的位置。
传统的对象检测模型在分类层中学习每个类别的固定权重,而 OWL-ViT 不使用固定的类别分类层。相反,对象类别名称被输入到文本编码器中,生成的文本嵌入直接用作分类头的权重。只要给出类名,即使是未经训练的类,这种方法也能让模型检测到相应的对象。
转换学习采用 DEtection TRansformer (DETR) 中使用的两端匹配损失来预测物体的位置。这种损失是模型预测的边框与正确边框之间的最佳映射,并计算每一对边框的损失。这样可以调整模型,使预测的物体位置和实际的物体位置保持一致。
在分类方面,焦点 sigmoid 交叉熵用于考虑长尾分布数据集的不平衡。与经常出现的类别相比,这种损失函数对罕见类别的误报惩罚更大,从而提高了罕见类别的检测性能。
此外,对于联合数据集,即并非所有图像都注释了所有类别,但每幅图像中只注释了有限数量的类别的数据集,对于每幅训练图像,查询是注释了的类别(正例明确标注为不存在的类别(负面示例)作为查询。这样,模型就能根据明确识别的信息进行学习,并减少对负面示例的错误处理。为了进一步避免对未注明类别的误解,我们在训练过程中随机选择类别并将其作为 “伪负例”,为每幅图像准备了至少 50 个负例查询。
试验
实验中使用了多个数据集。在训练中,我们主要使用 OpenImages V4(约 170 万张图像,600 多个类别)、Visual Genome(8.45 万张图像,包括大量对象关系信息)和 Objects365(包含 365 个类别的大型检测数据集)。一方面,评估使用了长尾分布。同时,评估主要使用了长尾分布的 LVIS v1.0,特别是用于验证零镜头性能。此外,COCO 2017 用于比较标准对象检测性能,Objects365 用于验证一般检测能力。
对开放词汇对象检测的评估主要集中在 LVIS 数据集上未经训练类的性能上。在该实验中,OWL-ViT 在零拍摄条件下的 APrare 达到了 31.2%,明显优于现有的先进方法。这表明,在预训练过程中使用图像-文本对能够从类名和描述中有效提取对象的语义特征。尤其是文本条件检测法,只需输入类别名称的文本查询,就能高精度地检测出未学习过的类别,这是该方法与以往方法的主要区别。
Hewshot 图像条件检测实验评估了 COCO 数据集上图像查询的检测性能;OWL-ViT 比现有的最先进方法提高了 72%,AP50 分数从 26.0 提高到 41.8。这些结果表明,OWL-ViT 综合利用了视觉和语言表征,即使对于没有给出名称的未知对象,也能提供出色的检测性能。特别是,图像条件检测通过使用包含特定对象的图像嵌入作为查询,有效地检测出了视觉上相似的对象。
对缩放特性的分析证实,增加预训练中使用的图像-文本对数量和模型大小可持续提高检测性能。特别是,在预训练中使用超过 200 亿个图像-文本对往往能显著提高零点检测性能。这一结果表明,在预训练中使用大规模数据也能有效地过渡到物体检测任务。同样明显的是,基于视觉转换器的模型比其他架构具有更好的扩展性能,尤其是在模型规模较大的情况下。
拓展与增强
背景知识
- 对比学习的重要性:对比学习通过将图像和文本对齐到一个共享的嵌入空间,使得模型能够理解视觉和语言之间的语义关系。这对于开放词汇对象检测至关重要,因为它允许模型通过文本描述来识别未见过的类别。
- 视觉转换器(ViT)的优势:ViT 将图像分割成固定大小的补丁,并将每个补丁视为一个标记,类似于自然语言处理中的单词。这种设计使得 ViT 能够捕捉图像中的全局特征和局部特征,从而在视觉任务中表现出色。
相关工作
- CLIP 模型:CLIP 是一个开创性的模型,它通过对比学习将图像和文本嵌入到一个共享的向量空间中。虽然 CLIP 主要用于图像分类和文本生成任务,但其思想为 OWL-ViT 提供了重要的启发。OWL-ViT 在此基础上进一步扩展,将对比学习应用于对象检测任务。
- DETR 模型:DETR 使用 Transformer 架构来处理对象检测任务,通过端到端的方式学习对象的位置和类别。OWL-ViT 借鉴了 DETR 的思想,使用两端匹配损失来优化检测性能。
实际应用场景
- 工业检测:在工业环境中,OWL-ViT 可以用于检测生产线上的缺陷或异常部件。通过提供图像查询或类别名称,模型能够快速定位并识别问题,从而提高生产效率和质量控制。
- 自动驾驶:在自动驾驶场景中,OWL-ViT 可以帮助车辆识别道路上的未知障碍物或交通标志。通过实时检测和识别,车辆可以做出更安全的决策。
- 医疗影像分析:在医疗领域,OWL-ViT 可以用于分析医学影像,如 X 光或 CT 扫描。通过提供疾病名称或图像示例,模型能够帮助医生快速定位病变区域,辅助诊断。
行业影响
- 推动开放词汇检测的发展:OWL-ViT 的出现为开放词汇对象检测领域带来了新的突破。它证明了通过对比学习和 Transformer 架构,可以有效地识别未见过的类别,为未来的研究提供了新的方向。
- 促进多模态学习的发展:OWL-ViT 结合了图像和文本两种模态,展示了多模态学习的强大潜力。这种结合不仅提高了检测性能,还为其他领域(如自然语言处理和计算机视觉的交叉领域)提供了新的思路。
总结
利用视觉转换器进行简单的开放词汇对象检测(OWL-ViT)是一项开创性的研究。这项研究的最大贡献在于,它利用图像和文本的大规模对比预训练,实现了对未知类别的零次和一次对象检测,而且准确率很高。特别是直接使用预训练的文本编码器输出作为类嵌入,而不是使用固定的类分类层的设计,在灵活性和可扩展性方面取得了重大进展。