3分钟快速本地部署deepseek
DeepSeek简介
DeepSeek 是杭州深度求索人工智能基础技术研究有限公司开发的一系列大语言模型,背后是知名量化资管巨头幻方量化3。它专注于开发先进的大语言模型和相关技术,拥有多个版本的模型,如 DeepSeek-LLM、DeepSeek-V2、DeepSeek-V3 等,以 Transformer 架构为基础,具有训练成本低、性能表现好等特点,可实现语义分析、计算推理、问答对话、篇章生成、代码编写等功能,在政务、应急管理、医疗等多个领域都有广泛应用,且具有国产化、开源、免费、多语言支持等优势,还支持联网搜索、文件解析和深度思考模式
引言
本篇文章利用Ollama快速本地部署deepseek,避免deepseek服务器无法访问带来的功能影响
实战
Ollama 是 Meta 开发的一款开源的大语言模型推理框架,同时也提供了运行部署环境。这个平台上,有各种开源的AI大模型,都是免费下载使用的。支持Mac、Linux、Windows的运行环境。 官方网址:
ollama官网
下载完成后打开自动弹出命令行

命令行输入
ollama help
 如果没有报错就说明安装成功。 然后,去ollama官方网站找到 DeepSeek r1模型的信息页
如果没有报错就说明安装成功。 然后,去ollama官方网站找到 DeepSeek r1模型的信息页
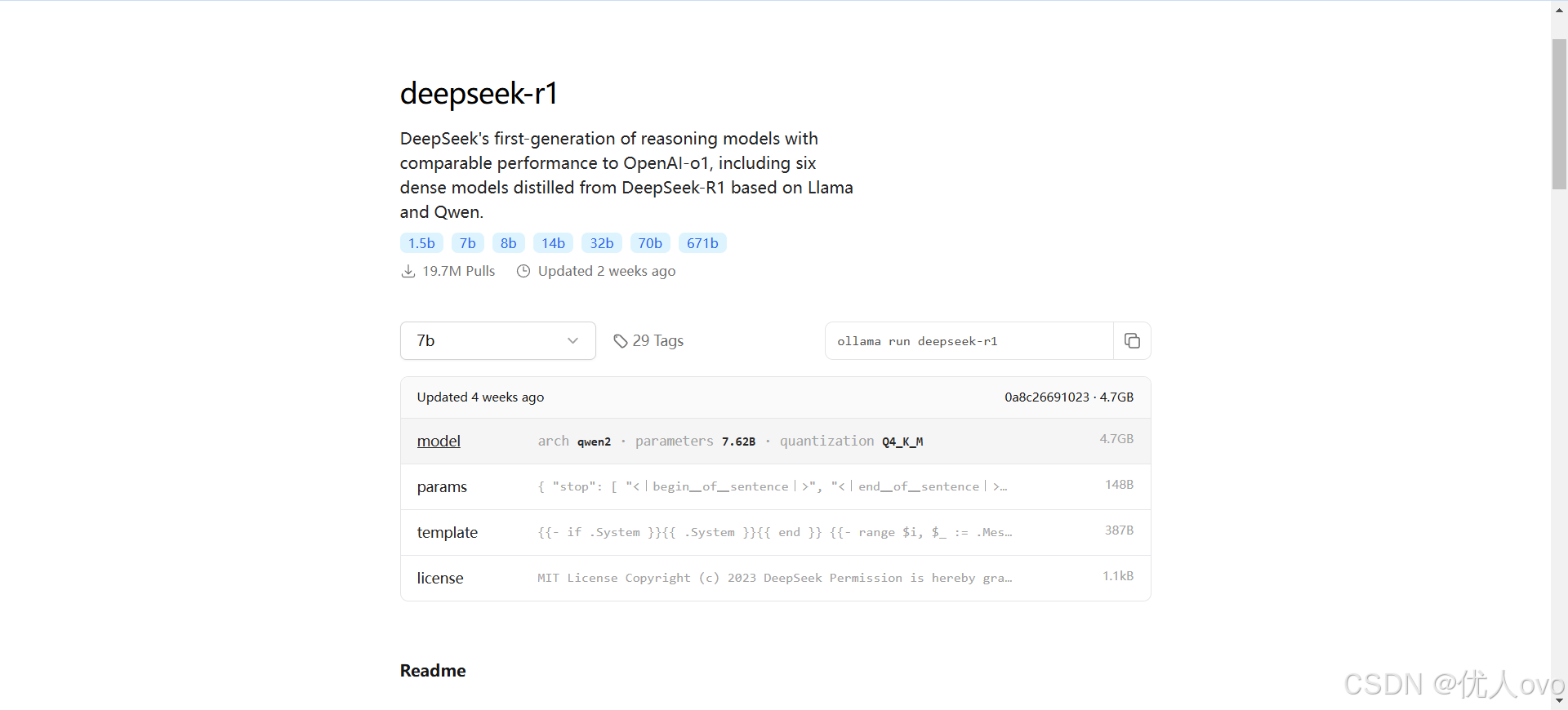
这里可以选择参数
大模型中的数字(如1.5B、7B、8B、14B、32B、70B、671B)表示模型的参数量,单位是“十亿”(Billion)。参数量越大,模型通常越复杂,性能可能越高,但也需要更多的计算资源。以下是这些模型参数量及其适合的硬件环境的简要说明:
-
1.5B(15亿参数):
- 硬件要求: 可以在单一高端GPU(如NVIDIA RTX 3090)或高性能CPU上运行,对于推理任务尤其如此。训练可能需要较长时间,但对于小规模实验或个人开发者来说可行。
- 适合场景: 适用于单人或小团队的实验性项目或初步研究。
-
7B(70亿参数):
- 硬件要求: 可以在一台高性能的单GPU(如NVIDIA RTX 3090或A100)上运行。对于推理任务,CPU也可以勉强运行,但速度较慢。
- 适合场景: 适用于个人开发者、研究者进行小规模实验或部署在边缘设备上。
-
8B(80亿参数):
- 硬件要求: 与7B类似,单GPU如RTX 3090或A100可以处理,但对于更快的训练和推理,可能需要更强的GPU或多GPU设置。
- 适合场景: 类似于7B,但由于参数略多,可能在某些任务上性能略有提升。
-
14B(140亿参数):
- 硬件要求: 需要至少一两个高性能GPU(如A100),或者多GPU环境(如多卡NVLink配置)。对于推理,一个好的GPU也可以,但训练需要更强的资源。
- 适合场景: 适用于中等规模的企业或研究机构进行较为复杂的自然语言处理任务。
-
32B(320亿参数):
- 硬件要求: 通常需要多GPU环境(如4个或更多A100),或者强大的云计算资源。推理可以在一台高端GPU上进行,但速度较慢。
- 适合场景: 适合需要更高精度的任务,适用于大型企业或研究机构。
-
70B(700亿参数):
- 硬件要求: 需要大规模的GPU集群(如8个或更多A100),或者非常强大的云计算资源。推理也需要多GPU支持。
- 适合场景: 用于最前沿的研究或需要极高性能的生产环境。
-
671B(6710亿参数):
-
硬件要求: 这几乎是超大规模模型的范畴,需要极其强大的计算资源,如超级计算机或大型分布式GPU集群。即使是推理,资源消耗也非常高。
-
适合场景: 主要用于大规模的科学研究或企业级应用,其中模型的规模和精度是最重要的。
-
总结:
-
小规模模型(1.5B、7B、8B)适用于个人或小团队的开发和测试,硬件要求相对较低。
-
中等规模模型(14B、32B)需要更加专业的硬件,适合中型到大型团队使用。
-
大规模模型(70B、671B)则需要大规模的计算资源,通常是大型企业或研究机构才能承担的。
推荐1.5b或者7b 可以自己尝试

然后复制右边的命令行语句

这样显示就开始下载部署了
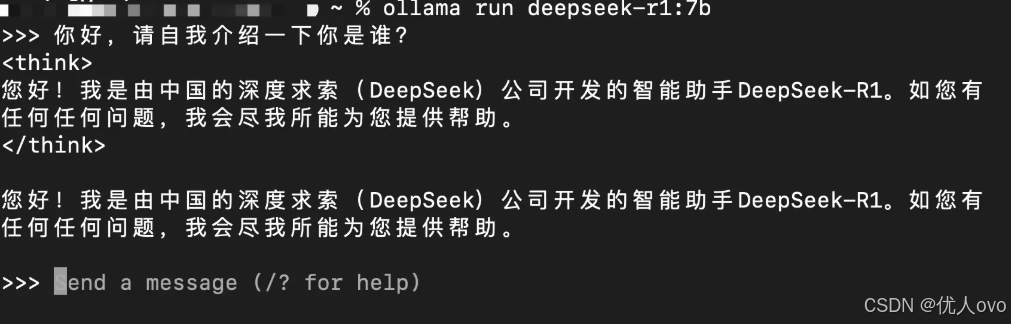
等待安装完后,出现了“end a message”字样,说明已经成功安装,接下来,输入一段文字,试一试: