PyTorch入门------卷积神经网络
前言
参考:神经网络 — PyTorch Tutorials 2.6.0+cu124 文档 - PyTorch 深度学习库
一个典型的神经网络训练过程如下:
-
定义一个包含可学习参数(或权重)的神经网络
-
遍历输入数据集
-
将输入通过神经网络处理
-
计算损失(即输出结果与正确答案之间的差距)
-
将梯度反向传播到网络的参数中
-
更新网络的权重,通常使用一个简单的更新规则:weight = weight - learning_rate * gradient
1.相关概念
感受野: 在卷积神经网络中,对于某一层的任意元素x,其感受野(receptive field)是指在前向传播期间可能影响 x 计算的所有元素(来自所有先前层)。
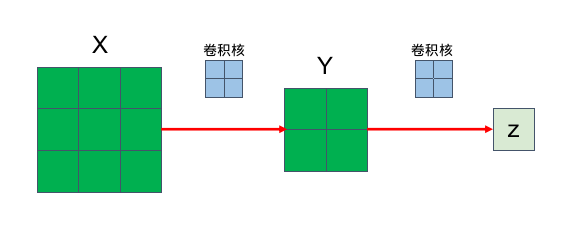
注意:感受野可能大于输入的实际大小。例如在如上所示的卷积结构,X 上 z 的感受野为其全部 9 个元素,Y 上 z 的感受野也为其全部 4 个元素,即 z 的感受野的大小为 9+4=13! 因此,当一个特征图中的任意元素需要检测更广区域的输入特征时,我们可以构建一个更深的网络。
2.多输入多输出通道
参考:https://zhuanlan.zhihu.com/p/251068800
- 输入通道个数 等于 卷积核通道个数
- 卷积核个数 等于 输出通道个数
2.1 多输入通道
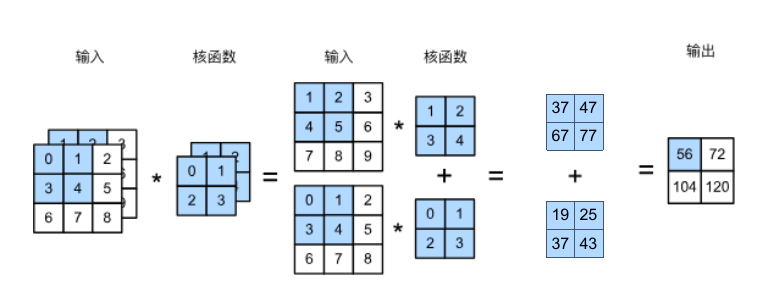
输入通道个数 等于 卷积核通道个数!
当输入包含多个通道时,需要构造一个与输入数据具有相同输入通道数的卷积核,以便与输入数据进行互相关运算。
由于输入和卷积核都有 个通道,我们可以对每个通道输入的二维张量和卷积核的二维张量进行互相关运算,再对通道求和(将
的结果相加)得到二维张量。这是多通道输入和多输入通道卷积核之间进行二维互相关运算的结果。
2.2 多输出通道
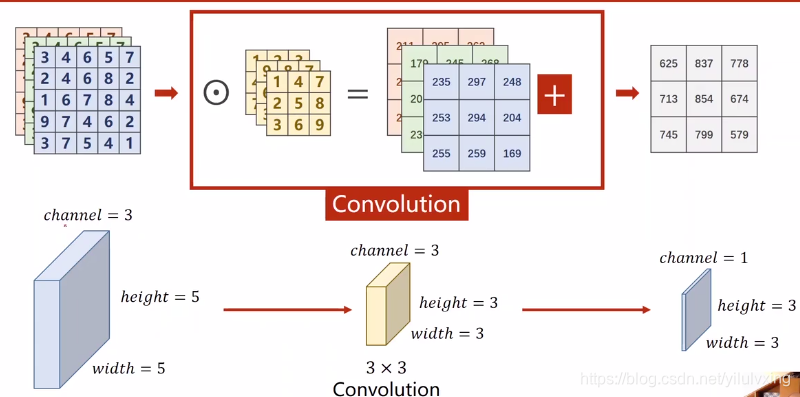
卷积核个数 等于 输出通道个数!
用 和
分别表示输入和输出通道的数目,并让
和
为卷积核的高度和宽度。为了获得多个通道的输出,我们可以为每个输出通道创建一个形状为
的卷积核张量,这样卷积核的形状是
(即
个卷积核,每个卷积核的形状为
)。
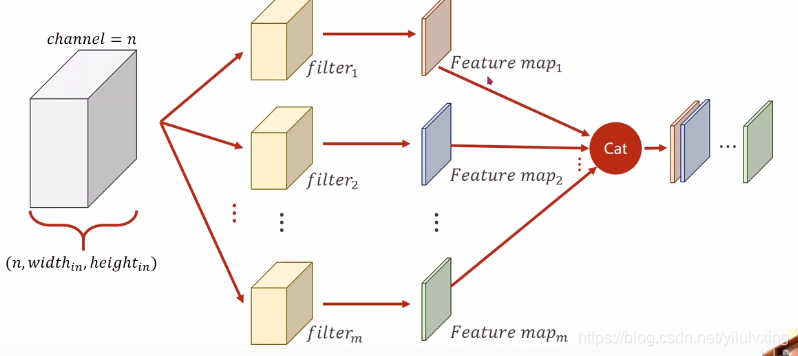
在互相关运算中,每个输出通道先获取所有输入通道,再以对应该输出通道的卷积核计算出结果。最后将每个卷积核对应的输出通道结果(feature map)进行拼接得到多通道输出。
3. 1x1 卷积层
卷积(Convolution)的本质正是通过局部的加权和运算,提取图像中相邻像素之间的相关特征。
但 1x1 卷积并没此作用,1×1卷积的唯一计算发生在通道上!
- 当以每像素为基础应用时,1×1卷积层相当于全连接层。
- 1×1卷积层通常用于调整网络层的通道数量和控制模型复杂性。
下图展示了使用 1×1卷积核与3个输入通道和2个输出通道的互相关计算。 这里输入和输出具有相同的高度和宽度,输出中的每个元素都是从输入图像中同一位置的元素的线性组合。 我们可以将1×1卷积层看作在每个像素位置应用的全连接层,将 个输入值转换为
个输出值。 因为这仍然是一个卷积层,所以跨像素的权重是一致的。 同时,1×1卷积层需要的权重维度为
,再额外加上一个偏置。

4. 池化层
- 池化层通过减少特征图的空间分辨率来降低计算量,并降低卷积层对空间分辨率的敏感性。
- 池化层可以降低隐藏表示的空间分辨率,从而聚集更多的高层次特征信息 (将局部的低级特征逐步整合成更高级的抽象特征) 。
- 池化操作(如最大池化)会在局部区域内提取最显著的特征,从而降低卷积层对位置的敏感性。
- 池化层的输出通道数通常与输入通道数相同,因为池化是独立作用于每个通道的。
5. 总结
增加每个神经元感受野的方式:
- 增加卷积层的层数,构建更深的网络。
- 添加池化层,降低分辨率,聚合信息。随着分辨率的降低,每个神经元所覆盖的区域也会增大,即感受野增大。
一、网络结构
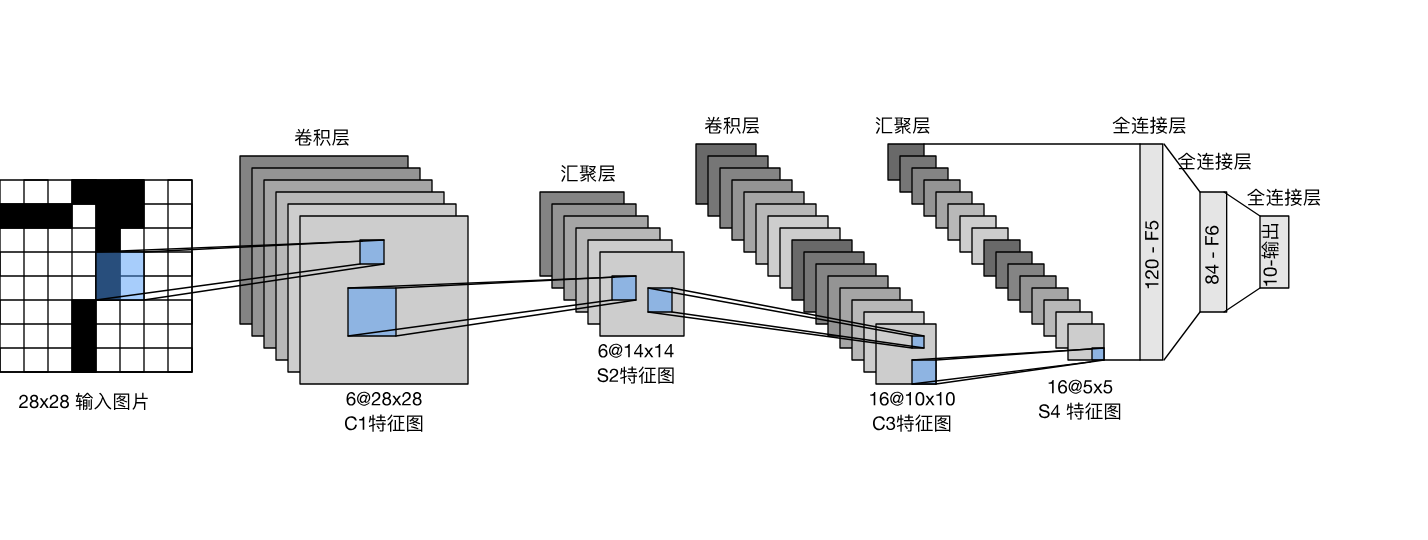
一个对数字图像进行分类的网络的结构如下:
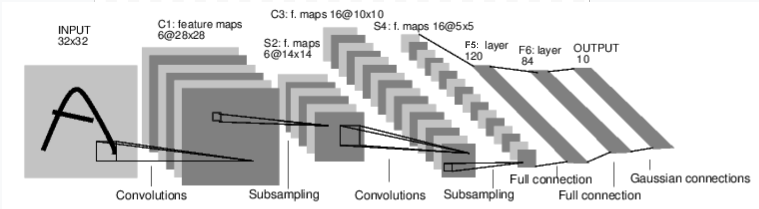
该网络结构和 LeNet(LeNet-5)的网络结构基本一致。(对原始模型做了一点小改动,去掉了最后一层的高斯激活。除此之外,这个网络与最初的LeNet-5一致。)
这是一个简单的前馈神经网络(RNN)。它接收输入,将其依次传递通过多个层,最终输出结果。
在使用 pytorch 定义该网络结构时,只需要定前向传播 forward 函数,而反向传播 backward 函数(用于计算梯度)会通过 autograd 自动生成。在 forward 函数中,可以使用任意的张量操作(Tensor operations)模型中所有的可学习参数可以通过 net.parameters() 返回。
#----- 1.定义网络结构 -----#
import torch
import torch.nn as nn
import torch.nn.functional as Fclass Net(nn.Module):"""Conv2d(): 初始化一个二维卷积层。参数:in_channels (int) -- 输入图像中的通道数out_channels (int) -- 卷积产生的通道数kernel_size (int 或 tuple) -- 卷积核的大小,可以是一个整数或包含两个整数的元组 (height, width)stride (int 或 tuple, 可选) -- 卷积的步长,默认值为 1。如果是元组, 则分别表示高和宽方向上的步长。padding (int, tuple 或 str, 可选) -- 输入的所有四个边的填充。默认值为 0, 可以是整数、元组或字符串('valid' 或 'same'),'valid' 表示不填充,'same' 表示填充以保持输出尺寸与输入相同。dilation (int 或 tuple, 可选) -- 卷积核元素之间的间距,默认为 1, 表示常规卷积。增大该值会引入空洞卷积。groups (int, 可选) -- 控制卷积的分组,默认为 1。大于 1 时会做分组卷积,即输入和输出通道被分为多个组,每组独立卷积。bias (bool, 可选) -- 是否添加偏置项,默认为 True。如果设置为 False, 则没有偏置。padding_mode (str, 可选) -- 填充模式,'zeros' 表示填充 0, 默认值为 'zeros'。可以选择 'reflect' 或 'replicate' 进行反射或复制填充。device (torch.device, 可选) -- 卷积层所使用的设备,默认为 None。dtype (torch.dtype, 可选) -- 卷积层所使用的数据类型,默认为 None。返回:nn.Conv2d -- 一个二维卷积层对象"""def __init__(self):super(Net, self).__init__()# 1 个输入图像通道,6 个输出通道,5x5 的卷积核self.conv1 = nn.Conv2d(1, 6, 5) # bias=False# 6 个输入图像通道,16 个输出通道,5x5 的卷积核self.conv2 = nn.Conv2d(6, 16, 5) # bias=False# 一个仿射变换操作:y = Wx + bself.fc1 = nn.Linear(16 * 5 * 5, 120) # 5*5 来源于图像尺寸self.fc2 = nn.Linear(120, 84)self.fc3 = nn.Linear(84, 10)def forward(self, input):# 卷积层 C1:1 个输入图像通道,6 个输出通道,5x5 的卷积核,使用 ReLU 激活函数,# 输出尺寸为 (N, 6, 28, 28) 的张量,N 是批次大小c1 = F.relu(self.conv1(input))# 池化层 S2:2x2 的最大池化网格,纯函数实现,没有可训练参数,# 输出尺寸为 (N, 6, 14, 14) 的张量s2 = F.max_pool2d(c1, (2, 2))# 卷积层 C3:6 个输入通道,16 个输出通道,5x5 的卷积核,使用 ReLU 激活函数,# 输出尺寸为 (N, 16, 10, 10) 的张量c3 = F.relu(self.conv2(s2))# 池化层 S4:2x2 的最大池化网格,纯函数实现,没有可训练参数,# 输出尺寸为 (N, 16, 5, 5) 的张量s4 = F.max_pool2d(c3, 2)# 展平操作:纯函数实现,输出尺寸为 (N, 400) 的张量s4 = torch.flatten(s4, 1)# 全连接层 F5:输入为 (N, 400) 的张量,# 输出为 (N, 120) 的张量,使用 ReLU 激活函数f5 = F.relu(self.fc1(s4))# 全连接层 F6:输入为 (N, 120) 的张量,# 输出为 (N, 84) 的张量,使用 ReLU 激活函数f6 = F.relu(self.fc2(f5))# 高斯输出层:输入为 (N, 84) 的张量,# 输出为 (N, 10) 的张量output = self.fc3(f6)return outputnet = Net()
print(net)# 模型的可学习参数
params = list(net.parameters())
print(len(params)) # (卷积层数量 + 全连接层数量) * 2。2 为权重和偏置,卷积层和全连接层均有权重和偏置
print(params[0].size()) # 卷积层 conv1 的权重矩阵的形状,格式为 [输出通道数, 输入通道数, 卷积核高度, 卷积核宽度]
print(params[2].size())# 随机的 32x32 输入。格式为 (batch_size, Channel, Height, Width)
input = torch.randn(1, 1, 32, 32)
out = net(input)
print(out)# 梯度清零后进行反向传播
net.zero_grad()
out.backward(torch.randn(1, 10))二、损失函数
#----- 2.损失函数 -----#
output = net(input)
target = torch.randn(10) # a dummy target, for example
target = target.view(1, -1) # make it the same shape as output
criterion = nn.MSELoss()loss = criterion(output, target)
print(loss)print(loss.grad_fn) # MSELoss
print(loss.grad_fn.next_functions[0][0]) # Linear
print(loss.grad_fn.next_functions[0][0].next_functions[0][0]) # ReLU三、反向传播
#----- 3.反向传播 -----#
net.zero_grad() # 将所有参数的梯度缓冲区置零print('conv1.bias.grad before backward')
print(net.conv1.bias.grad)loss.backward()print('conv1.bias.grad after backward')
print(net.conv1.bias.grad)四、更新权重
#----- 4.更新模型权重 -----#
import torch.optim as optim# 创建优化器
optimizer = optim.SGD(net.parameters(), lr=0.01)# 在训练循环中:
optimizer.zero_grad() # 将梯度缓冲区清零
output = net(input) # 前向传播
loss = criterion(output, target) # 计算损失值
loss.backward() # 反向传播,计算梯度
optimizer.step() # 更新参数