第24周:Resnet结合DenseNet
目录
前言
一、 前期准备
1. 设置GPU
2.查看数据
二、构建模型
1.划分数据集
2.划分标签
3.编译及训练模型
三、结果可视化
四、总结
前言
- 🍨 本文为🔗365天深度学习训练营中的学习记录博客
- 🍖 原作者:K同学啊
一、 前期准备
1. 设置GPU
import os,PIL,pathlib,warnings
warnings.filterwarnings("ignore")
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device2.查看数据
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False import os,PIL,pathlib
data_dir="data/第8天/bird_photos"
data_dir=pathlib.Path(data_dir)image_count = len(list(data_dir.glob('*/*')))
print("图片总数为:",image_count)二、构建模型
1.划分数据集
batch_size = 8
img_height = 224
img_width = 224import torchvision.transforms as transforms
import torchvision.datasets as datasets
transforms=transforms.Compose([transforms.Resize([224,224]),transforms.ToTensor(),# transforms.Normalize(# mean=[0.482,0.456,0.406],# std=[0.229,0.224,0.225]# )
])
total_data=datasets.ImageFolder("data/第8天/bird_photos",transform=transforms)
total_datatotal_data.class_to_idxtrain_size=int(0.8*len(total_data))
test_size=len(total_data)-train_size
train_data,test_data=torch.utils.data.random_split(total_data,[train_size,test_size])
train_data,test_databatch_size=8
train_dl=torch.utils.data.DataLoader(train_data,batch_size,shuffle=True,num_workers=1)
test_dl=torch.utils.data.DataLoader(test_data,batch_size,shuffle=True,num_workers=1)for X,y in train_dl:print(X.shape)print(y.shape)break2.划分标签
total_data.class_to_idx3.编译及训练模型
def train(dataloader,model,loss_fn,optimizer):size=len(dataloader.dataset)num_batches=len(dataloader)train_loss,train_acc=0,0for X,y in dataloader:X,y =X.to(device),y.to(device)pred=model(X)loss=loss_fn(pred,y)#反向传播optimizer.zero_grad()loss.backward()optimizer.step()train_loss+=loss.item()train_acc+=(pred.argmax(1)==y).type(torch.float).sum().item()train_acc/=sizetrain_loss/=num_batchesreturn train_acc,train_loss
def test(dataloader,model,loss_fn):size=len(dataloader.dataset)num_batches=len(dataloader)test_loss,test_acc=0,0with torch.no_grad():for imgs,target in dataloader:imgs,target=imgs.to(device),target.to(device)target_pred=model(imgs)loss=loss_fn(target_pred,target)test_loss+=loss.item()test_acc+=(target_pred.argmax(1)==target).type(torch.float).sum().item()test_acc/=sizetest_loss/=num_batchesreturn test_acc,test_lossimport copy
optimizer = torch.optim.Adam(model.parameters(), lr= 1e-4)
loss_fn = nn.CrossEntropyLoss()import copy
import torch# Loss function and other initializations
loss_fn = nn.CrossEntropyLoss()
epochs = 20
train_loss = []
train_acc = []
test_loss = []
test_acc = []
best_acc = 0
best_loss = float('inf') # 初始化最优损失为正无穷
patience = 5 # 设置耐心值,即连续5轮损失不下降时停止训练
patience_counter = 0 # 用于记录损失不下降的轮数# Training and testing loop
for epoch in range(epochs):model.train()epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, optimizer)model.eval()epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)# Check if test loss improvedif epoch_test_loss < best_loss:best_loss = epoch_test_lossbest_model = copy.deepcopy(model)patience_counter = 0 # 重置耐心计数器else:patience_counter += 1 # 增加耐心计数器# If patience is exceeded, stop trainingif patience_counter >= patience:print(f"Stopping early at epoch {epoch+1} due to no improvement in test loss for {patience} epochs.")breaktrain_acc.append(epoch_train_acc)train_loss.append(epoch_train_loss)test_acc.append(epoch_test_acc)test_loss.append(epoch_test_loss)# Print the results for the current epochlr = optimizer.state_dict()['param_groups'][0]['lr']template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%, Test_loss:{:.3f}, Lr:{:.2E}')print(template.format(epoch + 1, epoch_train_acc * 100, epoch_train_loss, epoch_test_acc * 100, epoch_test_loss, lr))# Save the best model
PATH = './best_model.pth'
torch.save(best_model.state_dict(), PATH)
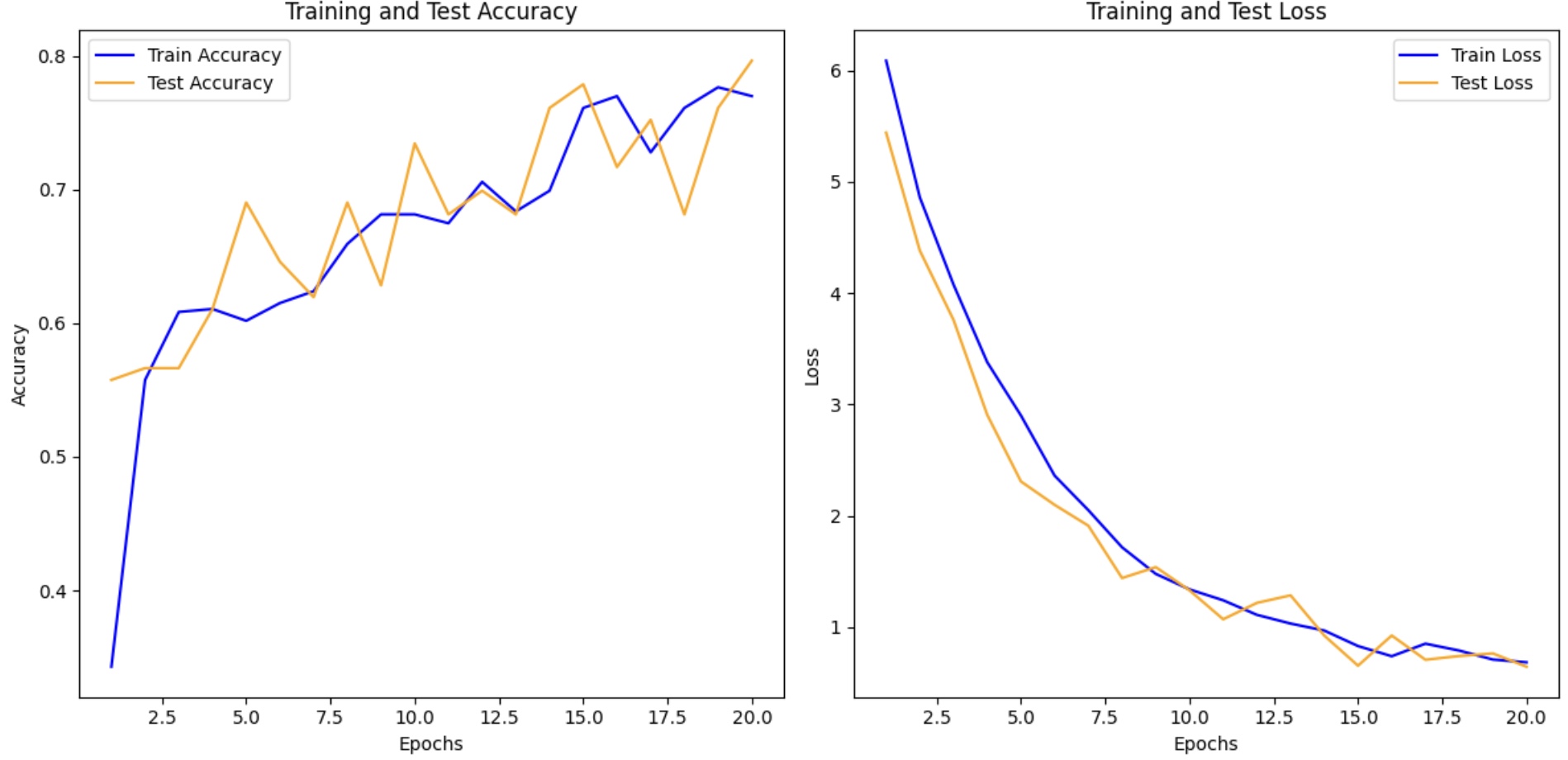
print('Finished Training')三、结果可视化
import matplotlib.pyplot as plt
import warnings
epochs = len(train_acc)# 绘制准确率
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.plot(range(1, epochs + 1), train_acc, label='Train Accuracy', color='blue')
plt.plot(range(1, epochs + 1), test_acc, label='Test Accuracy', color='orange')
plt.title('Training and Test Accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(loc='best')# 绘制损失
plt.subplot(1, 2, 2)
plt.plot(range(1, epochs + 1), train_loss, label='Train Loss', color='blue')
plt.plot(range(1, epochs + 1), test_loss, label='Test Loss', color='orange')
plt.title('Training and Test Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend(loc='best')# 显示图形
plt.tight_layout()
plt.show()Epoch: 1, Train_acc:34.3%, Train_loss:6.088, Test_acc:55.8%, Test_loss:5.442, Lr:1.00E-04 Epoch: 2, Train_acc:55.8%, Train_loss:4.859, Test_acc:56.6%, Test_loss:4.382, Lr:1.00E-04 Epoch: 3, Train_acc:60.8%, Train_loss:4.076, Test_acc:56.6%, Test_loss:3.759, Lr:1.00E-04 Epoch: 4, Train_acc:61.1%, Train_loss:3.380, Test_acc:61.1%, Test_loss:2.907, Lr:1.00E-04 Epoch: 5, Train_acc:60.2%, Train_loss:2.901, Test_acc:69.0%, Test_loss:2.309, Lr:1.00E-04 Epoch: 6, Train_acc:61.5%, Train_loss:2.361, Test_acc:64.6%, Test_loss:2.099, Lr:1.00E-04 Epoch: 7, Train_acc:62.4%, Train_loss:2.051, Test_acc:61.9%, Test_loss:1.911, Lr:1.00E-04 Epoch: 8, Train_acc:65.9%, Train_loss:1.718, Test_acc:69.0%, Test_loss:1.442, Lr:1.00E-04 Epoch: 9, Train_acc:68.1%, Train_loss:1.479, Test_acc:62.8%, Test_loss:1.540, Lr:1.00E-04 Epoch:10, Train_acc:68.1%, Train_loss:1.340, Test_acc:73.5%, Test_loss:1.332, Lr:1.00E-04 Epoch:11, Train_acc:67.5%, Train_loss:1.242, Test_acc:68.1%, Test_loss:1.071, Lr:1.00E-04 Epoch:12, Train_acc:70.6%, Train_loss:1.111, Test_acc:69.9%, Test_loss:1.219, Lr:1.00E-04 Epoch:13, Train_acc:68.4%, Train_loss:1.033, Test_acc:68.1%, Test_loss:1.286, Lr:1.00E-04 Epoch:14, Train_acc:69.9%, Train_loss:0.970, Test_acc:76.1%, Test_loss:0.925, Lr:1.00E-04 Epoch:15, Train_acc:76.1%, Train_loss:0.831, Test_acc:77.9%, Test_loss:0.654, Lr:1.00E-04 Epoch:16, Train_acc:77.0%, Train_loss:0.740, Test_acc:71.7%, Test_loss:0.926, Lr:1.00E-04 Epoch:17, Train_acc:72.8%, Train_loss:0.852, Test_acc:75.2%, Test_loss:0.708, Lr:1.00E-04 Epoch:18, Train_acc:76.1%, Train_loss:0.790, Test_acc:68.1%, Test_loss:0.741, Lr:1.00E-04 Epoch:19, Train_acc:77.7%, Train_loss:0.710, Test_acc:76.1%, Test_loss:0.765, Lr:1.00E-04 Epoch:20, Train_acc:77.0%, Train_loss:0.685, Test_acc:79.6%, Test_loss:0.645, Lr:1.00E-04 Finished Training
四、总结
模型的核心是一个结合 ResNet 和 DenseNet 的混合网络:
ResNet 残差块:通过残差连接解决了梯度消失问题,使得网络可以训练得更深。
DenseNet 密集块:通过密集连接实现了特征重用,提高了参数效率。
混合模型:先通过一个 ResNet 残差块 提取特征,然后通过一个 DenseNet 密集块 进一步提取和重用特征,最后通过全局平均池化和全连接层进行分类。