剑指offer经典题目(五)
目录
栈相关
二叉树相关
栈相关
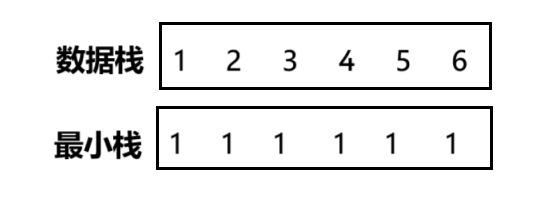
题目一:定义栈的数据结构,请在该类型中实现一个能够得到栈中所含最小元素的 min 函数,输入操作时保证 pop、top 和 min 函数操作时,栈中一定有元素。OJ地址
图示如下。

主要思想:我们可以采用两个栈结构,一个栈结构用于存放所有的数据,一个栈结构用于存放所有数据中最小的数据。 当最小栈都为空时,往数据栈中 push 的元素也要往最小栈中 push 数据,当最小栈不为空时,往数据栈中 push 元素时,要将往数据栈中 push 的元素与最小栈的栈顶元素进行对比,如果最小栈的栈顶的元素比往数据栈中 push 的元素小,那么就往最小栈中再次 push 最小栈的栈顶的元素,如果最小栈的栈顶的元素比往数据栈中 push 的元素大,那么此时也要将往数据栈中 push 的元素 push 到最小栈,这样就能保证最小栈的栈顶元素一定是数据栈的所有元素中最小的元素,同时需要注意,当数据栈 pop 元素时,也要让最小栈 pop 元素,这样就能保证最小栈的栈顶最小元素一定是在数据栈中出现的。注意:数据栈和最小栈的元素的个数时时刻刻要保证相同,否则就会出错。
编码如下。
class Solution {
public:stack<int> data_stack;stack<int> min_stack;void push(int value) {if(data_stack.empty()&&min_stack.empty()){data_stack.push(value);min_stack.push(value);}if(value>min_stack.top()){data_stack.push(value);min_stack.push(min_stack.top());}else{data_stack.push(value);min_stack.push(value);}}void pop() {data_stack.pop();min_stack.pop();}int top() {return data_stack.top();}int min() {return min_stack.top();}
};题目二:输入两个整数序列,第一个序列表示栈的压入顺序,请判断第二个序列是否可能为该栈的弹出顺序。假设压入栈的所 有数字均不相等。例如序列1,2,3,4,5是某栈的压入顺序,序列4,5,3,2,1是该压栈序列对应的一个弹出序列,但 4,3,5,1,2就不可能是该压栈序列的弹出序列。(注意:这两个序列的长度是相等的)。
图示如下。

主要思想: 栈的特点是先进后出,所以出栈序列的第一个元素一定是最后一个入栈的,这就是这个题目的关键点。根据出栈序列的第一个元素,将这个元素之前的入栈序列的所有元素先入栈,然后将入栈之后的元素和出栈序列的第一个元素进行比较,相等就出栈,然后向后遍历出栈序列,如果不相等就继续将入栈序列中的元素入栈,这样循环的进行比较,如果最终入栈序列都已经为空,但是模拟栈中还有数据,就证明出栈序列和入栈序列不匹配,如果最终入栈序列为空且模拟栈为空,那就证明出栈序列和入栈序列是匹配的。
编码如下。
class Solution {
public:/*** 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可** * @param pushV int整型vector * @param popV int整型vector * @return bool布尔型*/bool IsPopOrder(vector<int>& pushV, vector<int>& popV) {// write code hereif(pushV.size()==0||popV.size()==0||pushV.size()!=popV.size()){return false;}int i=0;int j=0;//定义模拟栈stack<int> test_stack;for(i=0;i<pushV.size();i++){test_stack.push(pushV[i]);while(!test_stack.empty()&&test_stack.top()==popV[j]){test_stack.pop();j++;}}return test_stack.empty();}
};二叉树相关
题目三:从上往下打印出二叉树的每个节点,同层节点从左至右打印。(二叉树层序遍历)OJ地址
图示如下。
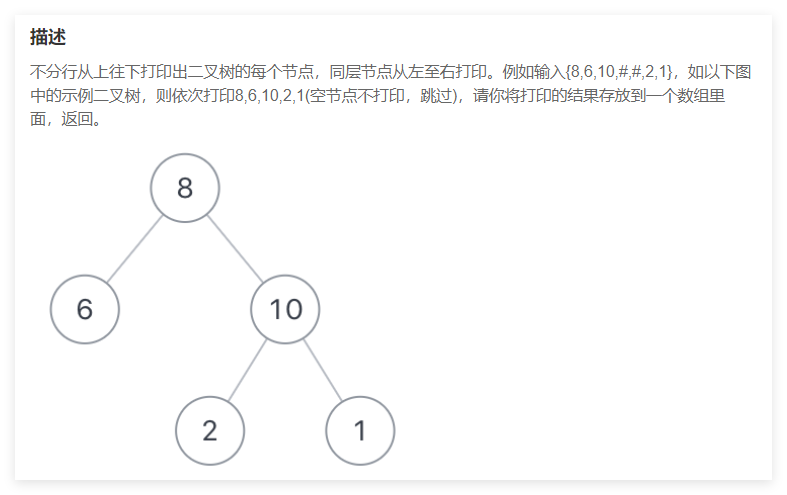
主要思想:我们使用了队列结构存储二叉树的节点。先将根节点 push 进队列中。从此开始循环,先读取队列头的元素,然后再将队头元素对应的节点的的左右孩子节点存入队列中然后,再 pop() 队头元素,然后再依次按照上述步骤去执行,直到队列为空,此时就相当于完成了对二叉树的层序遍历。
编码如下。
/*
struct TreeNode {int val;struct TreeNode *left;struct TreeNode *right;TreeNode(int x) :val(x), left(NULL), right(NULL) {}
};*/
class Solution {public:vector<int> PrintFromTopToBottom(TreeNode* root) {vector<int>v;if (root == nullptr) {return v;}queue<TreeNode*> q;//1.将根节点入队列q.push(root);while (!q.empty()) {//2.读取队头元素,访问头元素对应的节点的值TreeNode* node = q.front();v.push_back(node->val);//3.将该元素对应的左孩子和右孩子push进队列中if (node->left) {q.push(node->left);}if (node->right) {q.push(node->right);}//4.访问头结点q.pop();}return v;}
};
题目四: 输入一个非空整数数组,判断该数组是不是某二叉搜索树的后序遍历的结果。如果是则输出Yes,否则输出No。假设输 入的数组的任意两个数字都互不相同。OJ地址
图示如下。
搜索二叉树即,有一棵树,左子树的所有节点的值都比根节点的值小,右子树的所有节点的值都比根节点的值大,且该树的左子树也是一个搜索二叉树,这样的树我们就称其为搜索二叉树。
主要思想:采用递归思想,只要这个序列是一个搜索二叉树的后续遍历序列,那么这个序列除了最后一个元素之外,其它的元素一定可以被分为前后两个部分,前半部分的所有元素的值一定小于最后一个元素的值,后半部分的所有元素的值一定大于最后一个元素的值。因为搜索二叉树的性质对于其子树而言也是符合的,所以前半部分的元素和后半部分的元素一样也可以被分成前后两部分,这样无限分割,直到最后只剩下一个节点,只要所有分割之后的前后两部分都符合我们的上述性质,那么这个序列就是搜索二叉树的后续遍历序列。
编码如下。
class Solution {public:bool VerifySquenceOfBSThelp(vector<int> sequence, int begin, int end) {if (begin >= end) {return true;}//1.找到前半部分小于root的所有元素int i = begin;while (i < end && sequence[i] < sequence[end]) {i++;}//2.已经找到前半部分的小于root的元素,开始进行后半部分判断int j = i;while (j < end ) {if (sequence[j] <= sequence[end]) {return false;}j++;}//3.证明当前的树的左子树的值都比根节点的值小,右子树的值都比根节点的值大,但是还要去判断当前树的左子树和右子树是否//还满足当前的性质return VerifySquenceOfBSThelp( sequence, begin, i - 1) &&VerifySquenceOfBSThelp(sequence, i, end - 1);}bool VerifySquenceOfBST(vector<int> sequence) {if (sequence.size() == 0) {return false;}int begin = 0;int end = sequence.size() - 1;return VerifySquenceOfBSThelp(sequence, begin, end);}
};以上便是本期的所有内容。
本期内容到此结束^_^