【分布式系统中的“瑞士军刀”_ Zookeeper】二、Zookeeper 核心功能深度剖析与技术实现细节
在分布式系统的复杂生态中,Zookeeper 凭借其强大的核心功能,成为保障系统稳定运行的关键组件。上篇文章我们了解了 Zookeeper 的基础概念与安装配置,本文将继续深入剖析 Zookeeper 的核心功能,包括分布式锁、配置管理、命名服务和集群管理等。带你掌握这些功能的技术实现细节。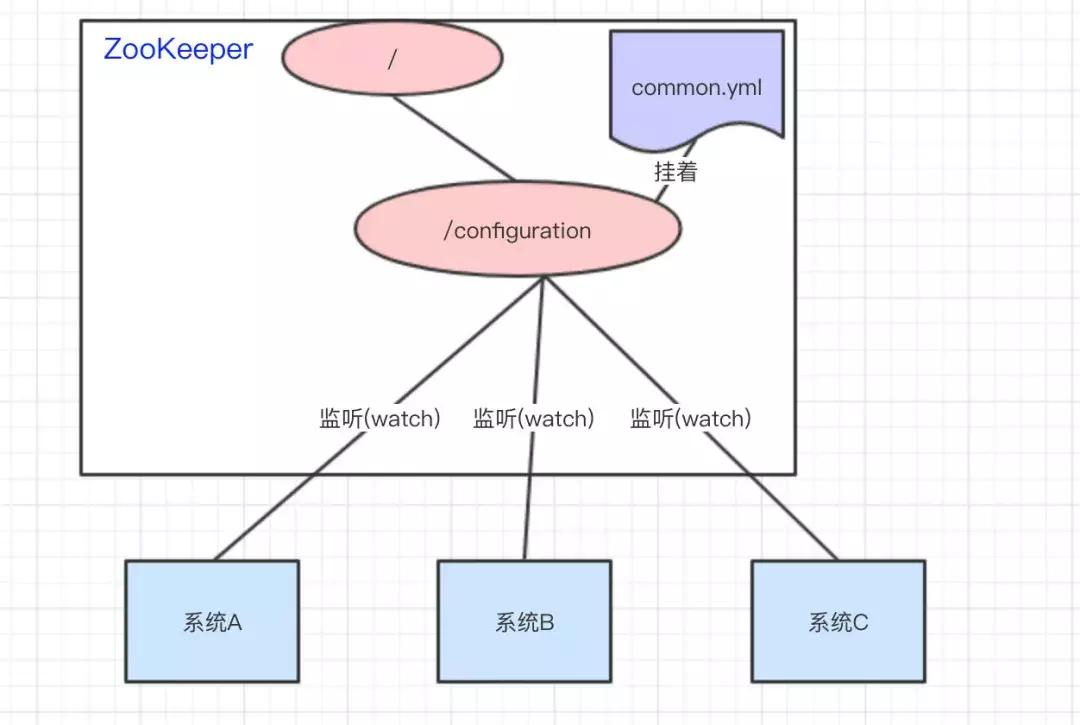
一、分布式锁
1.1 实现原理
Zookeeper 实现分布式锁的核心逻辑基于 ZNode 的特性。多个客户端竞争同一资源锁时,会在指定的 ZNode 路径下创建临时顺序节点。例如,创建路径为/lock/resource-的临时顺序节点,第一个客户端创建的节点可能是/lock/resource-0000000001,第二个客户端创建的是/lock/resource-0000000002,以此类推。序号最小的节点代表获取到锁,其他节点则监听比自己序号小的前一个节点。当持有锁的节点释放(会话结束,临时节点自动删除),下一个序号最小的节点监听到事件后,即可获取锁,从而实现分布式环境下的资源互斥访问。
1.2 配置与操作
在 CentOS 7 系统中,确保 Zookeeper 已正确安装并启动。通过 Zookeeper 命令行工具zkCli.sh连接到 Zookeeper 服务器:
/usr/local/zookeeper/bin/zkCli.sh -server localhost:2181假设我们要实现对某个共享资源的锁定,首先创建锁的根节点(持久节点):
create /lock ""模拟两个客户端竞争锁,客户端 1 创建临时顺序节点:
create -e -s /lock/resource- ""执行后,可能得到类似/lock/resource-0000000001的节点路径,此时客户端 1 获取到锁。客户端 2 同样创建临时顺序节点:
create -e -s /lock/resource- ""得到如/lock/resource-0000000002的节点路径,客户端 2 需监听/lock/resource-0000000001节点。使用ls -w命令设置监听:
ls -w /lock当客户端 1 完成操作,会话结束,其创建的临时顺序节点自动删除,客户端 2 监听到事件后,检查自己的节点是否为序号最小的节点,若是则获取锁。
1.3 代码示例
以下是使用 Java 实现的简单分布式锁代码:
import org.apache.zookeeper.*;
import org.apache.zookeeper.data.Stat;import java.io.IOException;
import java.util.Collections;
import java.util.List;
import java.util.concurrent.CountDownLatch;public class ZookeeperDistributedLock implements Watcher {private static final String ZOOKEEPER_SERVER = "localhost:2181";private static final String LOCK_ROOT = "/lock";private static final String LOCK_NODE_PREFIX = "/resource-";private ZooKeeper zk;private String currentNode;private String waitNode;private CountDownLatch latch = new CountDownLatch(1);public ZookeeperDistributedLock() throws IOException, KeeperException, InterruptedException {zk = new ZooKeeper(ZOOKEEPER_SERVER, 5000, this);Stat stat = zk.exists(LOCK_ROOT, false);if (stat == null) {zk.create(LOCK_ROOT, new byte[0], ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);}currentNode = zk.create(LOCK_ROOT + LOCK_NODE_PREFIX, new byte[0], ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);System.out.println("Created node: " + currentNode);List<String> children = zk.getChildren(LOCK_ROOT, true);Collections.sort(children);if (currentNode.equals(LOCK_ROOT + "/" + children.get(0))) {latch.countDown();} else {int index = children.indexOf(currentNode.substring(LOCK_ROOT.length() + 1));waitNode = LOCK_ROOT + "/" + children.get(index - 1);zk.getData(waitNode, true, null);}}@Overridepublic void process(WatchedEvent event) {if (event.getType() == Event.EventType.NodeDeleted && event.getPath().equals(waitNode)) {latch.countDown();}}public void lock() throws InterruptedException {latch.await();}public void unlock() throws KeeperException, InterruptedException {zk.delete(currentNode, -1);zk.close();}public static void main(String[] args) throws IOException, KeeperException, InterruptedException {ZookeeperDistributedLock lock = new ZookeeperDistributedLock();System.out.println("Trying to acquire lock...");lock.lock();System.out.println("Lock acquired, performing operations...");// 模拟业务操作Thread.sleep(3000);System.out.println("Operations completed, releasing lock...");lock.unlock();}
}二、配置管理
2.1 功能原理
在分布式系统中,众多节点需要统一管理配置信息。Zookeeper 通过将配置存储在 ZNode 节点中,利用 Watcher 机制实现配置的动态更新。当配置信息对应的 ZNode 数据发生变化时,Zookeeper 会通知所有监听该节点的客户端,客户端接收到通知后重新加载配置,从而保证各个节点使用的是最新配置。
2.2 配置与操作
在 CentOS 7 中,启动 Zookeeper 服务后,通过zkCli.sh连接服务器。创建配置存储节点,例如存储数据库连接配置:
create /config/db ""设置数据库连接配置数据:
set /config/db "jdbc:mysql://localhost:3306/mydb?user=root&password=123456"客户端可使用get -w命令监听配置节点:
get -w /config/db当配置需要更新时,修改节点数据:
set /config/db "jdbc:mysql://localhost:3306/newdb?user=admin&password=654321"监听该节点的客户端将收到配置更新通知并重新加载配置。
2.3 代码示例
以下是 Java 客户端监听配置更新的代码:
import org.apache.zookeeper.*;
import org.apache.zookeeper.data.Stat;import java.io.IOException;public class ZookeeperConfigListener implements Watcher {private static final String ZOOKEEPER_SERVER = "localhost:2181";private static final String CONFIG_NODE = "/config/db";private ZooKeeper zk;public ZookeeperConfigListener() throws IOException {zk = new ZooKeeper(ZOOKEEPER_SERVER, 5000, this);}public void listen() throws KeeperException, InterruptedException {while (true) {Stat stat = new Stat();byte[] data = zk.getData(CONFIG_NODE, true, stat);System.out.println("Current config: " + new String(data));Thread.sleep(1000);}}@Overridepublic void process(WatchedEvent event) {if (event.getType() == Event.EventType.NodeDataChanged && event.getPath().equals(CONFIG_NODE)) {try {System.out.println("Config updated, reloading...");byte[] data = zk.getData(CONFIG_NODE, true, null);System.out.println("New config: " + new String(data));} catch (KeeperException | InterruptedException e) {e.printStackTrace();}}}public static void main(String[] args) throws IOException, KeeperException, InterruptedException {ZookeeperConfigListener listener = new ZookeeperConfigListener();listener.listen();}
}三、命名服务
3.1 实现原理
Zookeeper 的命名服务通过树形结构的 ZNode 节点,实现服务实例的注册与发现。服务提供者启动时,将自身的服务信息(如服务地址、端口、接口等)以节点数据的形式注册到 Zookeeper 的指定路径下。服务消费者在需要调用服务时,从 Zookeeper 中查询对应服务的节点路径,获取可用的服务实例地址,进而实现服务调用。同时,利用 Watcher 机制,当服务实例的状态发生变化(如新增、下线)时,服务消费者能及时感知并更新可用服务列表。
3.2 配置与操作
假设存在一个用户服务,服务提供者在 CentOS 7 系统中启动后,通过zkCli.sh连接 Zookeeper,注册服务实例:
create /services/user-service/instance1 "192.168.1.100:8080"服务消费者查询服务实例:
ls /services/user-service获取到服务实例列表后,可进一步获取实例详细信息:
get /services/user-service/instance1并使用ls -w监听服务实例变化:
ls -w /services/user-service3.3 代码示例
以下是服务提供者注册服务和服务消费者发现服务的 Java 代码:
服务提供者
import org.apache.zookeeper.*;
import org.apache.zookeeper.data.Stat;import java.io.IOException;public class ZookeeperServiceProvider {private static final String ZOOKEEPER_SERVER = "localhost:2181";private static final String SERVICE_ROOT = "/services/user-service";private static final String INSTANCE_NAME = "instance1";private static final String SERVICE_ADDRESS = "192.168.1.100:8080";private ZooKeeper zk;public ZookeeperServiceProvider() throws IOException, KeeperException, InterruptedException {zk = new ZooKeeper(ZOOKEEPER_SERVER, 5000, watchedEvent -> {});Stat stat = zk.exists(SERVICE_ROOT, false);if (stat == null) {zk.create(SERVICE_ROOT, new byte[0], ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);}zk.create(SERVICE_ROOT + "/" + INSTANCE_NAME, SERVICE_ADDRESS.getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL);}public static void main(String[] args) throws IOException, KeeperException, InterruptedException {new ZookeeperServiceProvider();System.out.println("Service registered successfully");Thread.sleep(Long.MAX_VALUE);}
}服务消费者
import org.apache.zookeeper.*;
import org.apache.zookeeper.data.Stat;import java.io.IOException;
import java.util.List;public class ZookeeperServiceConsumer implements Watcher {private static final String ZOOKEEPER_SERVER = "localhost:2181";private static final String SERVICE_ROOT = "/services/user-service";private ZooKeeper zk;public ZookeeperServiceConsumer() throws IOException {zk = new ZooKeeper(ZOOKEEPER_SERVER, 5000, this);}public void discoverService() throws KeeperException, InterruptedException {while (true) {List<String> children = zk.getChildren(SERVICE_ROOT, true);for (String child : children) {Stat stat = new Stat();byte[] data = zk.getData(SERVICE_ROOT + "/" + child, false, stat);System.out.println("Available service instance: " + new String(data));}Thread.sleep(1000);}}@Overridepublic void process(WatchedEvent event) {if (event.getType() == Event.EventType.NodeChildrenChanged && event.getPath().equals(SERVICE_ROOT)) {try {System.out.println("Service instances changed, re-discovering...");discoverService();} catch (KeeperException | InterruptedException e) {e.printStackTrace();}}}public static void main(String[] args) throws IOException, KeeperException, InterruptedException {ZookeeperServiceConsumer consumer = new ZookeeperServiceConsumer();consumer.discoverService();}
}四、集群管理与协调
4.1 实现原理
Zookeeper 集群采用 Leader - Follower 模式进行管理与协调。集群启动时,通过选举算法(如 FastLeaderElection)选出一个 Leader 节点,其他节点作为 Follower。Leader 负责处理写请求,并将数据变更同步到 Follower;Follower 处理读请求并从 Leader 同步数据。当 Leader 节点故障时,集群会重新选举产生新的 Leader,保证系统的正常运行。选举过程基于节点的 ZXID(事务 ID)和节点 ID,确保拥有最新数据的节点成为 Leader。
4.2 配置与操作
在 CentOS 7 中搭建 Zookeeper 集群,需要修改zoo.cfg配置文件。假设有三个节点,分别在不同服务器上(这里假设在同一台机器的不同端口模拟),zoo.cfg配置如下:
tickTime=2000
dataDir=/var/lib/zookeeper
clientPort=2181
initLimit=10
syncLimit=5
server.1=localhost:2888:3888
server.2=localhost:2889:3889
server.3=localhost:2890:3890其中,server.x格式中,x为节点编号,第一个端口(如 2888)用于 Follower 与 Leader 之间的数据同步,第二个端口(如 3888)用于选举。
在每个节点的数据目录/var/lib/zookeeper下创建一个名为myid的文件,内容为该节点的编号(如节点 1 的myid文件内容为1,节点 2 为2,节点 3 为3):
echo "1" > /var/lib/zookeeper/myid分别启动三个节点的 Zookeeper 服务:
/usr/local/zookeeper/bin/zkServer.sh start通过zkServer.sh status命令查看节点角色:
/usr/local/zookeeper/bin/zkServer.sh status可看到一个节点为Leader,其他为Follower。
4.3 故障模拟与恢复
模拟 Leader 节点故障,停止 Leader 节点的 Zookeeper 服务:
/usr/local/zookeeper/bin/zkServer.sh stop一段时间后,再次使用zkServer.sh status命令查看,会发现集群重新选举出了新的 Leader,保证了集群的正常运行。