RAG技术与应用---0426
大语言模型>=3.10
课程中会用到python 工具箱:
faiss,modelscope,langchain,langchain_community,PyPDF2
1)大模型应用开发的三种模式
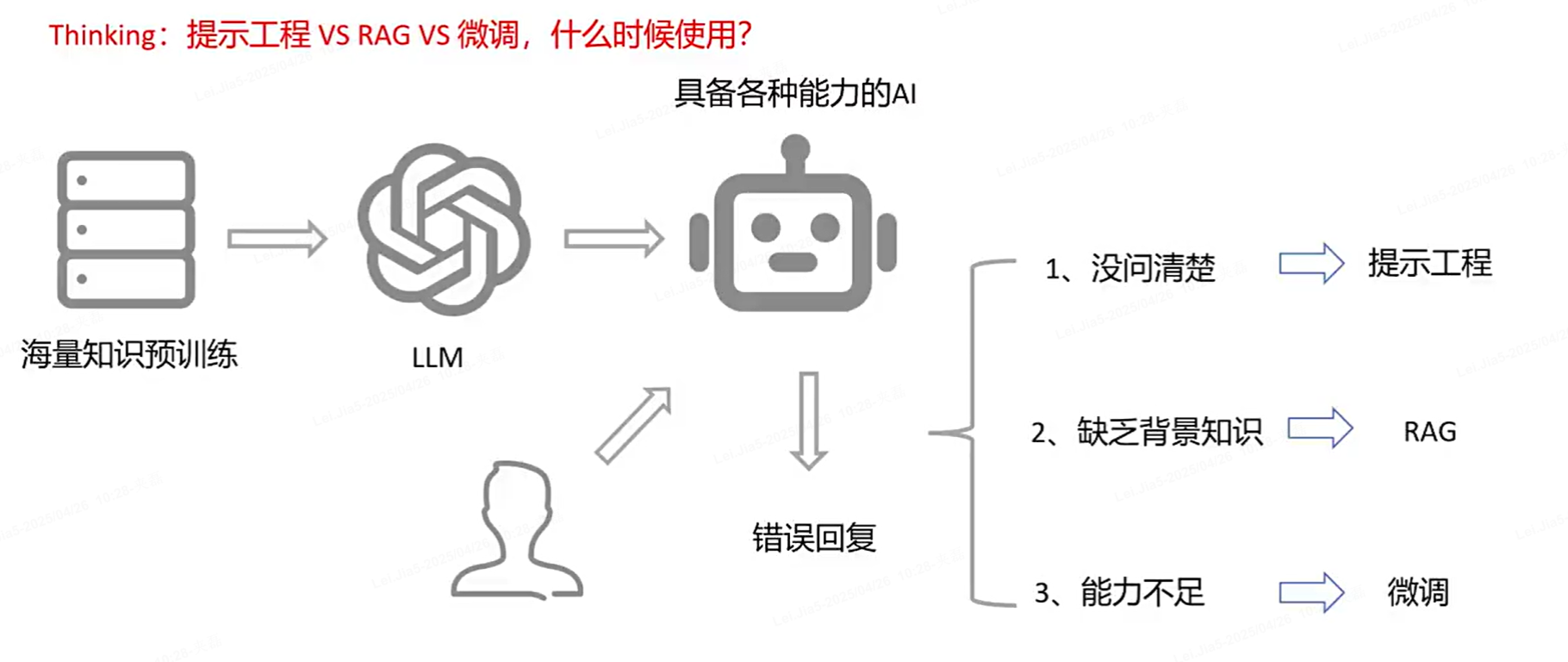
提示词没多少工作量,微调又花费时间费用,RAG是很多公司招聘用来对LLM进行应用开发的
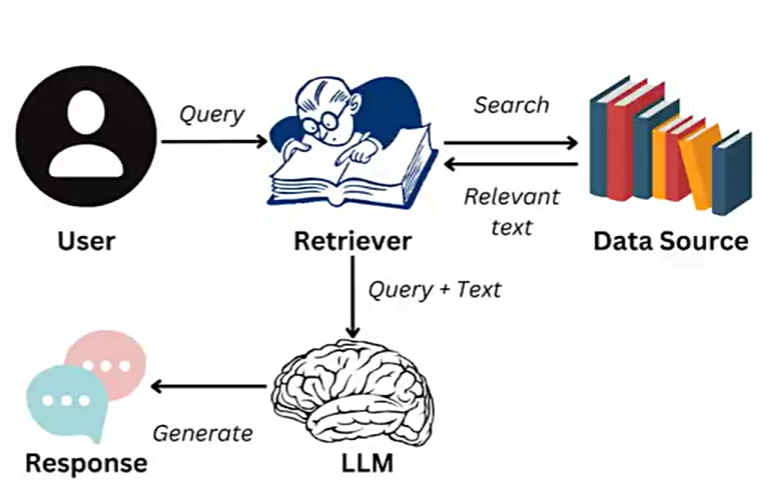
什么是RAG 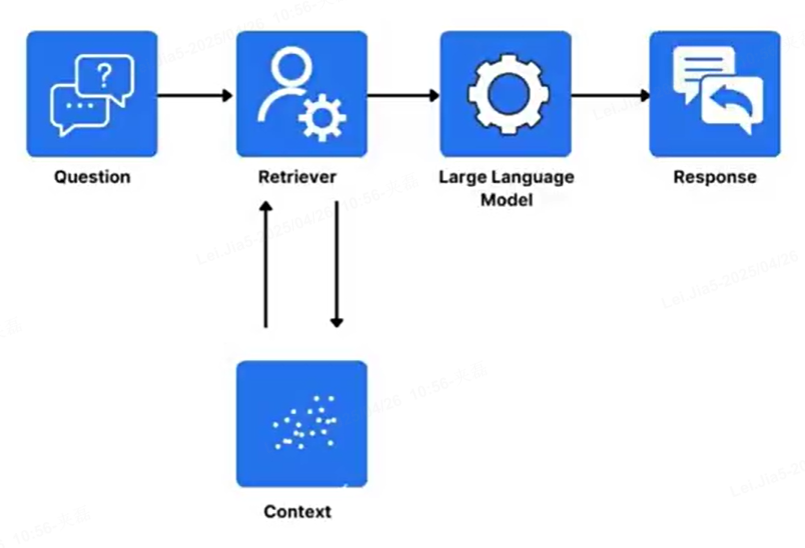
RAG(Retrieval-Augmented Generation):
检索增强生成,是一种结合信息检索(Retrieval)和文本生成(Generation)的技术
RAG技术通过实时检索相关文档或信息,并将其作为上下文输入到生成模型中,从而提高生成结果的时效性和准确性
RAG的优势是什么?
解决知识时效性问题:大模型的训练数据通常是静止的,无法涵盖最新信息,而RAG可以搜索外部知识库实时更新信息。
减少模型幻觉:通过引入外部知识,RAG能够减少模型生成虚假或不准确内容的可能性
提升专业领域回答质量:RAG能够结合垂直领域的专业知识库,生成更专业深度的回答
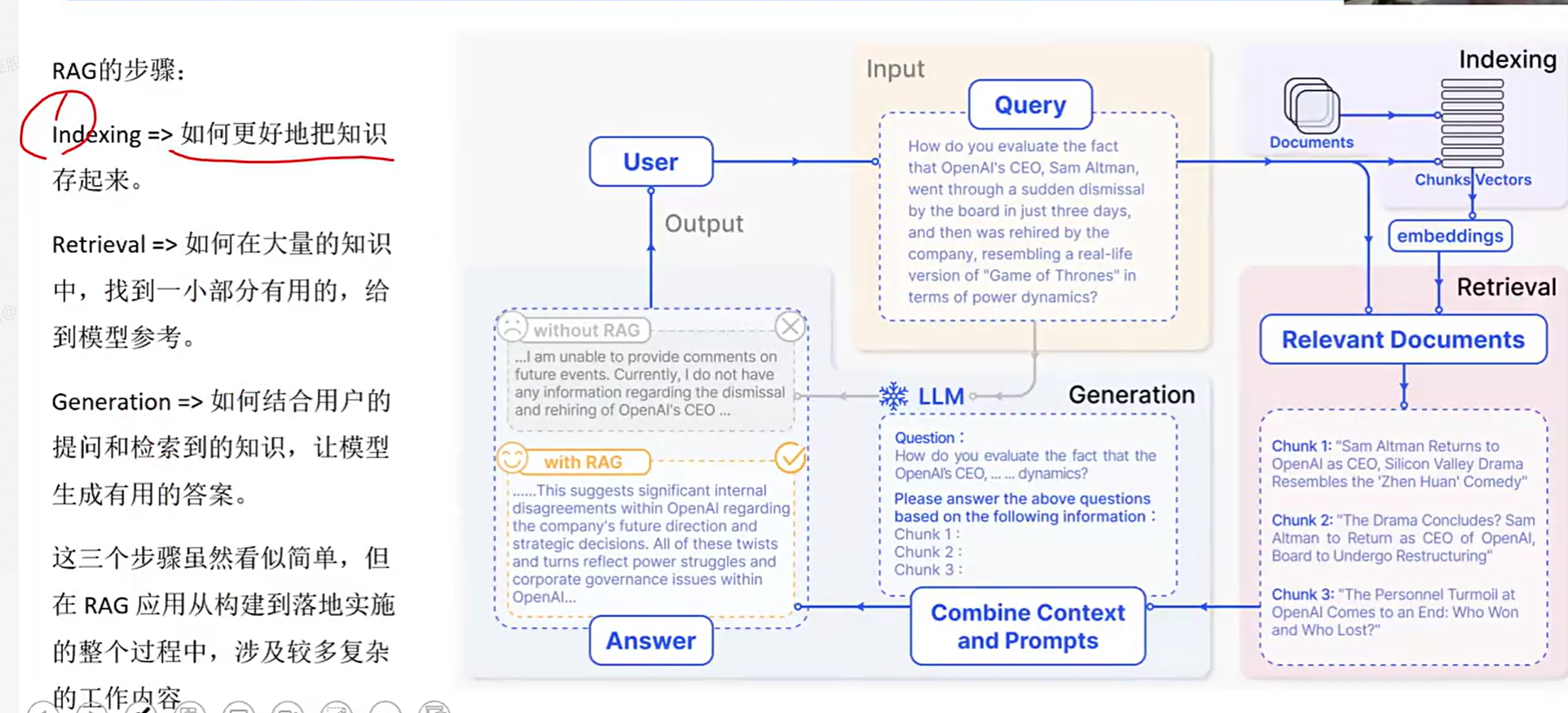
2)RAG的核心原理与流程
Step1,数据预处理
知识库构建:收集并整理文档,网页,数据库等多源数据,构建外部知识库
文档分块:将文档切分为适当大小的片段(chunk),以便后续检索。分块策略需要在语义完整性与检索效率之间取得平衡
向量化处理:使用嵌入模型(如BGE,M3E,Chinese-AIpaca-2)将文本块转为向量,并存储在向量数据库中
Step2,检索阶段
查询处理:将用户输入的问题转换为向量,并在向量数据库中进行相似度检索,找到最相关的文本片段
重排序:对检索结果进行相关性排序,选择最相关的片段作为生成阶段的输入
Step3,生成阶段
上下文组装:将检索到的文本片段与用户问题结合,形成增强的上下文输入
生成回答:大语言模型基于增强的上下文生成最终回答
Q1企业原始知识整理有什么特殊的格式吗?比如统一知识文档格式啥的
对于AI来说,Markdown是最友好的格式
如果想要将PPT转化为Markdown,
1)对PPT里面的内容进行extract
2)对抽取出来的内容 放到Markdown中
如果是图像 =>使用 Qwen-VL进行理解
Q2知识是存储在向量库还是其他库
向量数据库=>原文,embedding(相似度检索,找到最优价值的chunks)
Q3 原始文档切分chunk怎么做
a)指定规则,比如chunk size = 1000,overlap =10%,包含句子,标定
b)语义上的切分
c)对数据质量提升,和文档总结还需要多关注
NativeRAG
NoteBookLM使用(推荐工具)
需要在外网使用,https://notebooklm.google.com/
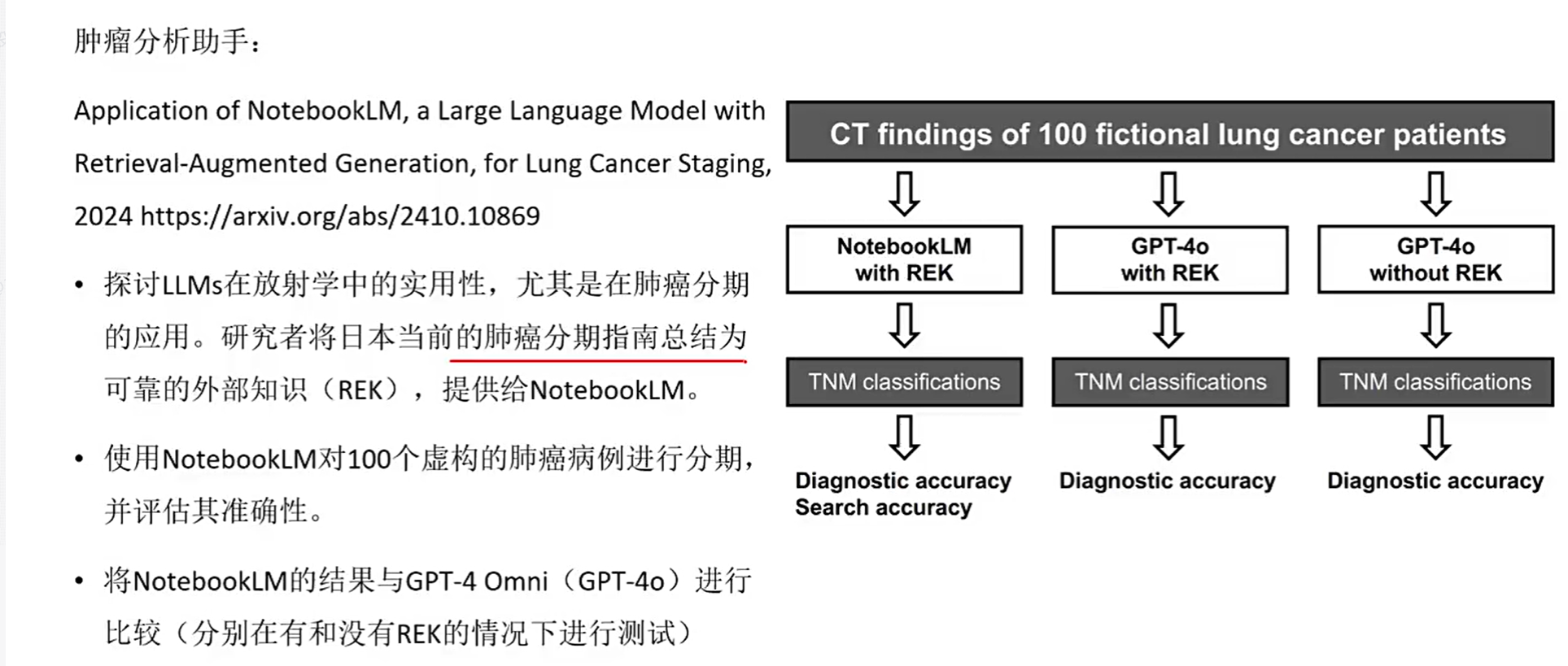
现成RAG产品 Cherry Studio,ima compilot,notebooklm ,钉钉助理很像coze
Embedding模型选择
Embedding嵌入向量中表达方式
Q1:Embedding模型选择:huggingface有打榜排名(开源和闭源)
Q2:在哪里找到embedding模型:https//modelscope.cn/
偏向知识类

偏向指令驱动和复杂任务模型

BGM3,Qwen不错,Jina适合端侧推理
Q1)在modescope下载很快

Q2)用户的Query指令:
1)instruction指令
2)知识
多模态的embedding
Q3)知识分为2阶段
在向量数据库中,可以有2个阶段
1)召回:快速采用多种策略进行粗筛过程,策略1基于关键词匹配100,策略2基于相似策略匹配
2)重排
向量数据库中保存的chunk可能会有1000万个=>召回快速筛出1000个=>重排序Top10
CASE:DeepSeek+Faiss搭建本地知识库检索
# 创建文本分割器,用于将长文本分割成小块
text_splitter =RecursiveCharacterTextSplitter(
separators=["\n\n","\n"," "],
chunk size=1000,#chunk大小的上限
chunk_overlap=200,#每个chunk之间重叠的比例
length function=len,
)

读取pdf然后用分割函数进行分隔,再从文本块创建知识库放入knowledge =FAISS.from_texts(chunks,embeddings)中,后面process_text_splitter 处理文本并创建向量存储
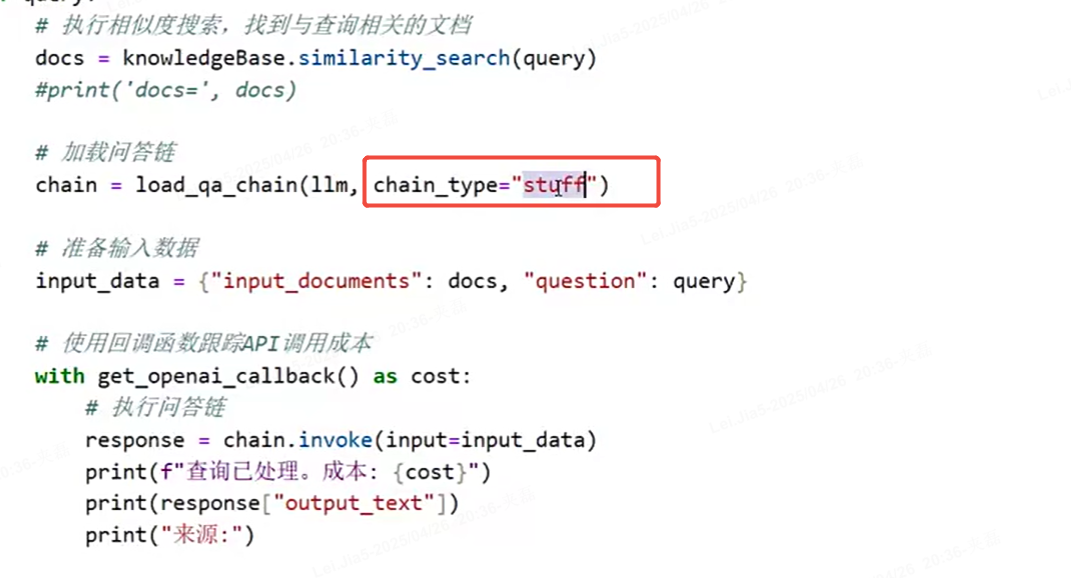
用langchai回答提示词promt的query
总结:
chatpdf- faiss代码中,使用2个模型
1)推理模型 qwen-turbo
2)Embedding模型text-embedding-v1
chunk策略:
chunk_size =1000, overlap = 200,分割是按照标定符号进行分割(句号,换行)
docs = knowledgeBase.similarity_search(query)
为什么要分块:
如果不分块,整个文件作为一个基本单元,那么文件里面的内容会比较多=>3072维的向量中不清晰
chunks是原文,chunk_embedding 3072维
可以进行新增知识库软件
1)扣子 coze软件 ,
上传文件,
创建设置:文档解析,分段策略,分段层级,配置存储
数据解析
2)Dify开源
3)LangChain实现了qa_chain,可以用fassis做向量数据库
知识库回答不了的,再调用推理模型吗?
知识库的作用是上下文,可能上下文中没有用户提到的问题,可以在prompt中说明,是否让LLM自己来进行回答,如果llm中没有相关知识,rag是不是就没有效果了。

LangChain中的问答链

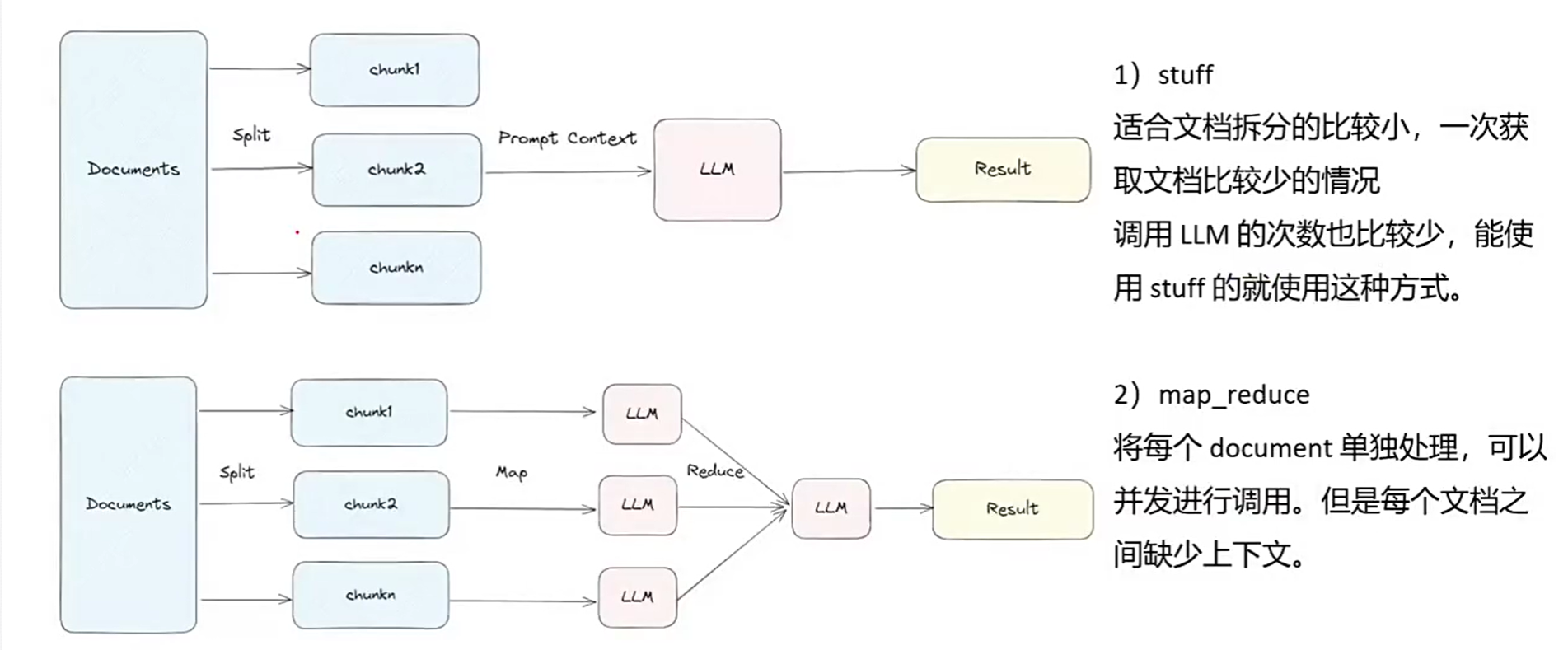
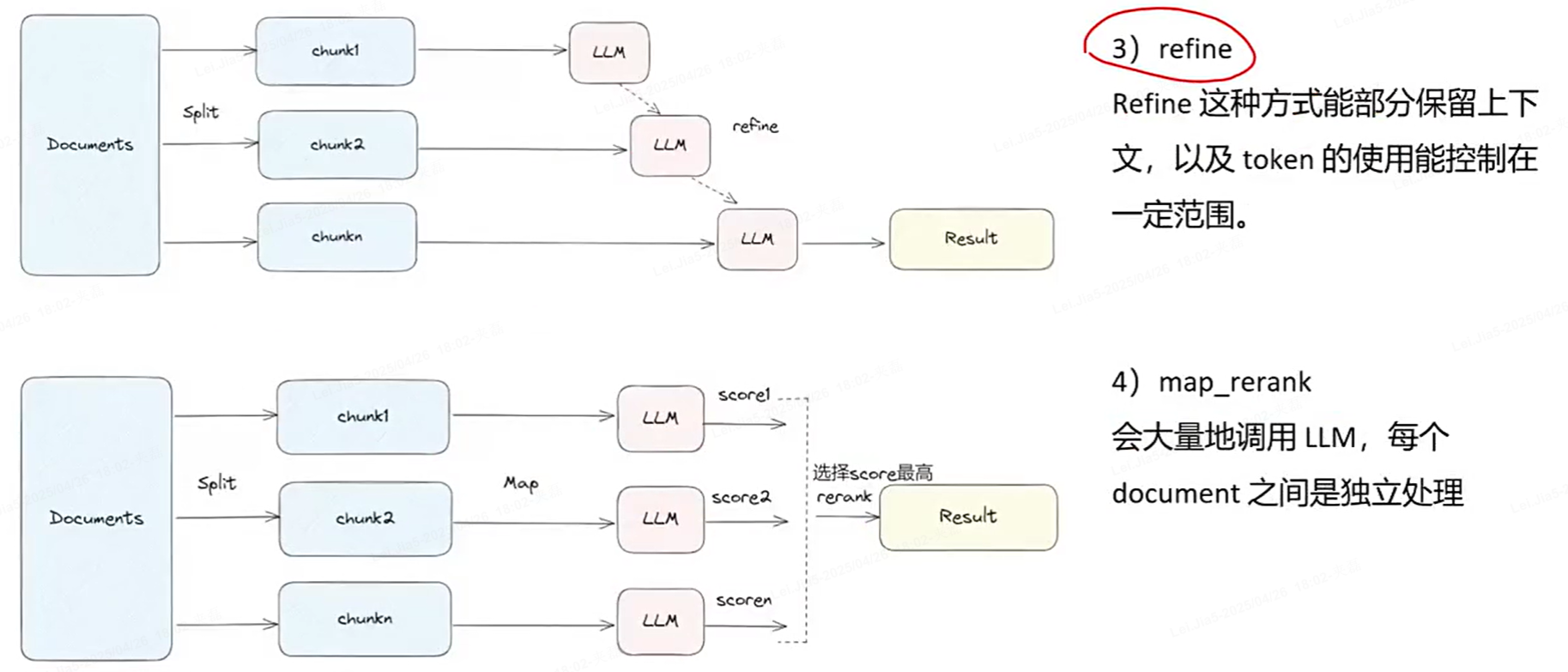
RAG的意义
RAG 是一种Filter过滤,检索过程透明(根据参考文献)

RAG常见问题--如何提升RAG质量
rag 准备阶段---检索阶段---生成阶段



layoutLM和layoutLLM
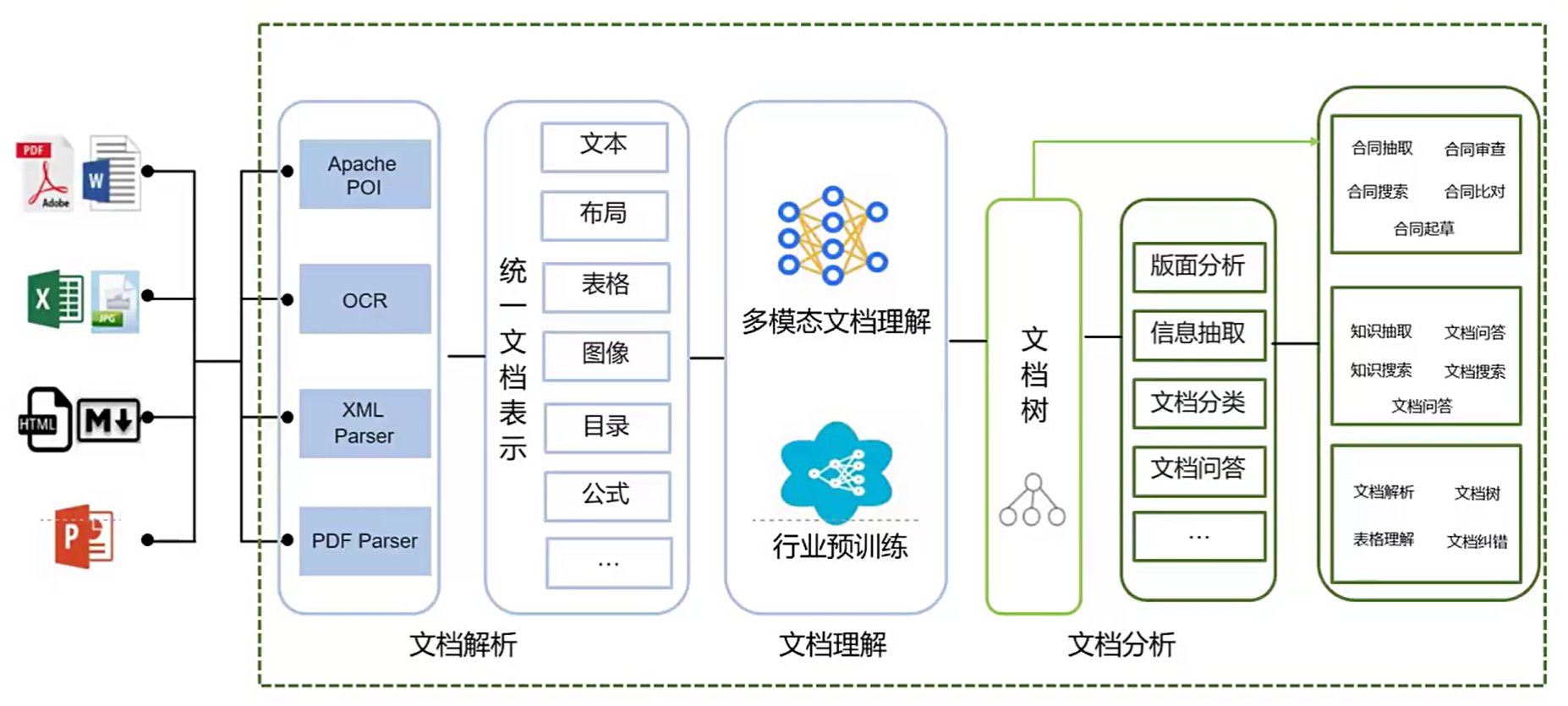




改进词提示模板
1)人工规则=>针对常见的Query,但是能设置的规则有限
2)LLM自己来思考
通过think=>优化了用户的提示词,让回答质量回答很高




RAG和Chunk关联是什么-->RAG 知识检索系统,chunk分块,是知识的最小单位
向量数据库是存储在本地文件夹下:knowledgeBase.save_local('./faiss-1')
如果文档里,有文字和图片,怎么保证图片跟相关文字不会拆成2个chunk呢?
如果PDF中有图片,需要先做预处理(将图片转化为文本),=>转化为全部文本
再做chunk(chunk_size =1000,overlap = 100)
总结=>概要级的
LangChain更灵活,个性化 dify更方便
不同的维度向量能计算相似度吗?还是会补充维度
需要变成统一维度
向量数据库和embedding模型是什么关系
向量数据库是一个软件,存储了很多chunk的embedding,给你提供了save,load,find_similarity的接口
embedding是一种向量格式
LLM可以兼容RAG吗.rag的优势怎么集成在LLM中
LLM(推理引擎)+RAG(外挂知识库)
私有化RAG用来数据安全性,如果知识来自于网络,用notebookLM是方便的(Gemini-embedding,Gemini2.5,召回和重拍的策略,以及对每篇文章做了预处理:文档的概览+关键词)
质量好=>开发工作少不了,使用开源Qwent-Agent=>RAG 质量不错的,但是会用token换取质量高
Thinking:个人想构建知识库,用于教学,资料主要是PPT,Word,Excel和PDF,如何低成本构建,并且可以保护知识产权?
先试试Qwen-Agent(效果还不错,而且是开源的)
Thinking:
结构化的数据可以用Qwen-Agent吗,免得做传统的SQL开发
Text2SOL.可以在Qwen-Agent中设置 Tool,Qwen-Agent不光是可以用于RAG,还可以让AI Agent
调用各种Tool,针对结构化的数据可以使用Text2SQL工具
Thinking:如果QWEN-AGENT非常的成熟的话,简单易做,那我们学RAG如何体现出我们自己的价值现阶段 没有很成熟的RAG系统
Qwen-Agent只是一种Agent框架,(集成了一部分 RAG的策略,召回、重排、以及生成的策略)
=>Qwen-Agent 回答质量还可以(比钉钉助理略好),但是不如 notebookLM自己使用Qwen-Agent的话,也可以加很多其他的策略,比如对数据的预处理
(开源)LayoutLM=>LayoutLLM=>进行提问和理解=>整理出来PDF和PPT理解,用于完善对应的知识markdown
Thinking:知识图谱和知识库有什么区别
知识图谱 是用Graph的方式,将知识链接起来。map=node,edge
我们就可以在知识图谱上,对知识进行计算,比如姚明的女儿的身高是多少?
chunk1:姚明的女儿叫 ABC
chunk2: ABC的身高是多少
Thinking:cherry studio和qwen-agent哪个RAG策略好?
cherry studio本身是个套壳产品,只是链接各种工具(LLM,MCP,RAG知识库)
qwen-agent:开源的框架,提供了一些tool,提供一些RAG策略