搜广推校招面经八十二
一、L1 和 L2 正则化的区别?对数据分布有什么要求,它们都能防止过拟合吗?
1.1. L1 与 L2 正则化的区别
| 特性 | L1 正则化(Lasso) | L2 正则化(Ridge) |
|---|---|---|
| 正则项 | λ * ∑|wᵢ| | λ ∗ ∑ ( w i 2 ) λ * ∑(wᵢ²) λ∗∑(wi2) |
| 几何意义 | 曼哈顿距离 | 欧几里得距离 |
| 是否稀疏 | 会产生稀疏解(可做特征选择) | 一般不会产生稀疏解 |
| 使用场景 | 特征选择、高维稀疏问题 | 多重共线性、连续性特征问题 |
1.2. 对数据分布的要求
- L1 正则化:
- 特征间相关性高时效果较差(可能任意选择一个);
- 更适合高维稀疏特征(如文本、基因数据);
- L2 正则化:
- 更适合特征均匀分布、非稀疏数据;
- 对特征间存在多重共线性效果更稳定;
- 对正态分布特征表现更好;
1.3. 它们都能防止过拟合吗?
是的,L1 和 L2 都能防止过拟合:
- L1 通过让某些特征权重变为 0,起到特征选择的作用;
- L2 通过惩罚权重过大的参数,使模型更平滑、更稳定;
1.4. 总结建议
| 场景 | 推荐使用的正则化方式 |
|---|---|
| 高维稀疏特征 | L1 |
| 需要自动特征选择 | L1 |
| 特征之间存在多重共线性 | L2 |
| 更注重解的稳定性 | L2 |
| 想结合两者优点 | Elastic Net(L1 + L2 混合) |
二、冷启动场景下Embedding初始化方案有那些?
2.1. 随机初始化
- 直接高斯或者均匀随机初始化。缺点就是没有任何先验知识可能导致收敛变慢或者模型不稳定
2.2. 使用平均 Embedding
- 所有未知的物品的Embedding = 所有老物品Embedding的平均值。这样可能稳定点,适用于新物品和老物品有几分相似
2.3. 相似对象初始化
- 基于新对象的一些辅助信息(如属性、上下文、元数据)找出最相似的已有对象,使用其 Embedding 或加权平均。
2.4. 搞迁移学习或者叫预训练模型初始化
- 先训练一个元模型就是输出Embedding,根据新对象的元特征生成对应的 Embedding
2.5. 使用图神经网络
- 这个比较复杂,图本身也不好训练,感觉只有任务要求很高的情况才搞这么复杂
三、详细解释一下DCN模型
论文原文:Deep & Cross Networkfor Ad Click Predictions, KDD’2017, Google
3.1. 设计这个模型其实也是为了更加充分的特征交叉,DNN + Cross Net模型架构如下:
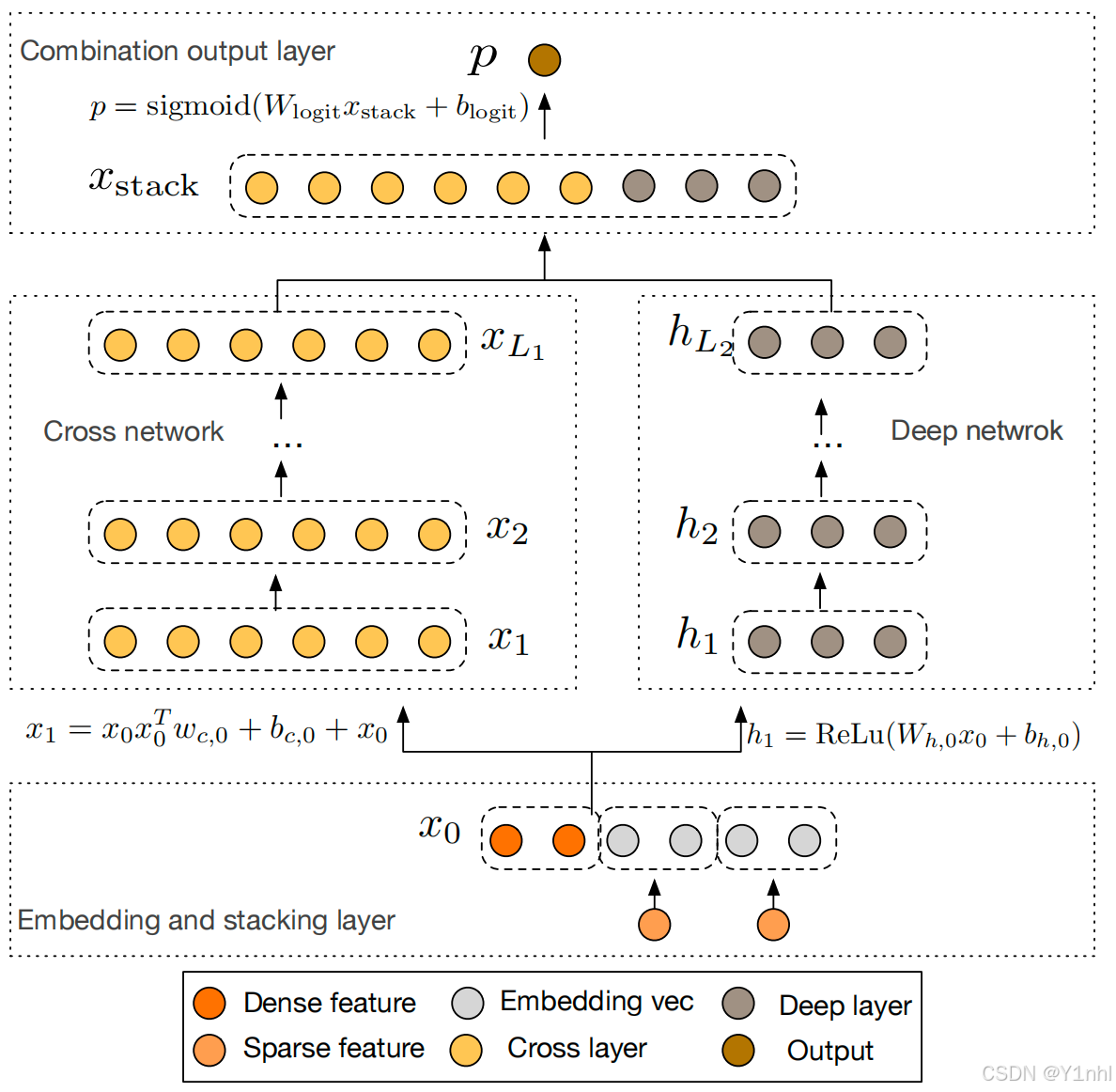
3.2. Cross Net 的具体细节
对于第 l 层:
x l + 1 = x 0 ⋅ ( w l T x l ) + b l + x l x_{l+1} = x_0 \cdot (w_l^T x_l) + b_l + x_l xl+1=x0⋅(wlTxl)+bl+xl
其中:
- x 0 x_0 x0 为原始输入向量(固定不变)
- x l x_l xl 为当前层输入
- w l ∈ R d w_l \in \mathbb{R}^d wl∈Rd, b l ∈ R d b_l \in \mathbb{R}^d bl∈Rd
·为哈达马积(逐元素乘)
3.3. Cross Net的优势
X i + 1 = X 0 X i T W i + X i + b i X_{i+1} = X_0 X_i^T W_i + X_i + b_i Xi+1=X0XiTWi+Xi+bi
X 0 X_0 X0可视为常数输入, W i W_i Wi 视为函数 F F F,公式可改写为:
X i + 1 = F ( X i ) + X i + b i X_{i+1} = F(X_i) + X_i + b_i Xi+1=F(Xi)+Xi+bi
与残差连接的对比
残差连接的标准公式: y = f ( x ) + x y = f(x) + x y=f(x)+x
相似之处
- 两者均采用“原始输入 + 变换结果”的结构。
- 均具备避免梯度消失的特性。
- 适合构建深层网络。
四、DIN 的 Target Attention 是怎么做的?
4.1. 背景:DIN 主要解决什么?
DIN(Deep Interest Network)用于电商推荐,它的特点是:
- 用户有很多历史行为(点击、浏览、收藏等)
- 但不是每次历史行为都和当前待推荐商品相关
所以,需要根据当前的待推荐商品(target item)动态地去关注用户的历史行为。这就是 Target Attention —— 针对不同的目标,动态建模兴趣的注意力机制。
4.2. DIN 中 Target Attention 的计算流程
假设:
- 用户历史行为序列: { h 1 , h 2 , . . . , h n } \{h_1, h_2, ..., h_n\} {h1,h2,...,hn}
- 当前候选物品(Target Item): t t t
4.2.1. Attention步骤是:
第一步:拼接特征
对每个历史行为 h i h_i hi 和当前target t t t,做特征组合。
通常的组合方法是:
- 拼接 (Concat): [ h i , t , h i − t , h i ∘ t ] [h_i, t, h_i - t, h_i \circ t] [hi,t,hi−t,hi∘t]
- h i − t h_i - t hi−t:捕捉差异
- h i ∘ t h_i \circ t hi∘t:逐元素乘(哈达马积,捕捉交互)
- [ ⋅ ] [\cdot] [⋅]:表示拼接
第二步:MLP 得分
将上面组合后的特征,输入一个小的MLP(多层感知机),输出一个相关性得分(attention weight)。
α i = MLP ( [ h i , t , h i − t , h i ∘ t ] ) \alpha_i = \text{MLP}([h_i, t, h_i - t, h_i \circ t]) αi=MLP([hi,t,hi−t,hi∘t])
注意:
- 这里的 MLP 是共享参数的。
- 不是标准的 “点积Attention”(比如 Transformer里的那种),而是通过 MLP学习得分。
第三步:Softmax归一化
对所有得分 { α 1 , α 2 , . . . , α n } \{\alpha_1, \alpha_2, ..., \alpha_n\} {α1,α2,...,αn} 做 softmax 归一化:
β i = exp ( α i ) ∑ j = 1 n exp ( α j ) \beta_i = \frac{\exp(\alpha_i)}{\sum_{j=1}^n \exp(\alpha_j)} βi=∑j=1nexp(αj)exp(αi)
这样可以保证权重加起来为 1。
第四步:加权求和
最后,用归一化后的权重对历史行为加权求和,得到一个综合向量:
h a t t n = ∑ i = 1 n β i h i h_{attn} = \sum_{i=1}^n \beta_i h_i hattn=i=1∑nβihi
这个 h a t t n h_{attn} hattn 就是最终代表用户兴趣的向量,专门针对当前target。