吴恩达深度学习作业之风格转移Neural Style Transfer (pytorch)
一.风格转移的原理
Neural Style Transfer(NST)使用先前训练过的卷积网络VGG19,并在此基础上构建。将在不同任务上训练过的网络应用于新任务的想法被称为迁移学习。之前的笔记已经记录,简单回忆一下
*卷积网络的较浅层倾向于检测较低级的特征,如边缘和简单纹理。
*更深的层倾向于检测更高级的特征,如更复杂纹理和对象类。
Gatys 等科学家发现,如果用预训练VGG模型不同层的卷积输出作为拟合特征,则可以拟合出不同的图像:
如果你对预训练VGG模型不熟,也不用担心。VGG是一个包含很多卷积层的神经网络模型。所谓预训练VGG模型,就是在图像分类数据集上训练过的VGG模型。经过了预训练后,VGG模型的各个卷积层都能提取出图像的一些特征,尽管这些特征是我们人类无法理解的。

上图中,越靠右边的图像,是用越深的卷积层特征进行特征拟合恢复出来的图像。从这些图像恢复结果可以看出,更深的特征只会保留图像的内容(形状),而难以保留图像的纹理(天空的颜色、房子的颜色)。
看到这,大家可能有一些疑惑:这些图片具体是怎么拟合出来的呢?让我们和刚刚一样,详细地看一看这一图像生成过程。
假设我们想生成上面的图c,即第三个卷积层的拟合结果。我们已经得到了模型model_conv123 ,其包含了预训练VGG里的前三个卷积层。我们可以设立以下的优化目标:
source_feature = model_conv123(source_img)
input_feature = model_conv123(input_img)
# minimize MSE(source_feature, input_feature)首先,我们可以预处理出源图像的特征。注意,这里我们要用source_feature.detach()来把source_feature 从计算图中取出,防止源图像被PyTorch自动更新。
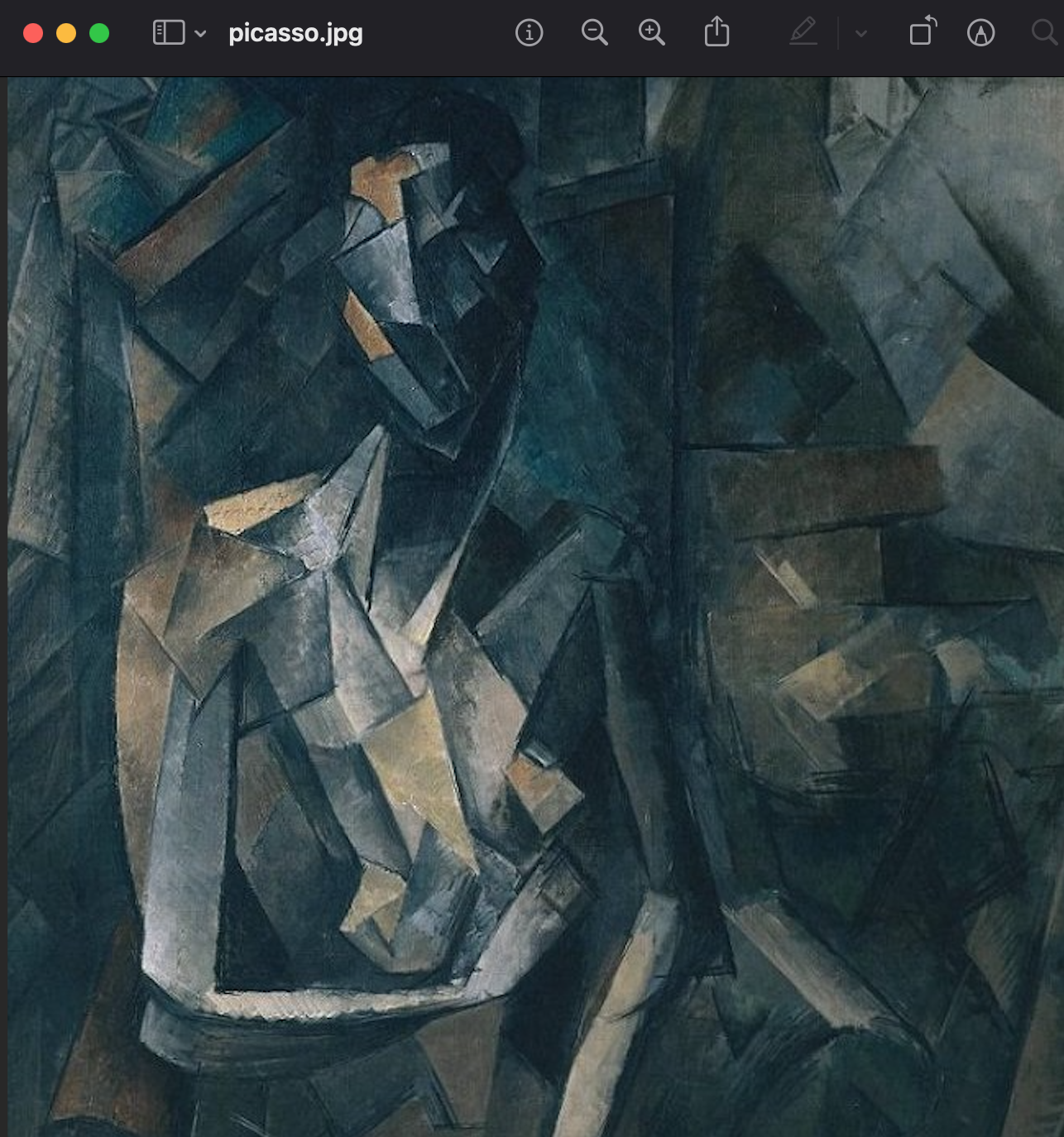
source_img = read_image('dldemos/StyleTransfer/picasso.jpg')
source_feature = model_conv123(source_img).detach()之后,我们可以用类似的方法做梯度下降:
steps = 0
while steps <= 50:def closure():global stepsoptimizer.zero_grad()input_feature = model_conv123(input_img)loss = F.mse_loss(input_feature, source_feature)loss.backward()steps += 1if steps % 5 == 0:print(f"Step {steps}:")print(f"Loss: {loss}")return lossoptimizer.step(closure)通过这种方法,我们可以生成一幅拟合了源图像在神经网络中的深层特征的目标图像。那么,怎么利用这种方法完成风格迁移呢?
Gatys 等科学家发现,不仅是卷积结果可以当作拟合特征,VGG的一些其他中间结果也可以作为拟合特征。受到之前用CNN做纹理生成的工作[2]的启发,他们发现用卷积结果的Gram矩阵作为拟合特征可以得到另一种图像生成效果:
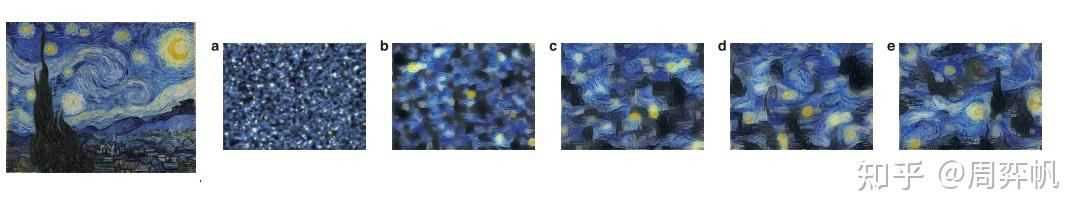
上图中,右边a-e是用VGG不同卷积结果的Gram矩阵作为拟合特征,得到的对左图的拟合图像。可以看出,用这种特征来拟合的话,生成图像会失去原图的内容(比如星星和物体的位置完全变了),但是会保持图像的整体风格。
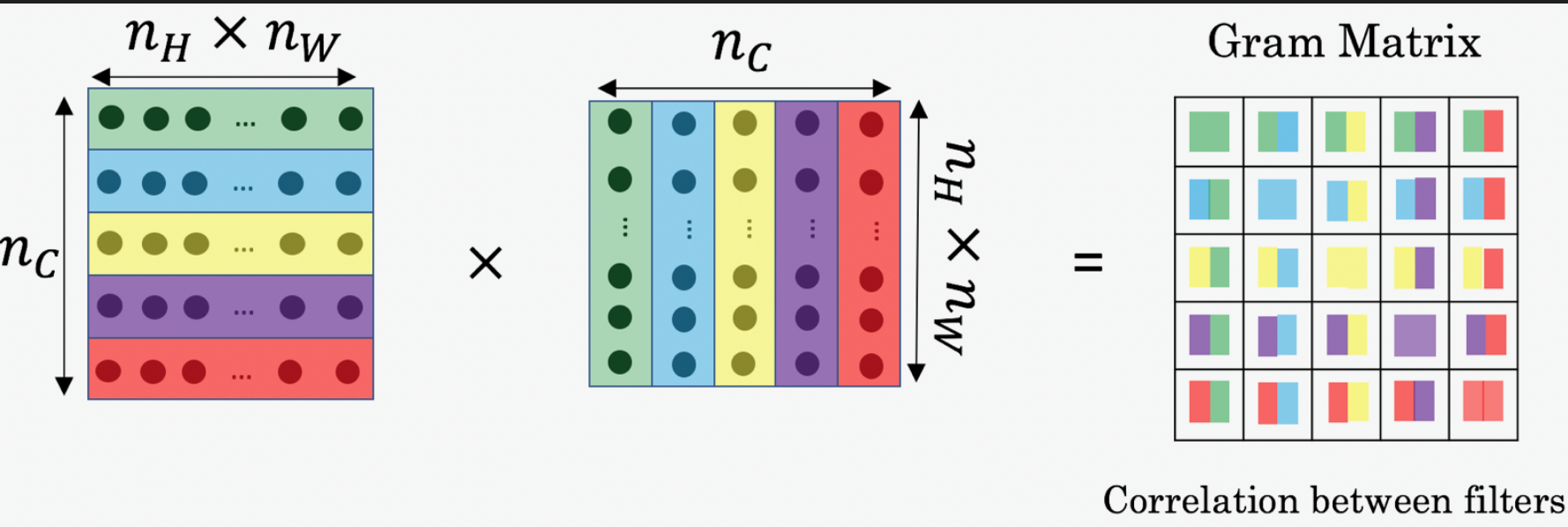
Gram矩阵定义在两个特征的矩阵F_1, F_2 上。其中,每个特征矩阵F 是VGG某层的卷积输出张量F_conv(shape: [n, h, w]) reshape成一个矩阵F (shape: [n, h * w]) 的结果。Gram矩阵,就是两个特征矩阵F_1, F_2的内积,即F_1 每个通道的特征向量和F_2 每个通道的特征向量的相似度构成的矩阵。我们这里假设F_1=F_2 ,即对某个卷积特征自身生成Gram矩阵。
这段逻辑用代码实现如下:
def gram(x: torch.Tensor):n, c, h, w = x.shapex_reshaped = x.view(n* c, h * w) # 形状: (n, c, h*w)gram_matrix = torch.mm(x_reshaped, x_reshaped.T) # (n, c, c)gram_matrix = gram_matrix / (n * c * h * w) # 归一化return gram_matrixGram矩阵表示的是通道之间的相似性,与位置无关。因此,Gram矩阵是一种具有空间不变性(spatial invariance)的指标,可以描述整幅图像的性质,适用于拟合风格。与之相对,我们之前拟合图像内容时用的是图像每一个位置的特征,这一个指标是和空间相关的。Gram矩阵只是拟合风格的一种可选指标。后续研究证明,还有其他类似的特征也能达到和Gram矩阵一样的效果。我们不需要过分纠结于Gram矩阵的原理。
看到这里,大家或许已经明白风格迁移是怎么实现的了。风格迁移,其实就是既拟合一幅图像的内容,又去拟合另一幅图像的风格。我们把前一幅图像叫做内容图像,后一幅图像叫做风格图像
它合并了两个图像,即"content"图像C和"style"图像S,以创建图像(G)。生成的图像G将图像C的“内容”与图像S的“风格”结合起来。
首先要建立内容content损失函数和style损失函数
,最后得到
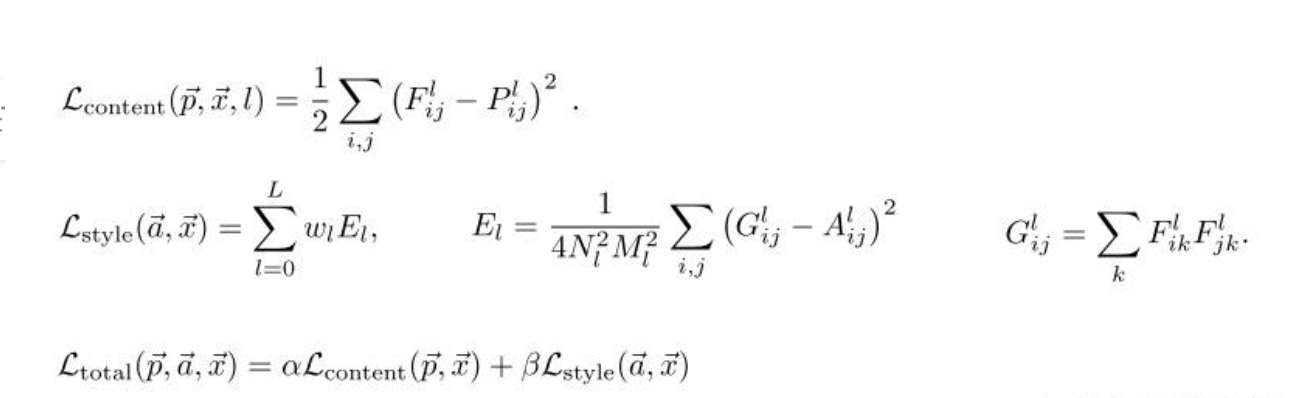
上面第一行公式表达的是内容误差,第二行公式表达的是风格误差。
第一行公式中,F ,P 分别是生成图像的卷积特征和源图像的卷积特征。
第二行公式中, F 是生成图像的卷积特征,G 是对 F 的Gram矩阵,A 是源图像卷积特征的Gram矩阵, E_l表示第 l层的风格误差。在论文中,总风格误差是某几层风格误差的加权和,其中权重为w1 。事实上,不仅总风格误差可以用多层风格误差的加权和表示,总内容误差也可以用多层内容误差的加权和表示。只是在原论文中,只使用了一层的内容误差。
第三行中, 分别是内容误差的权重和风格误差的权重。实际上,我们只用考虑
的比值即可。如果
较大,则说明优化内容的权重更大,生成出来的图像更靠近内容图像。反之亦然。
只要用这个误差去替换我们刚刚代码实现中的误差,就可以完成图像的风格迁移了.
思考
其实这篇文章是比较早期的用神经网络做风格迁移的工作。在近两年里,肯定有许多试图改进此方法的研究。时至今日,再去深究这篇文章里的一些细节(为什么用Gram矩阵,应该用VGG的哪些层做拟合)已经意义不大了。我们应该关注的是这篇文章的主要思想。
这篇文章对我的最大启发是:神经网络不仅可以用于在大批数据集上训练,完成一项通用的任务,还可以经过预训练,当作一个特征提取器,为其他任务提供额外的信息。同样,要记住神经网络只是优化任务的一项特例,我们完全可以把梯度下降法用于普通的优化任务中。在这种利用了神经网络的参数,而不去更新神经网络参数的优化任务中,梯度下降法也是适用的。
此外,这篇文章中提到的「风格」也是很有趣的一项属性。这篇文章算是首次利用了神经网络中的信息,用于提取内容、风格等图像属性。这种提取属性(尤其是提取风格)的想法被运用到了很多的后续研究中,比如大名鼎鼎的StyleGAN。
长期以来,人们总是把神经网络当成黑盒。但是,这篇文章给了我们一个掀开黑盒的思路:通过拟合神经网络中卷积核的特征,我们能够窥见神经网络每一层保留了哪些信息。相信在之后的研究中,人们能够更细致地去研究神经网络的内在原理。
二. 代码实现细节
import torch
import torch.nn.functional as F
import torchvision.models as models
import torchvision.transforms as transforms
from PIL import Imageimg_size = (256, 256)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')def read_image(image_path):pipeline = transforms.Compose([transforms.Resize((img_size)),transforms.ToTensor()])img = Image.open(image_path).convert('RGB')img = pipeline(img).unsqueeze(0)return img.to(device, torch.float)def save_image(tensor, image_path):toPIL = transforms.ToPILImage()img = tensor.detach().cpu().clone()img = img.squeeze(0)img = toPIL(img)img.save(image_path)style_img = read_image('picasso.jpg')
content_img = read_image('dancing.jpg')class ContentLoss(torch.nn.Module):def __init__(self, target: torch.Tensor):super().__init__()self.target = target.detach()def forward(self, input):self.loss = F.mse_loss(input, self.target)return inputdef gram(x: torch.Tensor):n, c, h, w = x.shapex_reshaped = x.view(n* c, h * w) # 形状: (n, c, h*w)gram_matrix = torch.mm(x_reshaped, x_reshaped.T) # (n, c, c)gram_matrix = gram_matrix / (n * c * h * w) # 归一化return gram_matrix
在神经网络中,这个类Contentloss其实没有做任何运算(forward 直接把input 返回了)。但是,这个类缓存了内容误差值。我们稍后可以取出这个类实例的loss ,丢进最终的误差计算公式里。这种通过插入一个不进行计算的torch.nn.Module 来保存中间计算结果的方法,算是使用PyTorch的一个小技巧。
之后,编写gram 矩阵的计算方法及风格误差的计算“函数”:
class StyleLoss(torch.nn.Module):def __init__(self, target: torch.Tensor):super().__init__()self.target = gram(target.detach()).detach()def forward(self, input):G = gram(input)self.loss = F.mse_loss(G, self.target)return inputclass Normalization(torch.nn.Module):def __init__(self, mean, std):super().__init__()self.mean = torch.tensor(mean).to(device).reshape(-1, 1, 1)self.std = torch.tensor(std).to(device).reshape(-1, 1, 1)def forward(self, img):return (img - self.mean) / self.stddef get_model_and_losses(content_img, style_img, content_layers, style_layers):num_loss = 0expected_num_loss = len(content_layers) + len(style_layers)content_losses = []style_losses = []model = torch.nn.Sequential(Normalization([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]))cnn = models.vgg19(pretrained=True).features.to(device).eval()i = 0for layer in cnn.children():if isinstance(layer, torch.nn.Conv2d):i += 1name = f'conv_{i}'elif isinstance(layer, torch.nn.ReLU):name = f'relu_{i}'layer = torch.nn.ReLU(inplace=False)elif isinstance(layer, torch.nn.MaxPool2d):name = f'pool_{i}'elif isinstance(layer, torch.nn.BatchNorm2d):name = f'bn_{i}'else:raise RuntimeError(f'Unrecognized layer: {layer.__class__.__name__}')model.add_module(name, layer)if name in content_layers:# add content loss:target = model(content_img)content_loss = ContentLoss(target)model.add_module(f'content_loss_{i}', content_loss)content_losses.append(content_loss)num_loss += 1if name in style_layers:target_feature = model(style_img)style_loss = StyleLoss(target_feature)model.add_module(f'style_loss_{i}', style_loss)style_losses.append(style_loss)num_loss += 1if num_loss >= expected_num_loss:breakreturn model, content_losses, style_lossesinput_img = torch.randn(1, 3, *img_size, device=device)
model, content_losses, style_losses = get_model_and_losses(content_img, style_img, default_content_layers, default_style_layers)input_img.requires_grad_(True)
model.requires_grad_(False)optimizer = optim.LBFGS([input_img])
steps = 0
prev_loss = 0
while steps <= 1000 and prev_loss < 100:def closure():with torch.no_grad():input_img.clamp_(0, 1)global stepsglobal prev_lossoptimizer.zero_grad()model(input_img)content_loss = 0style_loss = 0for ls in content_losses:content_loss += ls.lossfor ls in style_losses:style_loss += ls.lossloss = content_weight * content_loss + style_weight * style_lossloss.backward()steps += 1if steps % 50 == 0:print(f'Step {steps}:')print(f'Loss: {loss}')save_image(input_img, f'work_dirs/output_{steps}.jpg')prev_loss = lossreturn lossoptimizer.step(closure)
with torch.no_grad():input_img.clamp_(0, 1)
save_image(input_img, 'work_dirs/output.jpg')
1)VGG模型对输入数据的分布有要求(即对输入数据均值、标准差有要求)。为了方便起见,我们可以写一个标准化分布的层,作为最终模型的第一层。
2)接下来,我们可以利用torchvision中的预训练VGG,提取出其中我们需要的模块。我们还需要获取刚刚编写的误差类的实例的引用,以计算最终的误差。
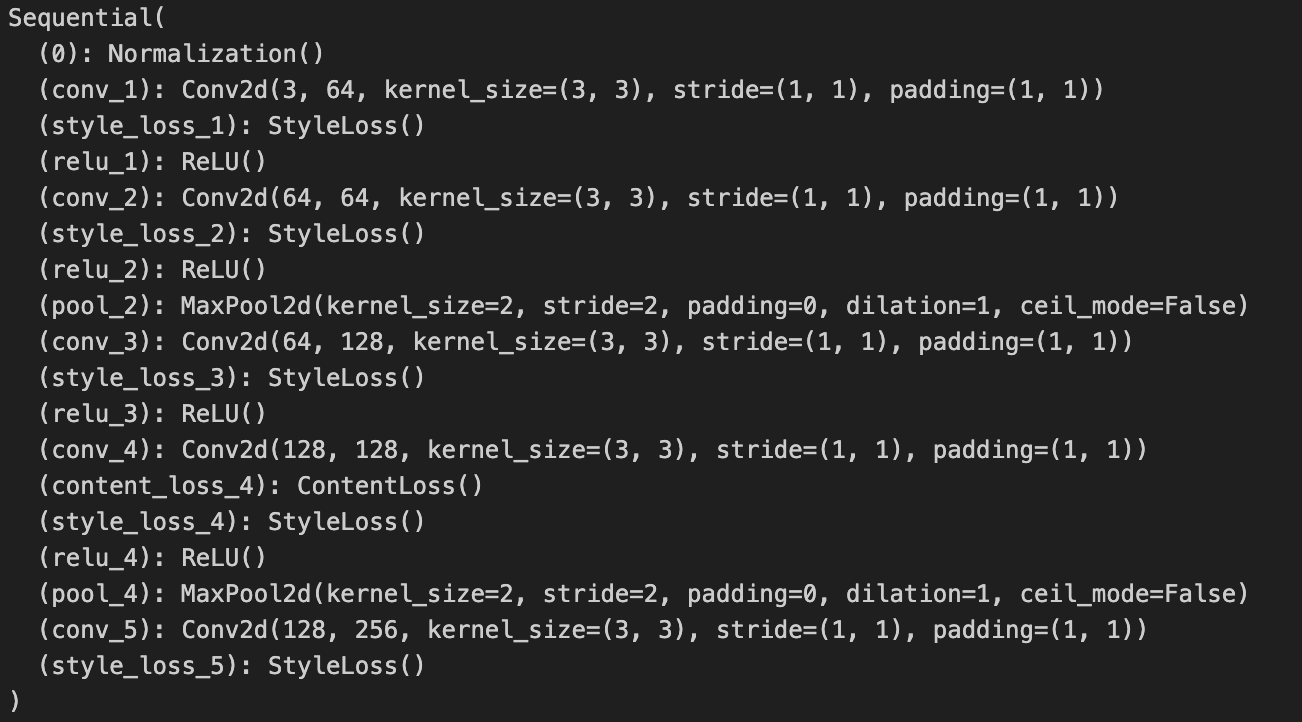
这段代码的实现思路是:我们不直接把VGG拿过来用,而是新建一个用torch.nn.Sequential 表示的序列模型。我们先把标准化层加入这个序列,再把原VGG中的计算层逐个加入我们的新序列模型中。一旦我们发现某个计算层的计算结果要用作计算误差,我们就在这个层后面加一个用于捕获误差的误差模块。
3)这里有些地方要注意:VGG有多个模块,其中我们只需要包含卷积层的.features 模块。另外,我们只需要那些用于计算误差的层,当我们发现所有和误差相关的层都放入了新模型后,就可以停止新建模块了。
4)最后用梯度下降生成图像
这里的步骤和正文中的类似,我们先准备好输入的噪声图像、模型、误差类实例的引用,并设置好哪些参数需要优化,哪些不需要。
5)由于我们有先验知识,知道图像位于(0, 1)之间,每一轮优化前我们可以手动约束一下图像的数值以加速训练。
运行程序的时候会有一些特殊情况。有些时候,任务的误差loss 会突然涨到一个很高的值,过几轮才会恢复正常。为了保证输出的loss 总是不那么大,我加了一个prev_loss < 100 的要求。
这里steps 的值是可以调的,误差究竟多小才算小也取决于实际任务以及content_weight, style_weight的大小。这些超参数都是可以去调试的。
6)输出:
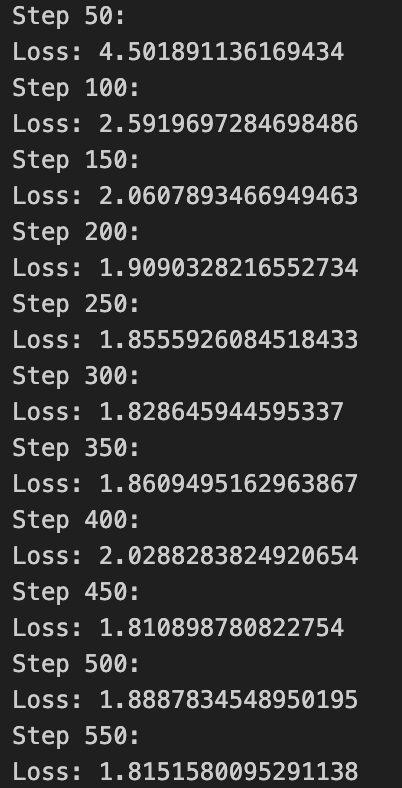





三. 用到的pytorch的基础知识:
1.torchvision.transforms 和 torchvision.models
torchvision.transforms 和 torchvision.models 是 PyTorch 生态中 torchvision 库的两个核心模块,分别用于 数据预处理 和 预训练模型加载
1.1 torchvision.transforms:数据预处理工具
-
功能
-
提供一系列图像预处理和数据增强操作,用于将原始数据转换为适合模型输入的格式。
-
支持对图像进行标准化、裁剪、翻转、调整尺寸等操作。
-
通常与
Dataset类结合使用,构建数据加载流程。 -
常用操作
操作 作用 示例 Resize调整图像尺寸 transforms.Resize((224, 224))ToTensor将 PIL 图像或 NumPy 数组转换为张量(维度顺序变为 [C, H, W],值域[0.0, 1.0])transforms.ToTensor()Normalize标准化张量(减去均值,除以标准差) transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])RandomCrop随机裁剪 transforms.RandomCrop(128)RandomHorizontalFlip随机水平翻转 transforms.RandomHorizontalFlip(p=0.5)ColorJitter调整亮度、对比度、饱和度 transforms.ColorJitter(brightness=0.2, contrast=0.2)
1.11 transforms.Compose
在 PyTorch 中,transforms.Compose 是一个用于组合多个数据变换操作的工具类。它的作用是将一系列的数据预处理步骤按顺序串联成一个“流水线”(pipeline)
pipeline = transforms.Compose([transforms.Resize((img_size)), # 调整图像尺寸transforms.ToTensor() # 将图像转为张量
])Compose 的作用
将这两个步骤按顺序组合,形成一个完整的预处理流程。当调用 pipeline(img) 时,会先执行 Resize,再执行 ToTensor。
不同的顺序可能导致完全不同的结果。例如:
-
正确顺序:先调整尺寸,再转为张量(因为
Resize操作需要 PIL 图像输入)。 -
错误顺序:若先转为张量,再调整尺寸,会因张量格式与 PIL 不兼容而报错。
1.12 transforms.Resize((img_size))
-
作用:将图像调整到指定尺寸(如
(224, 224))。 -
输入:PIL 图像(如通过
Image.open加载的图像)。 -
输出:调整尺寸后的 PIL 图像。
1.13. transforms.ToTensor()
-
作用:将 PIL 图像或 NumPy 数组转换为 PyTorch 张量,并自动进行以下处理:
-
像素值从
[0, 255]缩放到[0.0, 1.0]。 -
维度顺序从
(H, W, C)(高、宽、通道)调整为(C, H, W)(通道优先)。
-
1.14. 初始化 PIL 图像转换器
toPIL = transforms.ToPILImage()
作用:创建一个将张量转换为 PIL 图像的对象。
输入要求:张量必须是
(C, H, W)形状(通道优先),且值域为[0.0, 1.0]或[0, 255](整数)。
1.15. 处理输入张量
img = tensor.detach().cpu().clone()
detach():
将张量从计算图中分离,阻断梯度传播(若tensor是模型输出且需要反向传播,保存时无需保留梯度)。
cpu():
将张量从 GPU 转移到 CPU(若张量在 GPU 上,直接转换到 PIL 会报错)。
clone():
创建张量的副本,避免修改原始数据。
1.16. 去除批次维度
img = img.squeeze(0)
作用:如果输入张量包含批次维度(如形状为
(1, C, H, W)),去除第 0 维,得到(C, H, W)。
1.17. 转换为 PIL 图像并保存
img = toPIL(img)
img.save(image_path)-
toPIL(img):将张量转换为 PIL 图像。 -
save(image_path):保存为图像文件(格式由路径后缀决定,如.jpg、.png)。
1.2 torchvision.models:预训练模型库
-
功能
-
提供经典计算机视觉模型的预训练权重(如 ResNet、VGG、AlexNet 等)。
-
支持直接加载模型用于推理或迁移学习(微调)。
-
模型覆盖图像分类、目标检测、语义分割等任务。
-
常用模型
模型 描述 加载示例 ResNet 深度残差网络(ResNet-18/34/50/101/152) models.resnet50(pretrained=True)VGG VGG-11/13/16/19(带 BatchNorm 的变体) models.vgg16_bn(pretrained=True)AlexNet 经典的浅层卷积网络 models.alexnet(pretrained=True)MobileNet 轻量级模型(适合移动端) models.mobilenet_v2(pretrained=True)EfficientNet 高效率的模型家族 models.efficientnet_b0(pretrained=True)
示例 :加载预先训练模型
from torchvision import models# 加载预训练的 ResNet-50 模型(用于图像分类)
model = models.resnet50(pretrained=True) # pretrained=True 表示加载预训练权重# 冻结所有参数(用于迁移学习,仅训练最后一层)
for param in model.parameters():param.requires_grad = False# 替换最后一层(适配自定义分类任务)
num_classes = 10 # 假设任务有 10 个类别
model.fc = nn.Linear(model.fc.in_features, num_classes)# 将模型移动到 GPU(如果可用)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)示例 :联合使用示例(完整流程)
import torch
from torchvision import transforms, models
from torch.utils.data import DataLoader
from torchvision.datasets import CIFAR10# 1. 定义数据预处理
transform = transforms.Compose([transforms.Resize(224), # CIFAR-10 图像较小,需放大到 224x224transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])# 2. 加载数据集
train_dataset = CIFAR10(root="./data", train=True, download=True, transform=transform)
test_dataset = CIFAR10(root="./data", train=False, download=True, transform=transform)# 3. 创建 DataLoader
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)# 4. 加载预训练模型并微调
model = models.resnet18(pretrained=True)
model.fc = nn.Linear(model.fc.in_features, 10) # CIFAR-10 有 10 个类别# 5. 训练和评估
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
criterion = nn.CrossEntropyLoss()# ... 训练循环代码 ...1.21 直接推理 (inference)
直接使用预训练模型对输入数据进行预测,无需修改模型结构或训练权重。
步骤
-
加载预训练模型:使用
pretrained=True参数下载并加载预训练权重。 -
切换模型为评估模式:关闭 Dropout 和 BatchNorm 的随机性。
-
预处理输入数据:使用与模型训练时相同的预处理流程。
-
执行推理:将输入数据传递给模型,得到预测结果。
import torch
from torchvision import models, transforms
from PIL import Image# 1. 加载预训练模型
model = models.resnet18(pretrained=True) # 加载 ResNet-18 的预训练权重
model.eval() # 切换为评估模式# 2. 定义预处理流程(必须与训练时一致)
preprocess = transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])# 3. 加载并预处理图像
image = Image.open("cat.jpg") # 输入图像
input_tensor = preprocess(image)
input_batch = input_tensor.unsqueeze(0) # 添加批次维度 [1, C, H, W]# 4. 执行推理
with torch.no_grad():output = model(input_batch)# 5. 解析预测结果(假设是 ImageNet 分类任务)
probabilities = torch.nn.functional.softmax(output[0], dim=0)
_, predicted_class = torch.max(probabilities, 0)
print(f"Predicted class index: {predicted_class.item()}")1.22 迁移学习(Transfer Learning / 微调 Fine-tuning)
在预训练模型的基础上,修改部分结构并重新训练,使其适应新任务(如不同类别数的分类任务)。
步骤
-
加载预训练模型:同样使用
pretrained=True。 -
冻结底层参数:保留预训练模型的特征提取能力,防止底层权重被破坏。
-
替换顶层结构:修改分类层(如全连接层),适配新任务的输出维度。
-
训练新层(或部分解冻层):仅训练新增的层或部分解冻的层。
import torch
import torch.nn as nn
from torchvision import models# 1. 加载预训练模型
model = models.resnet18(pretrained=True)# 2. 冻结所有参数(可选)
for param in model.parameters():param.requires_grad = False# 3. 替换最后一层(全连接层)
num_classes = 10 # 假设新任务有 10 个类别
model.fc = nn.Linear(model.fc.in_features, num_classes)# 4. 仅训练新添加的层(或解冻部分层)
optimizer = torch.optim.Adam(model.fc.parameters(), lr=1e-3) # 仅优化最后一层# 5. 定义损失函数
criterion = nn.CrossEntropyLoss()# 6. 训练循环(示例)
for epoch in range(10):for inputs, labels in train_loader: # 假设 train_loader 已定义outputs = model(inputs)loss = criterion(outputs, labels)optimizer.zero_grad()loss.backward()optimizer.step()1.23 关键细节说明
-
冻结参数 vs 解冻参数
-
冻结参数:通过
param.requires_grad = False阻止梯度计算,适用于保留预训练特征。 -
解冻参数:若希望微调部分层(如后几层卷积),可选择性解冻:
# 解冻最后两个残差块 for name, param in model.named_parameters():if "layer4" in name or "fc" in name: # ResNet 的 layer4 是最后一个残差块param.requires_grad = True -
替换模型顶层
-
分类任务:通常替换全连接层(
model.fc)。 -
不同任务:
-
目标检测:替换检测头(如 Faster R-CNN 的 ROI 分类器)。
-
语义分割:替换解码器部分(如 U-Net 的上采样路径)。
-
-
数据预处理一致性
-
必须使用与预训练模型相同的预处理参数(如
Resize、Normalize的均值和标准差)。 -
学习率策略
-
微调时,通常为新层设置较大的学习率,为解冻层设置较小的学习率:
optimizer = torch.optim.Adam([{"params": model.fc.parameters(), "lr": 1e-3}, # 新层高学习率{"params": model.layer4.parameters(), "lr": 1e-4} # 解冻层低学习率 ])
常见预训练模型及修改方式
| 模型 | 顶层结构位置 | 替换方法示例 |
|---|---|---|
| ResNet | model.fc | model.fc = nn.Linear(512, 10) |
| VGG | model.classifier[-1] | model.classifier[-1] = nn.Linear(4096, 10) |
| AlexNet | model.classifier[-1] | 同上 |
| MobileNetV2 | model.classifier[-1] | 同上 |
总结
-
直接推理:加载模型 → 预处理数据 → 调用
model.eval()→ 预测。 -
迁移学习:加载模型 → 冻结参数 → 修改顶层 → 选择性解冻 → 训练新层。
-
关键点:保持预处理一致、合理冻结/解冻层、调整学习率策略。
2. transforms.Compose
在 PyTorch 中,transforms.Compose 是一个用于组合多个数据变换操作的工具类。它的作用是将一系列的数据预处理步骤按顺序串联成一个“流水线”(pipeline)
pipeline = transforms.Compose([transforms.Resize((img_size)), # 调整图像尺寸transforms.ToTensor() # 将图像转为张量
])2.1 transforms.Resize((img_size))
-
作用:将图像调整到指定尺寸(如
(224, 224))。 -
输入:PIL 图像(如通过
Image.open加载的图像)。 -
输出:调整尺寸后的 PIL 图像。
2.2. transforms.ToTensor()
-
作用:将 PIL 图像或 NumPy 数组转换为 PyTorch 张量,并自动进行以下处理:
-
像素值从
[0, 255]缩放到[0.0, 1.0]。 -
维度顺序从
(H, W, C)(高、宽、通道)调整为(C, H, W)(通道优先)。
-
Compose 的作用
将这两个步骤按顺序组合,形成一个完整的预处理流程。当调用 pipeline(img) 时,会先执行 Resize,再执行 ToTensor。
不同的顺序可能导致完全不同的结果。例如:
-
正确顺序:先调整尺寸,再转为张量(因为
Resize操作需要 PIL 图像输入)。 -
错误顺序:若先转为张量,再调整尺寸,会因张量格式与 PIL 不兼容而报错。
2.3. 初始化 PIL 图像转换器
toPIL = transforms.ToPILImage()
作用:创建一个将张量转换为 PIL 图像的对象。
输入要求:张量必须是
(C, H, W)形状(通道优先),且值域为[0.0, 1.0]或[0, 255](整数)。
2.4. 处理输入张量
img = tensor.detach().cpu().clone()
detach():
将张量从计算图中分离,阻断梯度传播(若tensor是模型输出且需要反向传播,保存时无需保留梯度)。
cpu():
将张量从 GPU 转移到 CPU(若张量在 GPU 上,直接转换到 PIL 会报错)。
clone():
创建张量的副本,避免修改原始数据。
2.5. 去除批次维度
img = img.squeeze(0)
作用:如果输入张量包含批次维度(如形状为
(1, C, H, W)),去除第 0 维,得到(C, H, W)。
2.6. 转换为 PIL 图像并保存
img = toPIL(img)
img.save(image_path)-
toPIL(img):将张量转换为 PIL 图像。 -
save(image_path):保存为图像文件(格式由路径后缀决定,如.jpg、.png)。
3. torch.optim.LBFGS
在 PyTorch 中,torch.optim.LBFGS 是一种基于 L-BFGS(Limited-memory Broyden–Fletcher–Goldfarb–Shanno)算法 的优化器,属于拟牛顿法(Quasi-Newton Methods)的一种。它通过近似 Hessian 矩阵(二阶导数信息)来优化目标函数,适用于中小规模的高维参数优化问题。
3.1核心特点
-
内存高效
L-BFGS 通过存储有限步长的历史梯度信息来近似 Hessian 矩阵,避免直接存储大型矩阵,适合内存敏感的场景。 -
二阶优化
利用梯度的一阶信息和近似的二阶信息(曲率),通常比一阶优化器(如 SGD、Adam)收敛更快,尤其在参数较少时。 -
适用场景
-
参数规模较小(如优化输入数据而非网络权重)。
-
需要高精度优化的任务(如风格迁移、图像生成)。
-
optimizer = torch.optim.LBFGS([input_img])
-
输入参数:
[input_img]表示需要优化的变量列表。-
此处
input_img是待优化的张量(如风格迁移中的生成图像),而非神经网络的权重参数。 -
列表形式是因为 PyTorch 优化器要求参数为可迭代对象(即使只有一个参数)。
-
-
3.2 L-BFGS 的独特使用方式
-
L-BFGS 优化器需要定义一个 闭包函数(closure),在每次迭代中重新计算损失并执行反向传播。这是因为它可能需要多次评估目标函数以更新 Hessian 近似。
-
for epoch in range(num_epochs):def closure():optimizer.zero_grad() # 清空梯度loss = compute_loss(input_img) # 计算损失(需基于当前 input_img)loss.backward() # 反向传播计算梯度return lossoptimizer.step(closure) # 执行一步优化(自动调用 closure)3.3 代码示例
-
import torch from torch import optim# 初始化输入图像(需优化) input_img = torch.randn(1, 3, 256, 256, requires_grad=True).to(device)# 定义 L-BFGS 优化器(仅优化 input_img) optimizer = optim.LBFGS([input_img], lr=0.8, max_iter=20)# 风格迁移损失计算函数 def compute_loss(input_img):# 提取内容和风格特征content_features = vgg_model(content_img)style_features = vgg_model(style_img)generated_features = vgg_model(input_img)# 计算内容损失和风格损失content_loss = F.mse_loss(generated_features, content_features)style_loss = F.mse_loss(gram(generated_features), gram(style_features))total_loss = content_loss + style_loss * 1e6return total_loss# 训练循环 for epoch in range(100):def closure():optimizer.zero_grad()loss = compute_loss(input_img)loss.backward()return lossoptimizer.step(closure)# 限制像素值范围with torch.no_grad():input_img.clamp_(0, 1)