人工智能数学基础(一):人工智能与数学
在人工智能领域,数学是不可或缺的基石。无论是算法的设计、模型的训练还是结果的评估,都离不开数学的支持。接下来,我将带大家深入了解人工智能数学基础,包括微积分、线性代数、概率论、数理统计和最优化理论,并通过 Python 代码示例,让大家更加直观地理解这些数学知识在人工智能中的应用。资源绑定附上完整资源供读者参考学习!
1.1 微积分
微积分是研究函数的微分、积分以及有关概念和应用的数学分支,在人工智能中有着广泛的应用,如神经网络的梯度下降法等优化算法就离不开微积分。
基本概念
-
导数 :表示函数在某一点处的变化率。例如,函数 y = f(x),导数 f’(x) 表示 x 变化时 y 的变化速度。
-
积分 :用于计算曲线与坐标轴之间的面积或体积等。例如,计算函数 y = f(x) 在区间 [a, b] 上与 x 轴围成的面积。
在人工智能算法中的应用
-
梯度下降法 :这是机器学习中常用的一种优化算法,通过计算损失函数对模型参数的导数(即梯度),不断调整参数,使损失函数最小化。在神经网络训练中,梯度下降法用于更新神经元的权重,以提高模型的准确性。
Python 求解示例
计算函数 y = x^3 - 2x^2 + 3x - 4 的导数,并绘制函数图像及其导数图像。
import numpy as np
import matplotlib.pyplot as plt
from sympy import symbols, diffplt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False# 定义变量和函数
x = symbols('x')
y = x**3 - 2*x**2 + 3*x -4# 计算导数
dy_dx = diff(y, x)
print("导数为:", dy_dx)# 绘制函数图像及其导数图像
x_vals = np.linspace(-10, 10, 400)
y_vals = [val**3 - 2*val**2 + 3*val -4 for val in x_vals]
dy_dx_vals = [3*val**2 -4*val +3 for val in x_vals]plt.figure(figsize=(10, 6))
plt.plot(x_vals, y_vals, label='y = x^3 - 2x^2 + 3x -4')
plt.plot(x_vals, dy_dx_vals, label="导数:3x^2 -4x +3", linestyle='--')
plt.xlabel('x')
plt.ylabel('y')
plt.title('函数及其导数图像')
plt.legend()
plt.grid(True)
plt.show()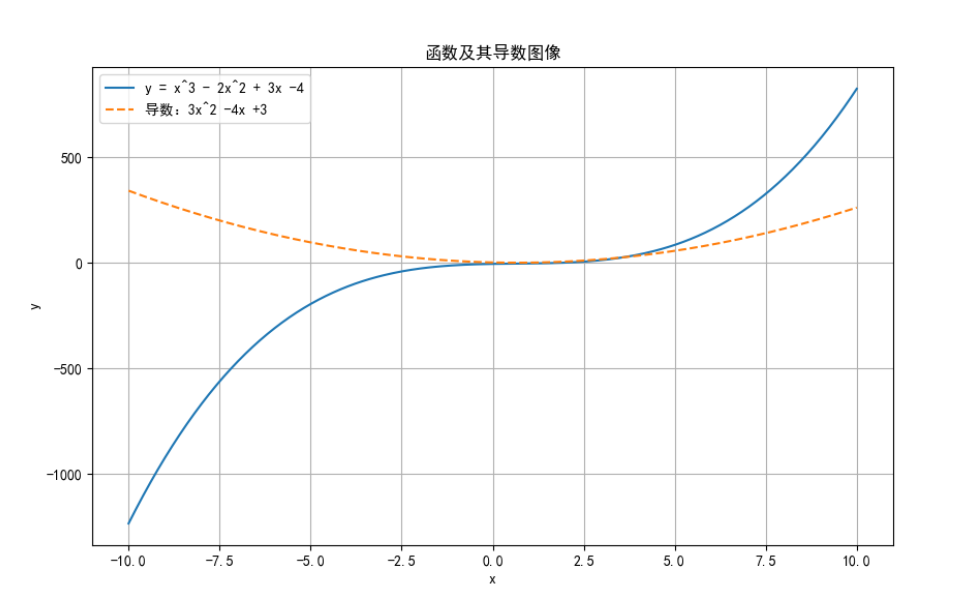
1.2 线性代数
线性代数是研究向量、向量空间(或称线性空间)、线性变换和有限维线性方程组的理论,在人工智能中,数据通常以向量或矩阵的形式表示,因此线性代数的应用非常广泛。
1.2.1 向量和矩阵
-
向量 :一个有序的数值序列,可以表示数据的特征。例如,在图像识别中,一张图片可以表示为一个向量,其中每个元素代表一个像素的灰度值。
-
矩阵 :由 m×n 个数排列成的 m 行 n 列的数表。在机器学习中,数据集通常可以表示为一个矩阵,其中每一行代表一个样本,每一列代表一个特征。
1.2.2 范数和内积
-
范数 :用于衡量向量的大小或长度。常见的范数有 L1 范数(曼哈顿距离)和 L2 范数(欧几里得距离)。在机器学习中,范数常用于正则化,以防止模型过拟合。
-
内积 :两个向量之间的点积,用于衡量向量之间的相似性。如果两个向量的内积为零,则它们正交。在自然语言处理中,通过计算词向量之间的内积,可以判断词义的相似性。
1.2.3 线性变换
线性变换是指将一个向量空间映射到另一个向量空间的变换,且保持向量的加法和数乘运算。例如,矩阵乘法可以表示一种线性变换,在图像处理中,通过矩阵乘法可以实现图像的旋转、缩放等变换。
1.2.4 特征值和特征向量
对于一个矩阵 A,如果存在一个非零向量 x 和一个标量 λ,使得 Ax = λx,则 λ 称为矩阵 A 的特征值,x 称为对应的特征向量。在主成分分析(PCA)等降维算法中,通过求矩阵的特征值和特征向量,可以找出数据的主要特征方向,从而降低数据的维度。
1.2.5 奇异值分解
奇异值分解(SVD)是一种矩阵分解方法,将一个矩阵分解为三个矩阵的乘积。它在推荐系统、图像压缩等领域能够广泛应用。例如,在推荐系统中,通过 SVD 可以对用户 - 物品矩阵进行分解,挖掘用户的潜在兴趣,从而实现个性化推荐。
Python 求解示例
对矩阵 A=[[1, 2], [3, 4]] 进行奇异值分解。
import numpy as np# 定义矩阵
A = np.array([[1, 2], [3, 4]])# 奇异值分解
U, sigma, VT = np.linalg.svd(A)print("矩阵 U:\n", U)
print("\n奇异值 sigma:\n", sigma)
print("\n矩阵 VT:\n", VT)
1.3 概率论
概率论是研究随机现象数量规律的数学分支,在人工智能中,许多问题都涉及到不确定性,如数据噪声、模型预测的不确定性等,概率论为我们提供了处理这些问题的工具。
基本概念
-
概率 :表示一个事件发生的可能性大小,取值范围在 0 到 1 之间。
-
概率分布 :描述随机变量取值的概率规律。常见的概率分布有二项分布、正态分布等。在机器学习中,数据通常假设服从某种概率分布,通过估计分布的参数,可以对数据进行建模。
应用
-
贝叶斯定理 :在机器学习中,贝叶斯定理用于计算后验概率,是贝叶斯分类器等算法的基础。例如,在垃圾邮件分类中,通过贝叶斯定理计算一封邮件是垃圾邮件的概率,从而实现分类。
Python 求解示例
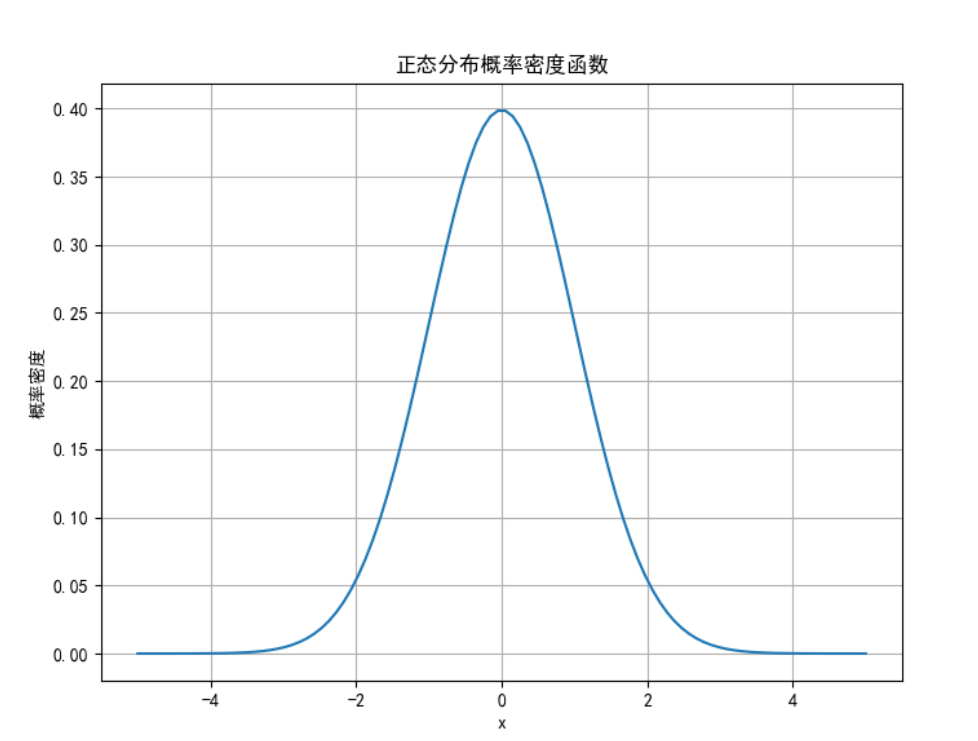
计算正态分布的概率密度函数,并绘制图像。
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import normplt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 定义正态分布参数
mu = 0 # 均值
sigma = 1 # 标准差# 计算概率密度函数
x = np.linspace(-5, 5, 100)
y = norm.pdf(x, mu, sigma)# 绘制图像
plt.figure(figsize=(8, 6))
plt.plot(x, y)
plt.xlabel('x')
plt.ylabel('概率密度')
plt.title('正态分布概率密度函数')
plt.grid(True)
plt.show()
1.4 数理统计
数理统计是研究如何通过对随机样本的观察和分析,来推断总体的分布和特征的数学分支。在人工智能中,我们通常只有有限的样本数据,通过数理统计方法,可以从样本推断总体,从而对数据进行建模和分析。
基本概念
-
样本均值 :样本数据的平均值,用于估计总体均值。
-
样本方差 :衡量样本数据的离散程度,用于估计总体方差。
应用
-
假设检验 :在模型评估中,通过假设检验可以判断模型的性能是否显著优于基线模型。例如,比较两种不同机器学习算法在测试集上的准确率,判断是否存在显著差异。
-
置信区间估计 :用于估计模型参数的取值范围。例如,在线性回归中,通过置信区间估计回归系数的取值范围,了解模型参数的不确定性。
Python 求解示例
计算一组样本数据的均值和方差,并进行 t 检验(假设总体均值为 0)。
import numpy as np
from scipy import stats# 生成样本数据
np.random.seed(0)
data = np.random.randn(100) # 生成 100 个服从标准正态分布的随机数# 计算样本均值和方差
mean = np.mean(data)
var = np.var(data, ddof=1) # ddof=1 表示无偏估计print("样本均值:", mean)
print("样本方差:", var)# t 检验(假设总体均值为 0)
t_stat, p_val = stats.ttest_1samp(data, 0)print("\nt 检验统计量:", t_stat)
print("p 值:", p_val)
1.5 最优化理论
最优化理论是研究如何寻找函数的最小值或最大值的数学分支。在人工智能中,最优化方法用于训练模型,通过最小化损失函数,使模型的预测结果尽可能接近真实值。
1.5.1 目标函数
目标函数是我们希望优化的函数,通常是损失函数,如均方误差(MSE)、交叉熵损失等。在机器学习中,通过调整模型参数,使目标函数达到最小值,从而得到最优的模型。
1.5.2 线性规划
线性规划是一种最优化方法,用于在满足线性约束条件下,求线性目标函数的最小值或最大值。在资源分配、生产调度等领域有广泛应用。在人工智能中,线性规划可以用于解决一些简单的分类问题,如线性可分支持向量机。
1.5.3 梯度下降法
梯度下降法是一种基于梯度的最优化算法,通过沿着梯度方向更新参数,逐步逼近目标函数的最小值。在深度学习中,梯度下降法及其变种(如随机梯度下降、Adam 等)是训练神经网络的核心算法。
Python 求解示例
使用梯度下降法优化函数 f(x) = x^2 + 2x +1,并绘制优化过程。
import numpy as np
import matplotlib.pyplot as pltplt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False# 定义函数及其导数
def f(x):return x**2 + 2*x +1def df(x):return 2*x +2# 梯度下降法
x = 5 # 初始点
learning_rate = 0.1
iterations = 20
x_history = [x]for _ in range(iterations):grad = df(x)x = x - learning_rate * gradx_history.append(x)# 绘制图像
x_vals = np.linspace(-5, 5, 400)
y_vals = f(x_vals)plt.figure(figsize=(10, 6))
plt.plot(x_vals, y_vals, label='f(x) = x^2 + 2x +1')
plt.scatter(x_history, [f(x) for x in x_history], color='red', zorder=5)
plt.xlabel('x')
plt.ylabel('f(x)')
plt.title('梯度下降法优化过程')
plt.legend()
plt.grid(True)
plt.show()print("优化后的 x 值:", x)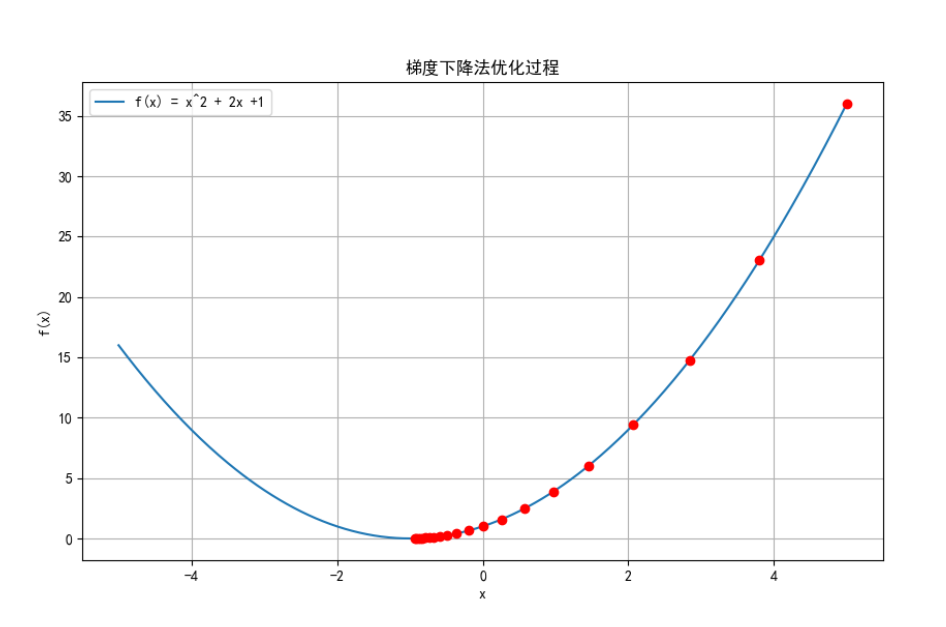
通过以上对人工智能数学基础的介绍和 Python 求解示例,我们可以看到数学在人工智能中的重要性。掌握这些数学知识,有助于我们更好地理解和应用人工智能算法。在实际学习和工作中,我们可以多进行代码实践,加深对数学知识的理解和应用能力。资源绑定附上完整资源供读者参考学习!