MySQL-存储引擎和索引
1.MySQL的基础架构是什么?
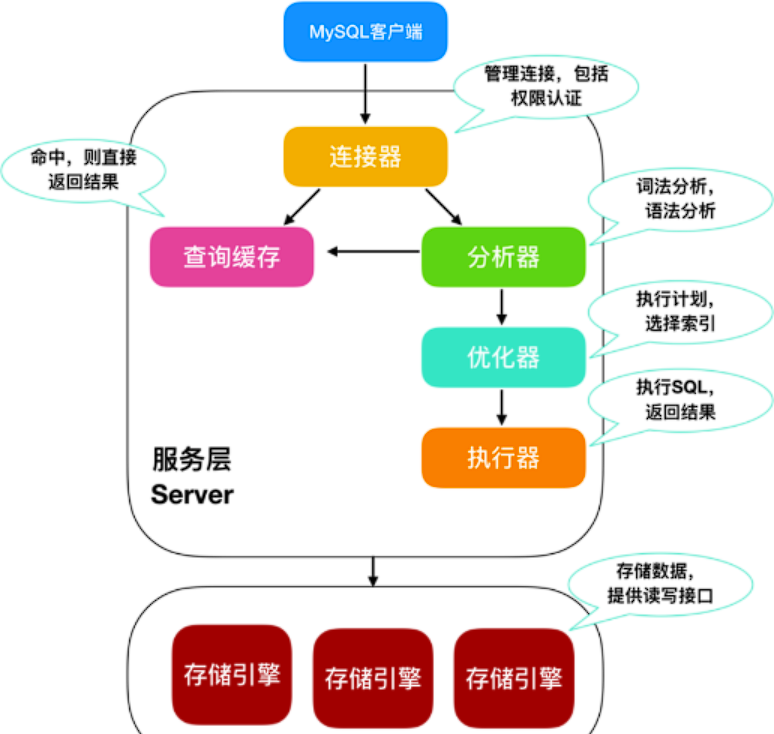
MySQL由连接器、分析器、优化器、执行器和存储引擎这五部分构成。
一条SQL的执行流程:
- 通过
连接器连接数据库,检查用户名和密码,以及权限校验,是否有增删改查的权限。 - 在MySQL8.0之前,连接完数据库后会先判断缓存是否有数据,如果执行过这个SQL语句,直接返回。8.0之后没有了缓存,直接进入
分析器,进行词法分析判断执行的什么操作,语法分析检查语句是否存在问题。 - 进入
优化器,选择合适的索引以及查询的顺序,由优化器指定执行计划。 - 进入
执行器之前先进行权限校验,权限信息是从连接器中取出来的,权限没问题就开始执行。 - 最后由存储引擎负责读写数据,MySQL默认的存储引擎是
InnoDB,采用Buffer Pool来减少对磁盘的直接I/O,并通过redo log和undo log来保证事务的持久性和原子性。
SQL语句的执行顺序是From子句返回初始结果集,WHERE子句排除不满足条件的行,GROUP BY子句进行分组,HAVING子句排除不满足条件的组,最后经过ORDER BY子句对结果集进行排序。
2.MySQL中有哪些存储引擎?
MySQL中的存储引擎是插件式的,可以为不同的数据库表设置不同的存储引擎。主要有四种存储引擎,InnoDB、MyISAM、Memory和Archive。
- InnoDB是支持
事务完整的ACID特性的,MyISAM、Memory和Archive都不支持事务。 - InnoDB和Archive采用的是
行级锁,而MyISAM和Memory采用的是表级锁。 - InnoDB支持
外键,保证数据的完整性,而其它的存储引擎都不支持外键。 - InnoDB通过
redo log和undo log来实现崩溃后的自动恢复,其他几种存储引擎不支持崩溃后的自动恢复。 - InnoDB的
存储方式是数据与索引一体,MyISAM是数据与索引分离。Memory存储在内存,Archive进行压缩存储。 - InnoDB主要用于高并发的场景下,MyISAM适合静态读,Memory适合存放临时数据,Archive存放归档数据。
3.什么是MySQL索引?
创建索引的目的就是加快检索速度,但是维护索引需要耗费性能。
- MySQL索引默认采用的数据结构是
B+树,B+树的数据全部存放在叶子节点上,这样就可以组织更宽的树,树高就会降低,减少磁盘I/O。 - B+树采用
双向链表,非常适合范围查询和排序。
4.什么是二级索引(非聚簇索引)?
非聚簇索引就是非主键做为索引,可以有多个,叶子节点存放的是主键值。
5.什么是聚簇索引?
聚簇索引就是将主键做为索引,只能有一个,叶子节点存放的是整行数据。如果表中没有主键,默认使用唯一字段做为索引,如果没有唯一字段就采用隐藏字段rowid做为索引。
6.什么是回表查询?
回表查询就是通过非聚簇索引找到主键值,再通过聚簇索引找到对应的数据。非聚簇索引不一定回表查询,比如查询用户名,用户名正好建立了索引,直接返回就可以。
7.什么是覆盖索引?
覆盖索引就是查询使用了索引,返回的字段必须在索引中全部找到。覆盖索引查询就是一次性查询,不需要回表查询。如果我们使用主键进行查询,那么就会采用聚簇索引返回所有字段的数据,这就是覆盖索引查询。
8.什么是联合索引?
联合索引就是多个字段创建的索引,相比于单列索引,每个索引对应一颗B+树,而联合索引只需要一颗B+树。最左匹配原则就是在使用联合索引时,MySQL会按照字段的顺序,从左到右依次查询字段。需要注意的是,如果查询条件中存在范围查询,从这个范围列开始就不会继续向后匹配索引了。我们在使用联合索引的时候,将区分度最高的字段放到左边,这样可以过滤更多的数据。
9.如何选择合适的字段创建索引?
- 选择
不为NULL的字段 - 选择
查询频繁的字段 - 选择做为
查询条件的字段 - 选择频繁排队的字段
10.什么情况下索引会失效?
- 组合索引未遵循
最左匹配原则 - 索引上进行
计算、类型转换等操作 - 使用%开头的LIKE模糊查询
- 查询条件
使用OR但是有一列没有索引