高阶数据结构 图 (上)
目录
前言
什么是图
图的存储结构
邻接矩阵
邻接表
图的遍历
BFS
DFS
结语

前言
这篇博客,我们只会讲讲图是什么,图的存储结构,也就是邻接表和临界矩阵,最后我们再谈谈图的遍历,BFS 和 DFS
剩下的五个算法,两个最小生成树,三个最短路径算法,这里打算在后面分成两篇文章来写,这篇文章就不做展开了
什么是图
首先我们要知道的是,图是一种偏现实的东西,他分为了边和节点,而每一条边都有对应的权值
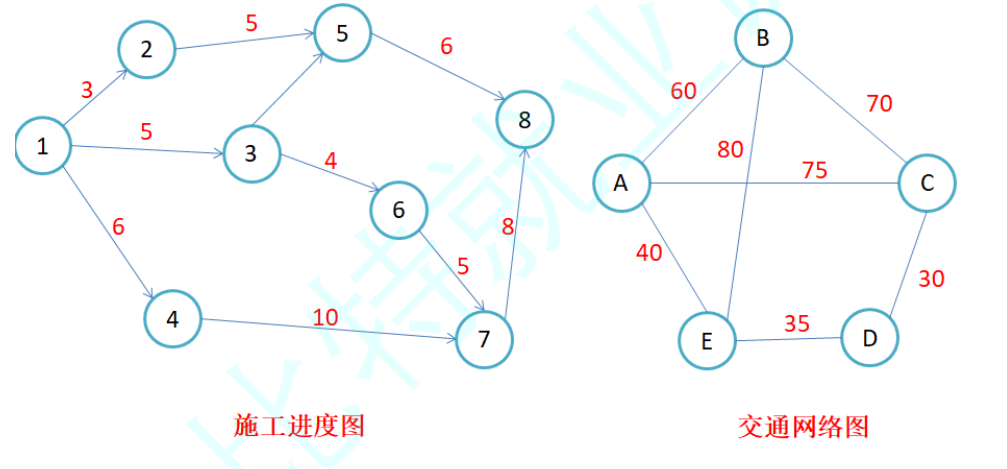
如上就是两张图,我们可以想象这是一个城市的交通规划图,比如从点 A 到点 B 要多少钱,从点 1 修一条铁路到点 2 要多少预算之类的,这就是图
图的表现形式就像上图这样,节点自不必多说,至于边,就是将两个节点链接起来的部分
但是在图中,我们不只单单有边的权值,我们的边其实也是有方向的
我们看到左边的图,上面有着箭头,比如我们从点 1 可以到达点 2,但是 2 没法到达 1,这个也叫做有向图
但是右边的图就不一样了,我们可以看到上面是没有方向标识的,没有箭头,也就代表这是互通的,也就是 A 能到 B,反之亦然
最后我们再来讲三个概念,连通图,强连通图,以及生成树
首先连通图是,对于无向图来说,只要每一个点 A 和点 B 联通起来,有路径能到达另一个点,同时对于任意一对顶点来说,如果都满足这个条件的话,那么我们就这是一个连通图
而强连通图只是对有向图而言,就是每两个点都有互通的路径,那么就是强连通图
需要注意的是,两个顶点之间的联通不一定是这两个顶点必须互相连接,我们可以从其他路径绕到另一个点也是算作联通的
最后是生成树,我们的生成树其实概念和连通图差不多,连通图的最小联通子图就是生成树,说简洁点就是:能把每一个互通起来的,就是生成树
而我们的每一条边都有对应的权重,我们通过选取不同的边,将所有的点连起来也是有讲究的,这就是最小生成树算法,里面有两个赫赫有名的算法:克鲁斯卡尔 和 普利姆
(Kruskal)(Prim)
图的存储结构
我们的图,是一种抽象出来的结构,这种结构是需要落实到 vector 上的
所以就有了两种图的存储结构,一个是邻接矩阵,还有一个就是邻接表
但是需要注意到是,这两个都是用来存储边的,节点我们会单独开一个数组存储
邻接矩阵
其实这就是一个二维矩阵,只不过叫做邻接听起来高级
而我们的边又分为有向和无向,所以,我们的二维矩阵也需要用一种方法存储带有方向的边
由于每个位置都带有下标,所以像 1、2 这种,就存储着从 1 指向 2 这条边的权重,反之,就是 2、1,从 2 指向 1 的边的权重,如下示例:
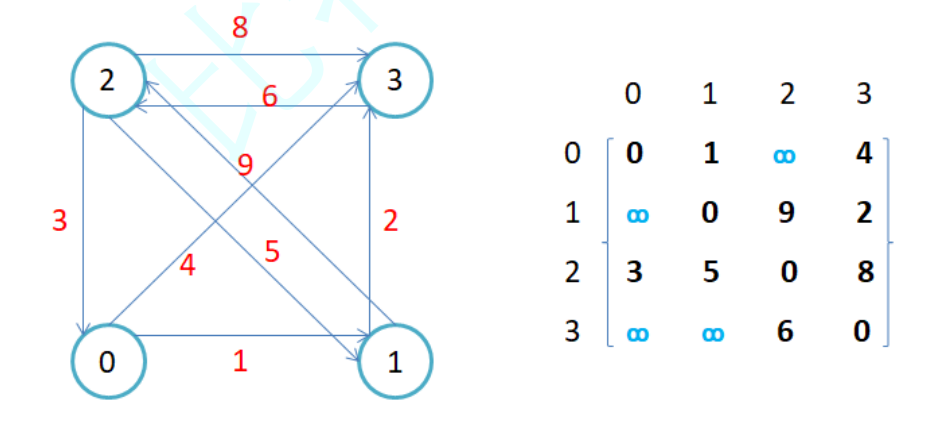
邻接矩阵主要的成员就三个,当然也可以是两个,因为我们不确定,我们节点的值是整数与否,可能是城市名?地址?或者是别的,所以我们可以加上一个map,或者哈希表都可以,专门用来映射节点和下标,还有就是专门用来存储节点的数组,最后是用来存储边的二维矩阵,也就是邻接矩阵
构造函数就不说了,全是用的 reserve 和 resize 对成员进行初始化
最主要的就一个,那就是加边(就是将边存储在邻接矩阵的过程)
其实很简单,就是拿出节点对应的下标,然后将下标与下标之间的值存入矩阵中即可,只不过我们还需要判断一下是否是无向,如果是无向的话,我们就顺便将反方向的也初始化了
比如我现在有一个 1->2,那我的加边逻辑就是,先将矩阵中下标为1、2 的位置变成边的权重,然后判断是否是无向,如果无向就意味着我要将 2->1 顺便改了
综上,邻接矩阵代码如下:
template<class V, class W, W MAX_W = INT_MAX, bool Direction = false>
class Graph
{typedef Graph<V, W> Self;
public:Graph() = default;Graph(const V* a, size_t n){_vertexs.reserve(n);for (size_t i = 0; i < n; i++){_vertexs.push_back(a[i]);_indexMap[a[i]] = i;}_matrix.resize(n);for (auto& e : _matrix){e.resize(n, MAX_W);}}void _AddEdge(size_t srci, size_t dsti, const W& w){_matrix[srci][dsti] = w;if(!Direction) _matrix[dsti][srci] = w;}void AddEdge(const V& src, const V& dst, const W& w){size_t srci = _indexMap[src];size_t dsti = _indexMap[dst];_AddEdge(srci, dsti, w);}private:vector<V> _vertexs;map<V, int> _indexMap;vector<vector<W>> _matrix;
};邻接表
对比邻接矩阵,邻接表更适合直接找边的情况,因为邻接表的本质就是一个指针数组
也就是 vector<Edge*> LinkTable
Edge 就是我们另外写的一个类,里面是开始节点,结束节点,边的权重,以及指向下一条边的指针
在邻接表中我们是这样存储边的,如下:
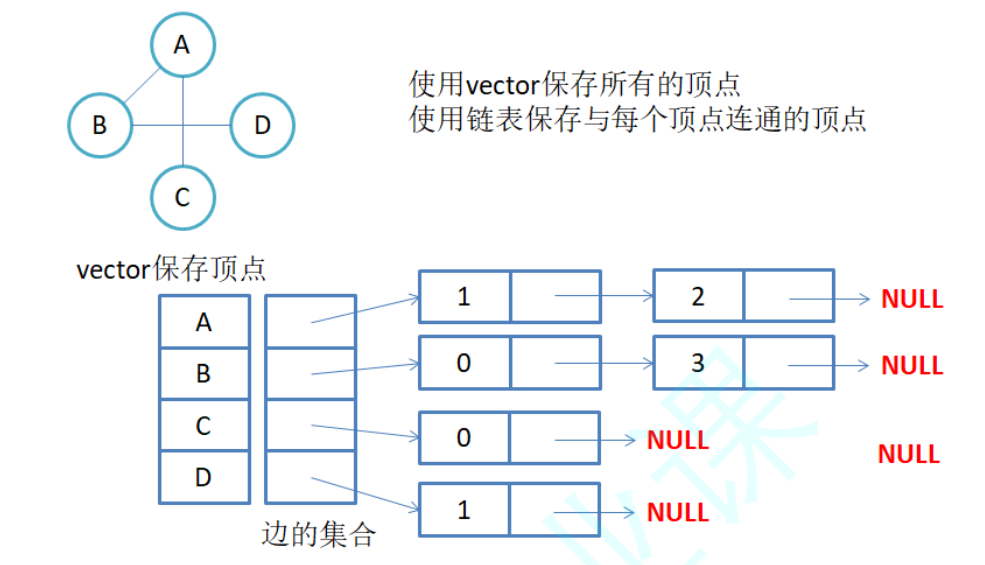
如上,我们的 A 能够到达 B、C,所以我们在 A 对应下标位置就存上 A->B,A->C 这两条边,其他都是这样
虽然同时存储了这么多边,但是顺序并没有讲究,所以为了效率,我们后续在代码中的表现就是头插,因为尾插还要找尾,效率低
最后就是代码实现了,我们主要的成员还是有三个,和邻接矩阵一样,一个用来存节点,一个用来存节点和下标的映射,最后一个就是邻接表本身了
vector<V> _vertexs; // 顶点集合
map<V, int> _indexMap; // 顶点映射下标
vector<Edge*> _tables; // 邻接表
而且和邻接矩阵一样,除了构造函数之外,就只有一个最重要的函数了,那就是加边
构造函数就不说了,就是初始化三个数组的工作
最重要的是加边函数
首先我们现在有了一条新的边要加入进来,那么我们就应该先new一个节点,然后将这个节点里面的值给初始化了,最后头插即可
最后就判断一下是否是有向图,因为有向意味着反方向我们也可以在这时插入
最后就是,我们的Edge中不一定要有开始节点,因为我们在插入边的时候会要求将开始节点作为参数,这样我们才知道要从哪里开始插入新的边,而既然我们以及有了开始节点的位置,我们插入到邻接表中之后,就自然知道是从哪里开始的了
代码如下:
namespace link_table
{template<class W>struct Edge{//int _srci;int _dsti; // 目标点的下标W _w; // 权值Edge<W>* _next;Edge(int dsti, const W& w):_dsti(dsti), _w(w), _next(nullptr){}};template<class V, class W, bool Direction = false>class Graph{typedef Edge<W> Edge;public:Graph(const V* a, size_t n){_vertexs.reserve(n);for (size_t i = 0; i < n; ++i){_vertexs.push_back(a[i]);_indexMap[a[i]] = i;}_tables.resize(n, nullptr);}void AddEdge(const V& src, const V& dst, const W& w){size_t srci = _indexMap[src];size_t dsti = _indexMap[dst];// 1->2Edge* eg = new Edge(dsti, w);eg->_next = _tables[srci];_tables[srci] = eg;// 2->1if (Direction == false){Edge* eg = new Edge(srci, w);eg->_next = _tables[dsti];_tables[dsti] = eg;}}private:vector<V> _vertexs; // 顶点集合map<V, int> _indexMap; // 顶点映射下标vector<Edge*> _tables; // 邻接表};}图的遍历
图一共有两种遍历方式,一种是宽度优先,一种是深度优先,其实就是 BFS 和 DFS
BFS
宽度优先的遍历方式如下
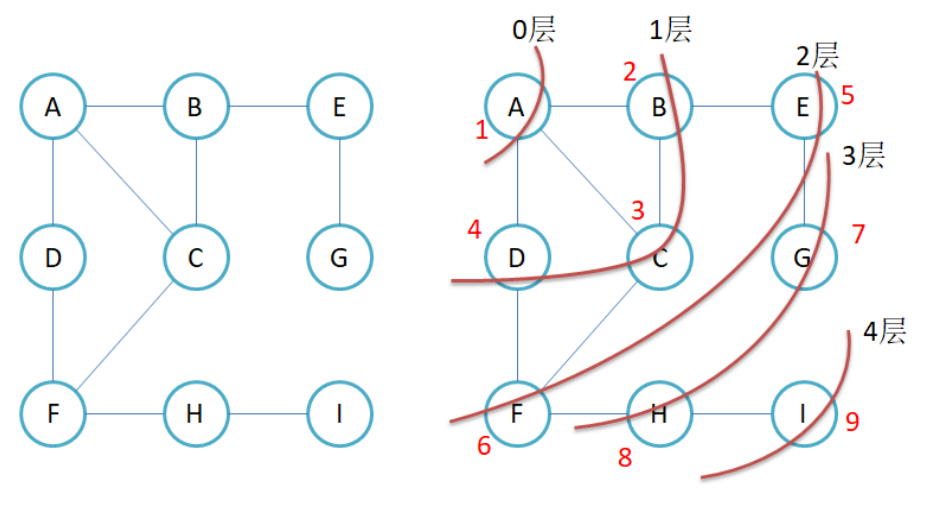
其实非常简单,创建一个队列,我们找到一个节点之后,就将其相连的所有节点放进队列里面,这里我们用邻接矩阵,因为他代码好写
而在邻接矩阵中,我们要找到相连的节点,其实就是以及知道了起始位置,我们遍历一遍那一行就好了,如果那个位置为INT_MAX的话,那就意味着这个位置是没有边的
所以整体的思路如上,就是找到一个位置之后,将其链接的位置全部加进队列中,然后我们只用判断队列是否为空即可
但是这样有两个问题
第一个是,我们如果遍历完 1->2 之后,我们到了 2 位置的时候,2->1 还会在遍历一遍,所以我们需要特判一下防着这种情况,对于这种情况,我们可以再创建一个数组专门用来判断这个位置有没有被遍历过
第二个是,我们遍历也是有目的的,如果我们要找对应第几层的节点呢?所以我们可以加一个for循环在这个逻辑里面,这样,我们每遍历一层,我们就将对应的新加入的节点数量记录下来,那么我们每进行一次for循环,就代表我们遍历多了一层
代码如下:
void BFS(const V& src){size_t srci = _indexMap[src];size_t n = _vertexs.size();queue<int> q;vector<bool> vis(n, 0);int levelsize = 1;while (!q.empty()){for (size_t i = 0; i < n; ++i) {int front = q.front();q.pop();cout << front << ":" << _vertexs[front] << " ";for (int j = 0; j < n; j++){if (_matrix[front][j] != MAX_W && !vis[j]){q.push(j);vis[j] = true;}}}cout << endl;levelsize = q.size();}}DFS
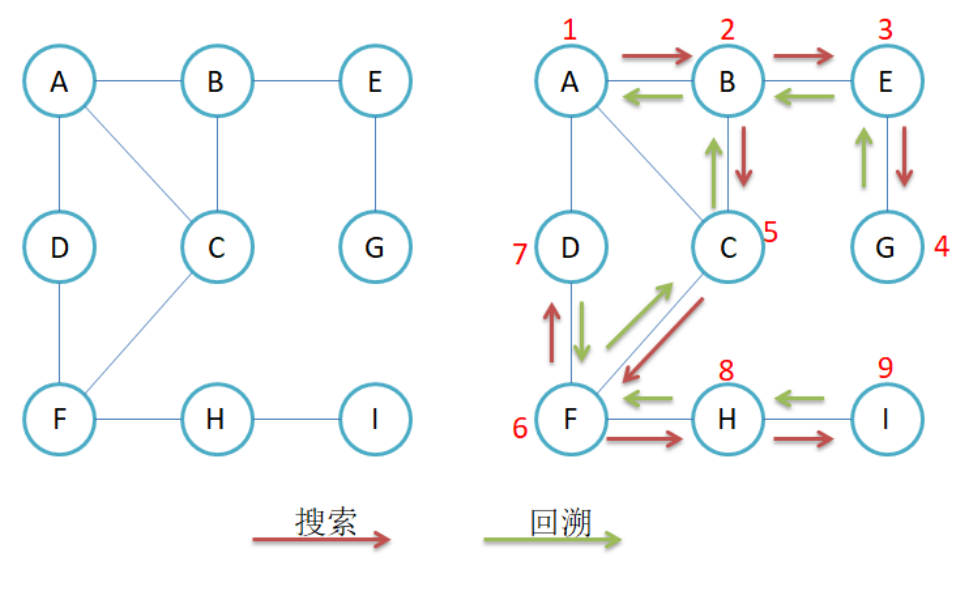
其实就是递归,我们每找到一个节点之后,我们就对着他链接的节点进行更进一步的遍历即可
就这样了,相当简单,如果我们要防止有向的重复遍历的情况的话,用一个数组标记一下,最后特判即可,如果要层数的话,放一个参数 pos 进去代表层数即可(下面就不写了)
代码如下:
void _DFS(size_t srci, vector<bool>& vis){cout << srci << ":" << _vertexs[srci] << endl;vis[srci] = true;for (int i = 0; i < _vertexs.size(); i++){if (_matrix[srci][i] != MAX_W && !vis[i]){_DFS(i, vis);}}}void DFS(const V& src){size_t srci = _indexMap[src];vector<bool> vis(_vertexs.size(), false);_DFS(srci, vis);}结语
这篇文章到这里就结束啦!!~( ̄▽ ̄)~*
如果觉得对你有帮助的,可以多多关注一下喔