时间序列:A TIME SERIES IS WORTH 64 WORDS: LONG-TERM FORECASTING WITH TRANSFORMERS
ICLR 2023 PatchTST (※※※)
摘要:
我们提出了一种高效的 Transformer 模型设计,用于多变量时间序列预测和自监督表示学习。该设计基于两个关键组件:(i)将时间序列划分为子序列级别的 patch,这些 patch 被作为输入 token 提供给 Transformer;(ii)通道独立性,即每个通道仅包含一个单变量时间序列,所有序列共享相同的嵌入层和 Transformer 权重。这种 patch 划分设计具有三方面的自然优势:能够在嵌入中保留局部语义信息;在相同的回溯窗口下,注意力图的计算和内存开销呈二次减少;模型可以关注更长的历史信息。 我们提出的通道独立 patch 时间序列 Transformer(PatchTST)在长期预测准确率上相较于当前最先进(SOTA)的 Transformer 模型有显著提升。我们还将该模型应用于自监督预训练任务,并在微调阶段取得了优异表现,甚至优于在大型数据集上进行的有监督训练。将经过掩码预训练的表示从一个数据集迁移到另一个数据集时,也能达到最先进的预测准确度。
论文地址:https://arxiv.org/pdf/2211.14730
代码地址:https://github.com/PatchTST/PatchTST
总结:
很厉害,
论文看不出来有多厉害。论文的话,跟iTransformer很相似,但是PatchTST更早。个人感觉iTransformer模仿了他的通道独立的点,实际上就是处理序列seq_len。只不过减少了计算量 用了这个patch的方法。
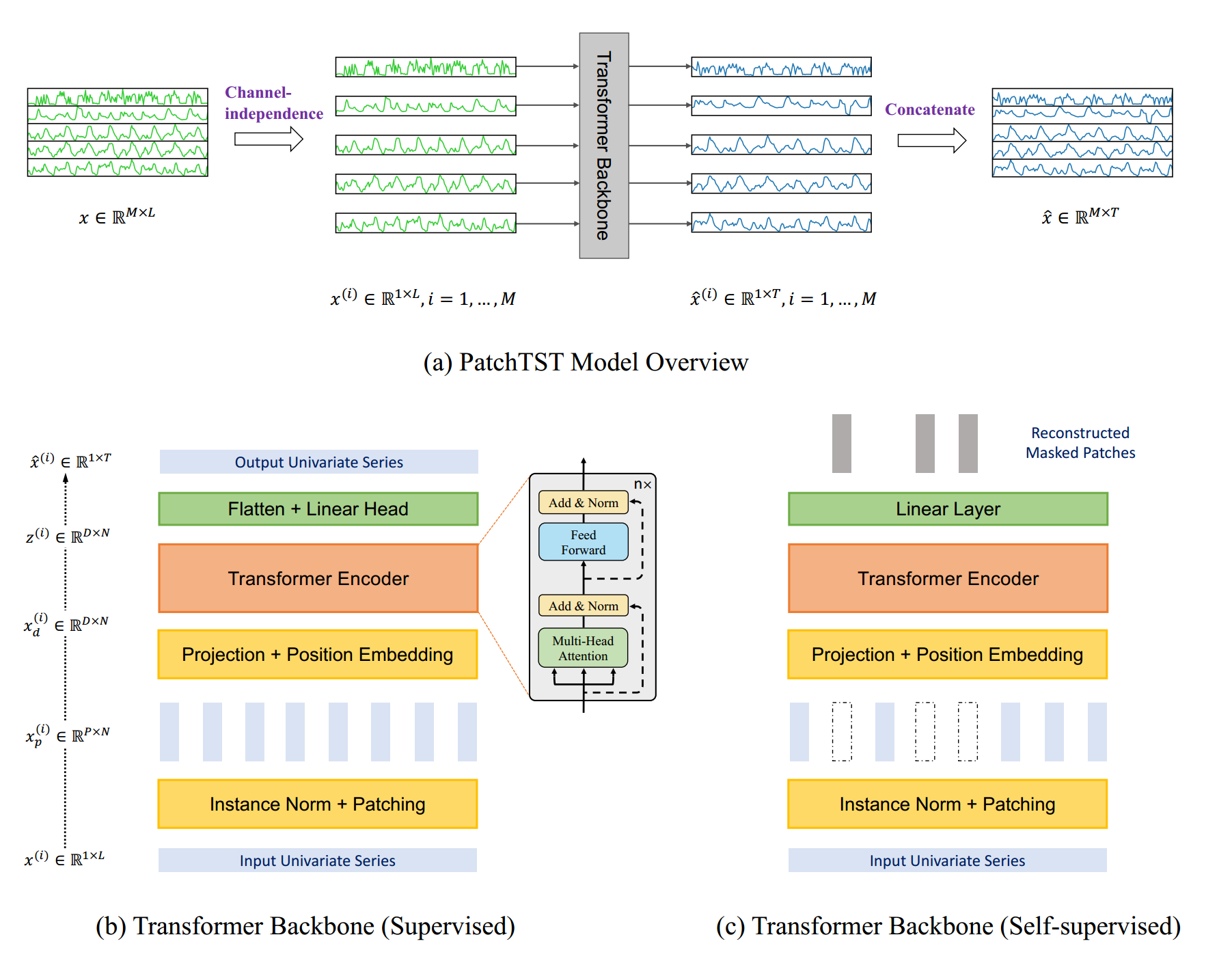 论文的结构也是比较清晰。 a图能看出来 这个方法是做的 通道独立。把每一维的时间数据通道隔开;b图就是对于每一个xi(第i个特征的输入)进行patch 变成 PxN(就是Patch-len * patch-Num) 这里的patch方式实现的也比较简单,然后进入后面的映射区和位置编码区,映射区的话实际上就是Linear 映射到d_model。 这里是把patch-len 映射为 d_model,然后进入transformer,最后进行flatten和linear head,实际上就是把 后两维 铺开,再linear 映射回 pred-len;c图的话就是利用自监督方式进行训练, 然后再通过微调 ,那预训练的话就需要把 后面的解码 换掉,换成输出掩码的 linear。
论文的结构也是比较清晰。 a图能看出来 这个方法是做的 通道独立。把每一维的时间数据通道隔开;b图就是对于每一个xi(第i个特征的输入)进行patch 变成 PxN(就是Patch-len * patch-Num) 这里的patch方式实现的也比较简单,然后进入后面的映射区和位置编码区,映射区的话实际上就是Linear 映射到d_model。 这里是把patch-len 映射为 d_model,然后进入transformer,最后进行flatten和linear head,实际上就是把 后两维 铺开,再linear 映射回 pred-len;c图的话就是利用自监督方式进行训练, 然后再通过微调 ,那预训练的话就需要把 后面的解码 换掉,换成输出掩码的 linear。
明天总结代码部分。