从代码学习深度学习 - 小批量随机梯度下降 PyTorch 版
文章目录
- 前言
- 一、数据准备与处理
- 1.1 数据集简介
- 1.2 数据加载与预处理
- 二、训练工具与辅助类
- 三、可视化工具
- 四、模型训练
- 五、执行训练
- 总结
前言
深度学习是人工智能领域的核心技术之一,而小批量随机梯度下降(Mini-Batch Stochastic Gradient Descent, SGD)是训练神经网络的基石算法。本文将通过一个完整的 PyTorch 实现,带你深入理解小批量 SGD 的工作原理。我们以 NASA 的 Airfoil Self-Noise Dataset 为例,展示如何使用 PyTorch 构建数据加载器、定义模型、训练神经网络,并可视化训练过程。
小批量随机梯度下降公式: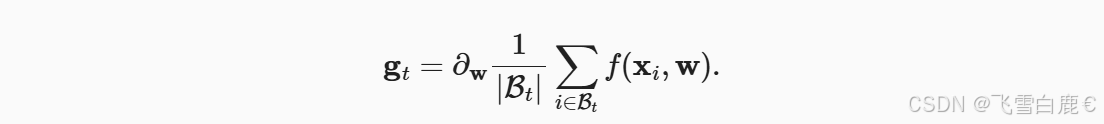
本文的目标是通过代码逐步解析深度学习的核心组件,帮助初学者从实践中掌握理论知识。所有代码均来自附件,涵盖数据处理、训练工具、可视化工具和主训练逻辑。让我们开始吧!
完整代码:下载链接
一、数据准备与处理
1.1 数据集简介
我们使用的是 Airfoil Self-Noise Dataset,一个用于回归任务的经典数据集,来自 UCI 机器学习库。它包含 1503 条记录,每条记录有 5 个输入特征和 1 个目标变量(缩放后的声压级,单位为分贝)。特征包括:
- 声音频率(Frequency, Hz)
- 攻角(Angle of attack, degrees)
- 翼弦长度(Chord length, m)
- 来流速度(Free-stream velocity, m/s)
- 吸力面位移厚度(Suction side displacement thickness, m)
目标是预测给定气动参数下的声压级。
1.2 数据加载与预处理
以下代码(utils_for_data.py)实现了数据加载和预处理逻辑。它从 airfoil_self_noise.dat 文件中读取数据,进行标准化处理,并构造 PyTorch 数据迭代器。
import torch
from torch.utils import data
from torch.utils.data import TensorDataset, DataLoader
import numpy as npdef load_array(data_arrays, batch_size, is_train=True):"""构造一个PyTorch数据迭代器参数:data_arrays (tuple of tensors): 包含特征和标签的张量,通常为 (X, y),其中X 维度: (样本数, 特征数)y 维度: (样本数, 1) 或 (样本数,)batch_size (int): 批量大小,决定每次迭代返回的样本数量is_train (bool): 是否为训练模式,若为True则打乱数据返回:DataLoader: PyTorch数据加载器,每次迭代返回一个批次,批次中的X维度: (batch_size, 特征数)批次中的y维度: (batch_size, 1) 或 (batch_size,)"""dataset = data.TensorDataset(*data_arrays) # 创建数据集,将多个张量组合成一个数据集return data.DataLoader(dataset, batch_size, shuffle=is_train) # 返回数据加载器,控制批次大小和是否打乱def get_data(batch_size=10, n=1500):"""获取气动翼型自噪声数据集并构造数据迭代器参数:batch_size (int): 批量大小n (int): 使用的样本数量,默认为1500返回:data_iter: 数据迭代器,每次返回一个批次的数据input_size: 特征维度数量"""# 从本地文件加载数据,维度: (总样本数, 特征数+1)data = np.genfromtxt('airfoil_self_noise.dat', dtype=np.float32, delimiter='\t')# 数据标准化处理,维度保持: (总样本数, 特征数+1)data = torch.from_numpy((data - data.mean(axis=0)) / data.std(axis=0))# 构造数据迭代器# data[:n, :-1] 维度: (n, 特征数),选取前n个样本的所有特征# data[:n, -1] 维度: (n,),选取前n个样本的标签data_iter = load_array((data[:n, :-1], data[:n, -1]),batch_size, is_train=True)# 返回数据迭代器和特征维度# data.shape[1]-1 为特征数量(减去标签列)return data_iter, data.shape[1]-1
代码解析:
load_array:将特征和标签张量封装成TensorDataset,并通过DataLoader提供批量数据加载功能,支持训练时的随机打乱。get_data:加载数据集,标准化数据(零均值、单位方差),并返回数据迭代器和特征维度(5)。
二、训练工具与辅助类
为了支持训练过程,我们需要一些辅助工具,包括计时器、累加器、GPU 检查函数和损失评估函数。这些工具定义在 utils_for_train.py 中。
import time
import torch
import torch.nn as nn
import numpy as np
import utils_for_huitu # 这个是你自己的工具包class Timer:"""记录多次运行时间"""def __init__(self):"""Defined in :numref:`subsec_linear_model`"""self.times = []self.start()def start(self):"""启动计时器"""self.tik = time.time()def stop(self):"""停止计时器并将时间记录在列表中"""self.times.append(time.time() - self.tik)return self.times[-1]def