PG,TRPO,PPO,GRPO,DPO原理梳理
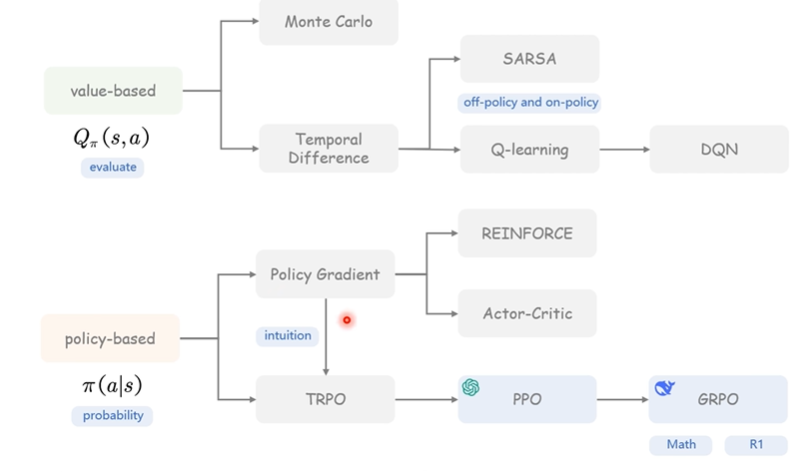
强化学习方法的分类
一、基础概念
-
Policy Model(Actor Model):根据输入文本,预测下一个token的概率分布,输出下一个token也即Policy模型的“动作”。该模型需要训练,是我们最终得到的模型,并由上一步的SFT初始化而来。
-
Value Model(Critic Model):用于预估当前模型回复的每一个token的收益。接着,还会进一步计算累积收益,累加每一个token的收益时不仅局限于当前token的质量,还需要衡量当前token对后续tokens生成的影响。这个累积收益一般是称为优势,用于衡量当前动作的好坏,也即模型本次回复的好坏,计算的方法一般使用GAE(广义优势估计,generalized advantage estimation))该模型同样需要训练
-
Reward Model:对Policy Model的输出整体进行打分,评估模型对于当前输出的即时收益。该模型训练过程不进行更新。
-
Reference Model:与 Policy Model是一样的模型,但在训练过程中不进行更新。其作用主要是与Policy Model计算KL散度(可以理解为两者的预测token概率分布差距)来作为约束,防止PolicyModel在更新过程中出现过大偏差,即每一次参数更新不要与Reference Model相差过于大。
二、PG(策略梯度)
策略梯度方法的核心思想是直接对策略函数(policy function)进行参数化,通过梯度上升(gradient ascent)的方法来优化策略参数,使得智能体在环境中获得的累积奖励最大化。
三、TRPO(Trust Region Policy Optimization)
在PG的基础上,加上了与参考模型的约束,限制策略的更新幅度。
优势函数 A(s,a) 衡量了在状态 s 下采取动作 a 相比于按照当前策略平均表现所能获得的额外奖励。

1.TRPO 在优化策略时加入了约束条件,即要求新旧策略之间的 KL 散度(衡量两个概率分布差异的指标)不超过某个阈值。
2.TRPO 的优化目标是在满足 KL 散度约束的条件下,最大化策略在优势函数下的期望值。它尝试在策略改进和策略变化幅度之间找到一个平衡,既让策略能够朝着获得更高奖励的方向更新,又不至于因更新幅度过大而破坏了策略的稳定性。
四、PPO(Proximal Policy Optimization)

PPO 的核心思想是在策略更新时,限制新旧策略之间的差异,防止更新幅度过大导致策略性能不稳定。为此,它提出了两种实现方式:PPO-penalty 和 PPO-clip。
PPO-penalty:在目标函数中添加了一个惩罚项,该惩罚项基于新旧策略之间的KL散度。
PPO-clip:对策略比率 进行裁剪,使其在 [1 - ϵ, 1 + ϵ] 范围内。这样可以限制新策略与旧策略的偏离程度,避免更新幅度过大。
TRPO 通过严格的数学推导来保证策略更新的稳定性,但其实现较为复杂,计算成本较高。因为不知道下一步的策略到底是什么。
PPO 则在保证策略更新稳定性的基础上,通过更简单的方式(惩罚项或裁剪策略比率)实现了类似的效果,同时提高了算法的效率和易用性。
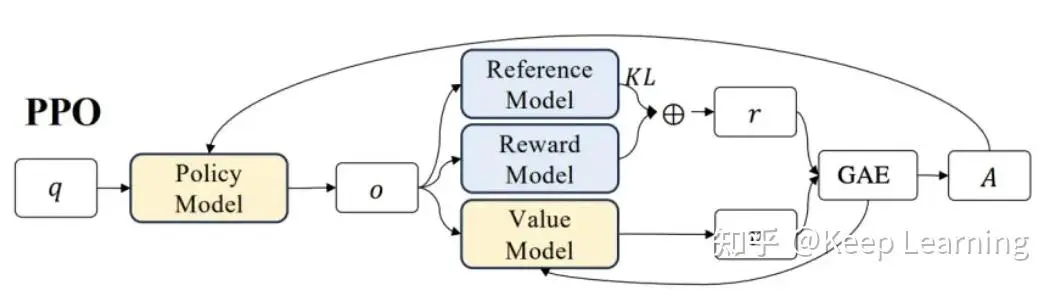
4.1 流程
-
采样动作:在当前状态sₜ下(即未更新前的策略模型π旧和价值模型V旧),对一个样本的提示q,使用策略模型(Actor Model)进行一次采样生成动作aₜ,即一次“动作”。
-
计算即时奖励:使用奖励模型计算动作aₜ的分数,同时计算参考模型与当前策略模型的KL散度,将两者结合起来作为即时奖励r。
-
计算当前收益:使用价值模型(Critic Model)来计算每一个token的收益,记为V旧。
-
计算优势A:根据即时奖励和后续tokens的分数影响,计算本次采样的优势(累积收益)。优势A结合了当前token的分数和后续tokens的影响。
-
策略更新比例:策略模型对q进行一次新的生成π(aₜ|sₜ),计算与旧策略π旧相比的更新比例:rₜ(θ)=π(aₜ|sₜ)/π旧(aₜ|sₜ)。
-
调整更新比例:当优势A>0时,表示本次采样的动作是正收益的(质量较好),尽量提升rₜ(θ);反之当A<0时,尽量降低rₜ(θ)。
-
裁剪更新比例:为了避免训练不稳定,对rₜ(θ)进行裁剪,上下限控制在一个合理范围内(类似梯度裁剪):Lclip(πθ)=E[min(rₜ(θ)Aₜ,clip(rₜ(θ),1−ε,1+ε)Aₜ)]。
-
更新值函数:价值模型对新的采样π(aₜ|sₜ)进行价值评估V新,并使其尽量靠近参考奖励R=A+V旧。同样进行裁剪:L(Vφ)=E[max[(V新−R)², (clip(V新,V旧−ε,V旧+ε)−R)²]]。
-
更新模型:使用两个损失函数分别更新策略模型πθ和价值模型Vφ。
-
完成本轮训练:循环步骤5-9,完成本轮PPO训练:用新的策略模型和价值模型替换旧的,即π旧←πθ,V旧←V新。
-
进入下一批次训练:使用更新后的策略模型和价值模型开始下一批次的训练。
4.2 广义优势估计(GAE)

在估计下一步策略时,并不知道下一步到底是什么,目前有蒙特卡洛和时序差分方法,前者对每一步进行模拟,后者走一步看一步。

GAE通过引入参数 λ,将不同步数的优势估计进行加权求和,从而在方差和偏差之间取得平衡。当 λ=0 时,GAE退化为单步时序差分估计;当 λ→1 时,GAE接近蒙特卡洛估计。通过调整 λ 的值,可以在降低方差和增加偏差之间进行权衡。

4.3 RM的训练

五、GRPO(Group Relative Policy Optimization)
GRPO 的核心思想是通过组内相对奖励来估计基线(baseline),从而避免使用额外的价值函数模型。

策略函数跟PPO-clip一样。
5.1 流程
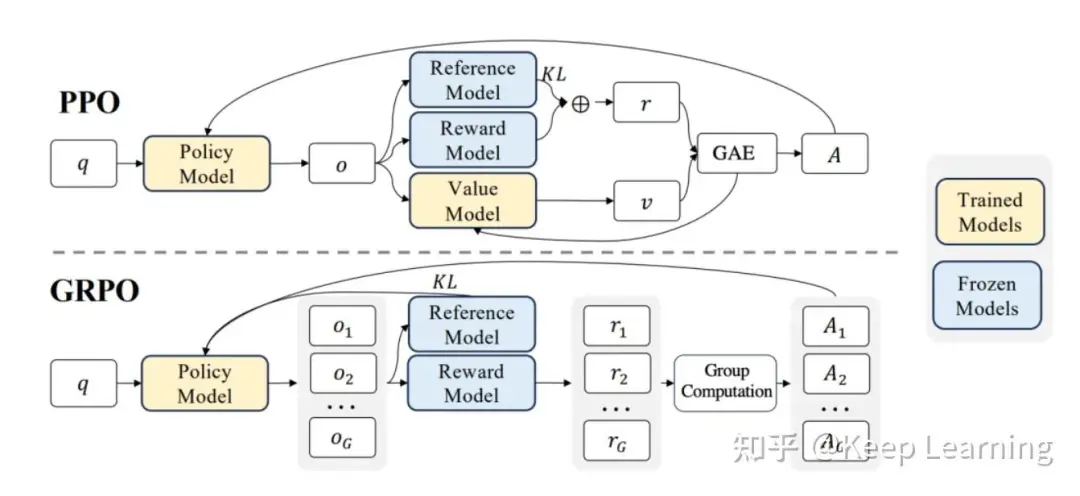
1.对一个样本的Prompt q,使用Policy Model进行G次生成
2.同样地,也进行G次生成,与Policy Model进行KL散度计算,KL散度可以理解为两者的预测token概率分布差距,跟其他方法都是类似作用,避免Policy Model训练不稳定
3.再使用Reward Model对Policy Model的这G次生成进行打分。参考DeepSeek-R1的做法,甚至可以不需要Reward Model,只需要奖励函数,比如代码问题,可以根据模型生成的代码是否能够运行,有标准答案的数学问题,从模型的生成中提取的答案是否正确,来给予一定的奖励分数
4.最后平均的KL散度和奖励分数作为Loss去更新Policy Model
六、DPO(Direct Preference Optimization)

- 训练数据是与上述奖励模型一样的偏好对数据。
- Policy Model的目标是尽量拉开chosen(preferred)样本与rejected(dispreferred)样本的token概率差距。
- 同时Policy Model的概率差距与Reference Model的概率差距不要太过于大,避免训练不稳定。
- Policy Model在DPO中,其实也是充当了Reward Model的角色,概率差可以认为是对应的应得奖励收益。

参考文献
【【大白话04】一文理清强化学习PPO和GRPO算法流程 | 原理图解】 https://www.bilibili.com/video/BV15cZYYvEhz/?share_source=copy_web&vd_source=29af710704ae24d166ca951b4c167d53
https://blog.csdn.net/Ever_____/article/details/139304624
https://mp.weixin.qq.com/s/UClxnbCMKP8IRa0OMWPPtw