深度学习3.6 softmax回归的从零开始实现
本章节引入3.5的数据集
import torch
from IPython import display
from d2l import torch as d2lbatch_size = 256 #迭代器批量
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
3.6.1 初始化模型参数
num_inputs = 784 # 权重矩阵长度
num_outputs = 10 # 类别数量
W = torch.normal(0, 0.01, size=(num_inputs, num_outputs), requires_grad=True) # 权重矩阵
b = torch.zeros(num_outputs, requires_grad=True) # 偏置
图像尺寸28*28像素
权重W:从均值为0、标准差0.01的正态分布采样,形状 [784, 10]。
偏置b:初始化为全0,形状 [10]。
梯度追踪:requires_grad=True 启用自动微分。
3.6.2 定义softmax操作
def softmax(X):X_exp = torch.exp(X) # 处理计算自然指数函数e的幂(GPU计算效率高)partition = X_exp.sum(1, keepdim=True) # 0:列,1:行,计算为x行1列张量return X_exp / partition # 归一化-概率[[1/3,2/3],[3/7,4/7]]X = torch.normal(0, 1, (2, 5)) # torch.normal 用于生成服从正态分布(高斯分布)的随机数张量,支持多种参数形式(均值,标准差,(形状))
X_prob = softmax(X) # 概率
X_prob, X_prob.sum(1) # 概率和=1
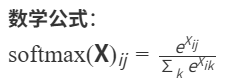
3.6.3 定义模型
def net(X):a1 = X.reshape((-1, W.shape[0])) # 保持[*,len(W)]a2 = torch.matmul(a1, W) # torch.matmul矩阵乘法return softmax(a2 + b) # 返回对应概率
展平输入:X.reshape((-1, 784))(将 [batch_size,1,28,28] 转为 [batch_size,784])。
线性变换:XW+b(输出 [batch_size,10])。
Softmax归一化:得到每个类别的概率分布。
3.6.4 定义损失函数
y = torch.tensor([0, 2])
y_hat = torch.tensor([[0.1, 0.3, 0.6], [0.3, 0.2, 0.5]])
y_hat[[0, 1], y]
tensor([0.1000, 0.5000])
高级索引 : 索引列表会按位置配对,从y_hat中提取特定位置的元素
第一个元素:y_hat[0行, y[0]=0列] → 0.1
第二个元素:y_hat[1行, y[1]=2列] → 0.5
def cross_entropy(y_hat, y):return - torch.log(y_hat[range(len(y_hat)), y])cross_entropy(y_hat, y)
tensor([2.3026, 0.6931])
3.6.5 分类精度
def accuracy(y_hat, y):if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:y_hat = y_hat.argmax(axis=1)cmp = y_hat.type(y.dtype) == yreturn float(cmp.type(y.dtype).sum())