【数据可视化-42】杂货库存数据集可视化分析
🧑 博主简介:曾任某智慧城市类企业
算法总监,目前在美国市场的物流公司从事高级算法工程师一职,深耕人工智能领域,精通python数据挖掘、可视化、机器学习等,发表过AI相关的专利并多次在AI类比赛中获奖。CSDN人工智能领域的优质创作者,提供AI相关的技术咨询、项目开发和个性化解决方案等服务,如有需要请站内私信或者联系任意文章底部的的VX名片(ID:xf982831907)
💬 博主粉丝群介绍:① 群内初中生、高中生、本科生、研究生、博士生遍布,可互相学习,交流困惑。② 热榜top10的常客也在群里,也有数不清的万粉大佬,可以交流写作技巧,上榜经验,涨粉秘籍。③ 群内也有职场精英,大厂大佬,可交流技术、面试、找工作的经验。④ 进群免费赠送写作秘籍一份,助你由写作小白晋升为创作大佬。⑤ 进群赠送CSDN评论防封脚本,送真活跃粉丝,助你提升文章热度。有兴趣的加文末联系方式,备注自己的CSDN昵称,拉你进群,互相学习共同进步。

【数据可视化-42】杂货库存数据集可视化分析
- 一、引言
- 二、数据探索
- 2.1 数据集介绍
- 2.2 数据清洗探索
- 三、单维度特征可视化
- 3.1 产品类别分布
- 3.2 库存状态分布
- 3.3 库存数量分布
- 四、各个特征与库存管理关系的可视化
- 4.1 库存数量与销售量关系
- 4.2 库存周转率与销售量关系
- 4.3 产品类别与库存周转率关系
- 4.4 供应商与库存数量关系
- 4.5 多维度组合分析(类别、状态与库存数量)
- 五、完整代码
一、引言
在库存管理与销售分析中,数据可视化是优化库存水平、提升供应链效率的强大工具。本文将利用杂货库存数据集,涵盖990种产品的详细信息,从多个维度进行可视化分析,深入探讨影响库存周转、销售绩效及供应链效率的因素。以下分析包括完整的Python代码实现,可供读者参考和复现。
二、数据探索
2.1 数据集介绍
该数据集包含以下变量:
- Product_Name:产品名称
- Category:产品类别
- Supplier_Name:供应商名称
- Warehouse_Location:仓库位置
- Status:产品状态(Active/Discontinued/Backordered)
- Product_ID:产品ID
- Supplier_ID:供应商ID
- Date_Received:入库日期
- Last_Order_Date:最后订购日期
- Expiration_Date:有效期
- Stock_Quantity:库存数量
- Reorder_Level:再订购阈值
- Reorder_Quantity:再订购数量
- Unit_Price:单价
- Sales_Volume:销售量
- Inventory_Turnover_Rate:库存周转率
- Percentage:百分比
2.2 数据清洗探索
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns# 加载数据
df = pd.read_csv('grocery_inventory.csv') # 请替换为实际文件路径# 查看数据基本信息
print(df.info())
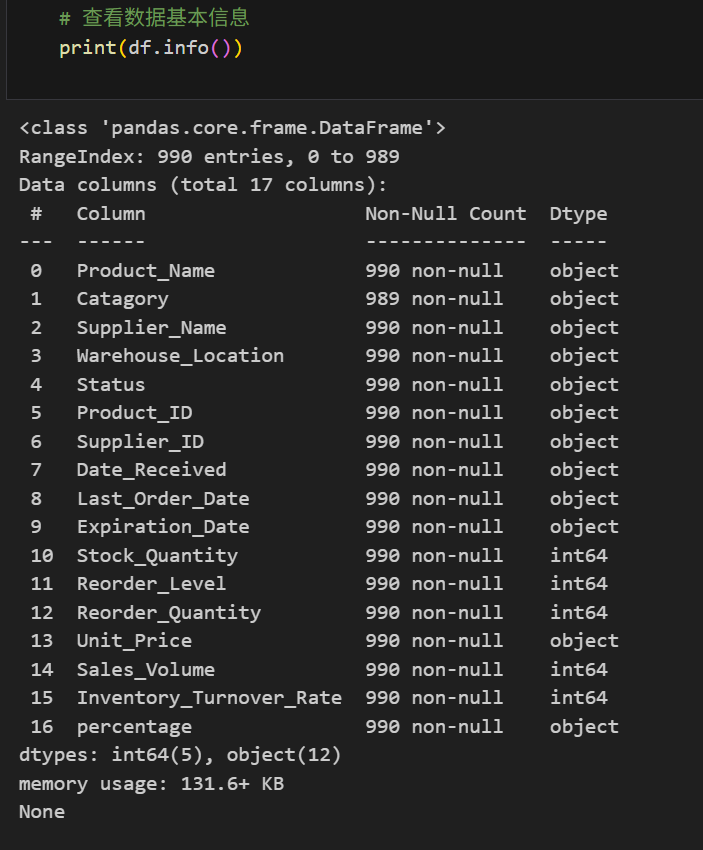
从数据基本信息可发现:
- 数据共17个维度,包含字符串、数值类型。
- 一共包含990条数据记录,其中只有Catagory字段存在一个缺失值,其它特征无缺失值的情况。
三、单维度特征可视化
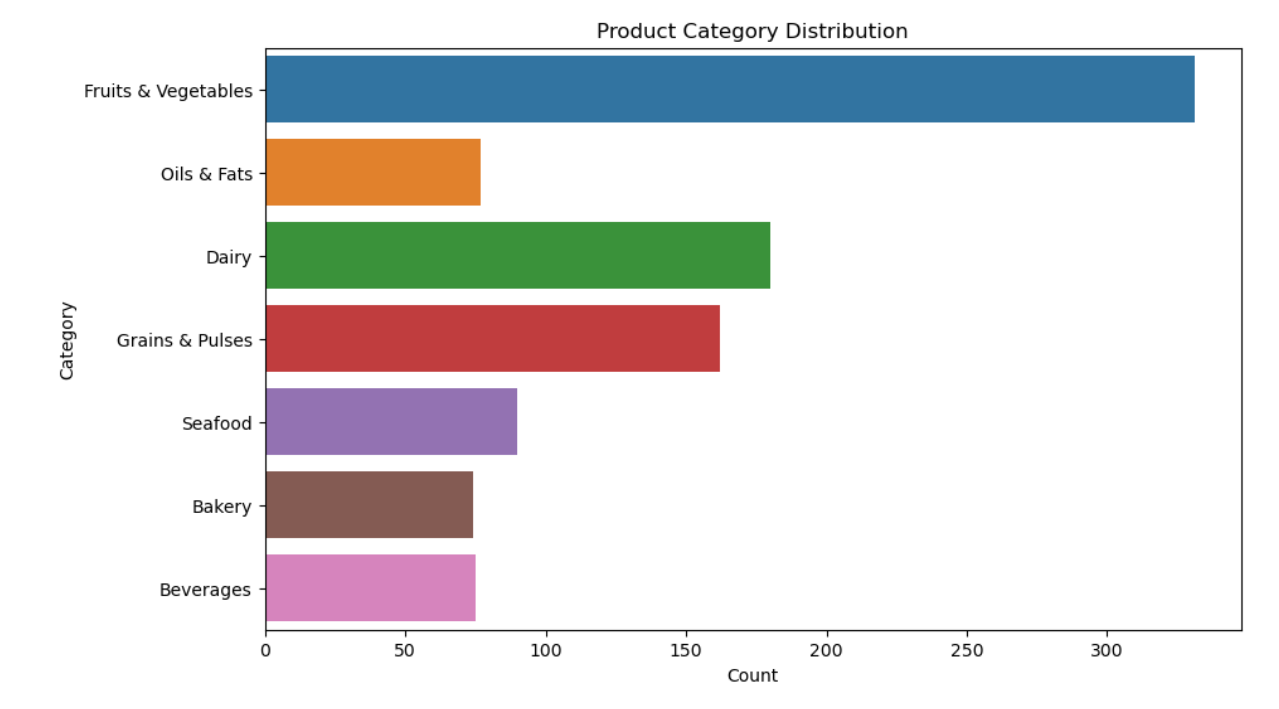
3.1 产品类别分布
plt.figure(figsize=(10, 6))
sns.countplot(y='Category', data=df)
plt.title('Product Category Distribution')
plt.xlabel('Count')
plt.ylabel('Category')
plt.show()
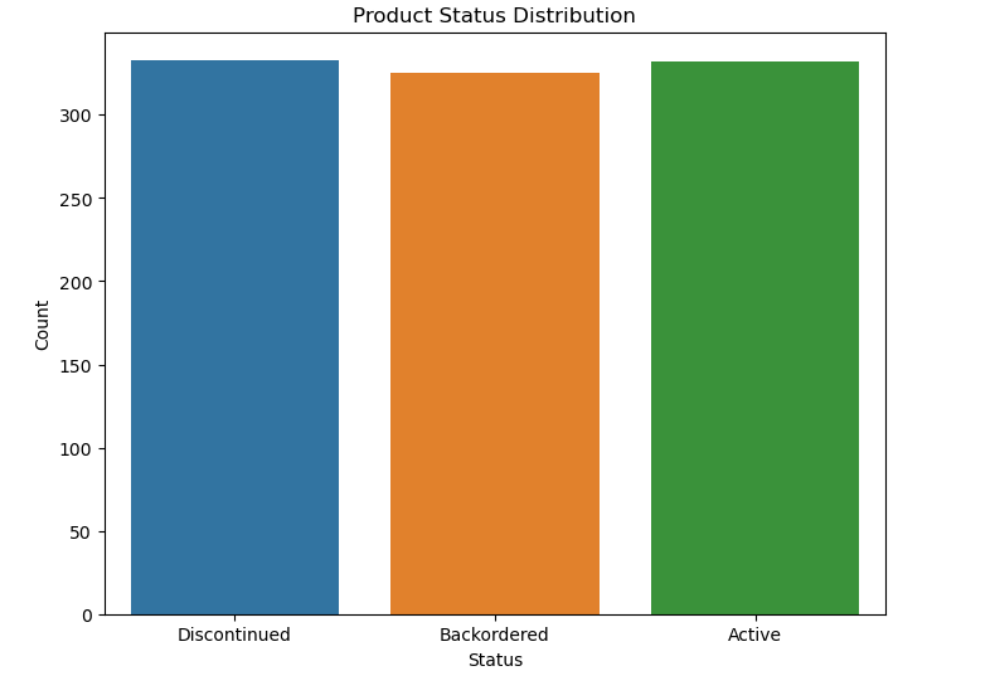
3.2 库存状态分布
plt.figure(figsize=(8, 6))
sns.countplot(x='Status', data=df)
plt.title('Product Status Distribution')
plt.xlabel('Status')
plt.ylabel('Count')
plt.show()
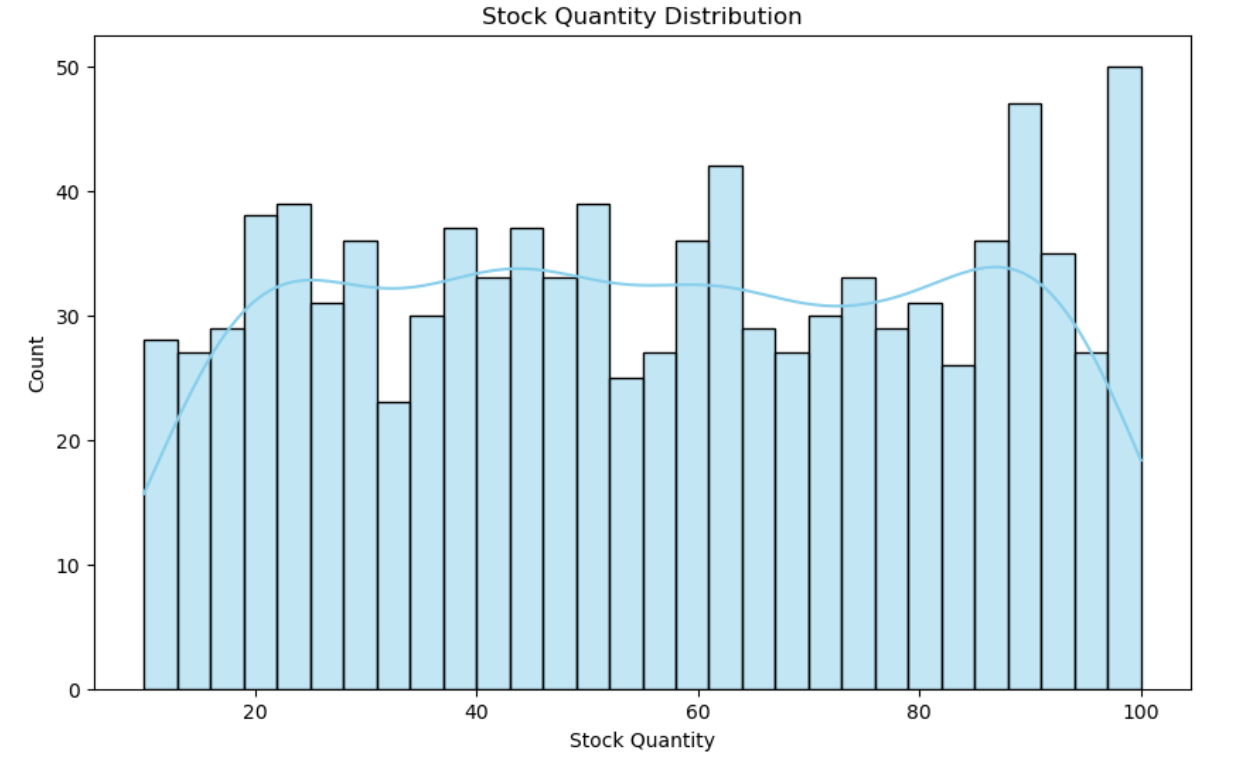
3.3 库存数量分布
plt.figure(figsize=(10, 6))
sns.histplot(df['Stock_Quantity'], bins=30, kde=True, color='skyblue')
plt.title('Stock Quantity Distribution')
plt.xlabel('Stock Quantity')
plt.ylabel('Count')
plt.show()
四、各个特征与库存管理关系的可视化
4.1 库存数量与销售量关系
plt.figure(figsize=(10, 6))
sns.scatterplot(x='Stock_Quantity', y='Sales_Volume', data=df, hue='Status', palette='Set1')
plt.title('Stock Quantity vs Sales Volume Relationship')
plt.xlabel('Stock Quantity')
plt.ylabel('Sales Volume')
plt.legend(title='Status')
plt.show()
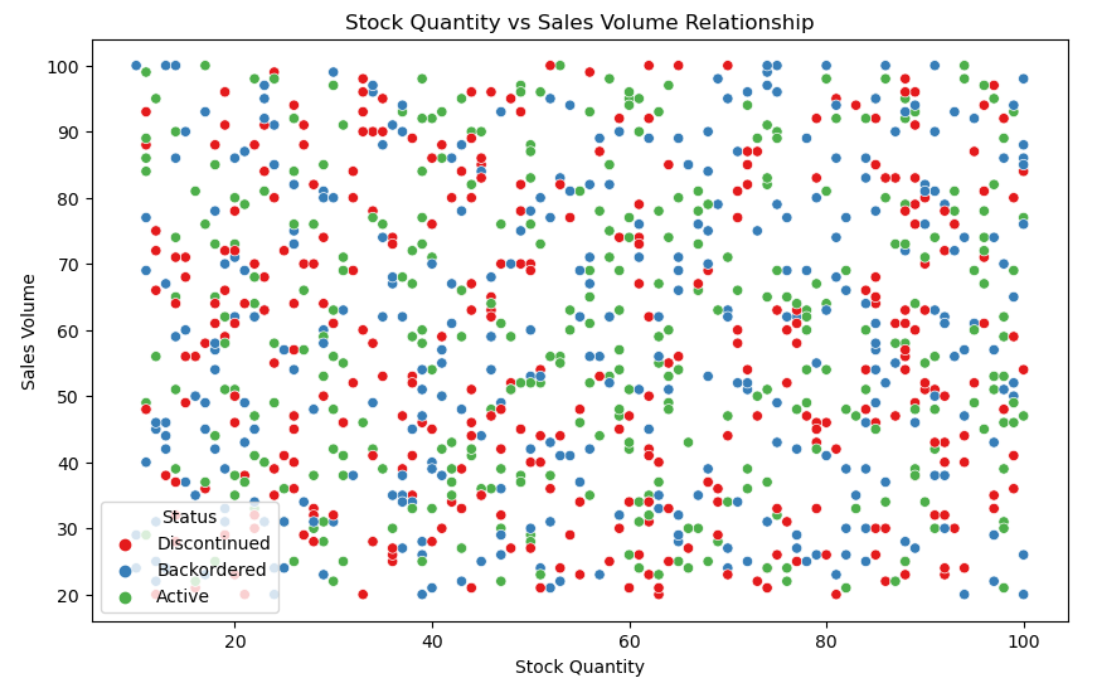
4.2 库存周转率与销售量关系
plt.figure(figsize=(10, 6))
sns.lineplot(x='Inventory_Turnover_Rate', y='Sales_Volume', data=df, marker='o', color='coral')
plt.title('Inventory Turnover Rate vs Sales Volume Relationship')
plt.xlabel('Inventory Turnover Rate')
plt.ylabel('Sales Volume')
plt.show()
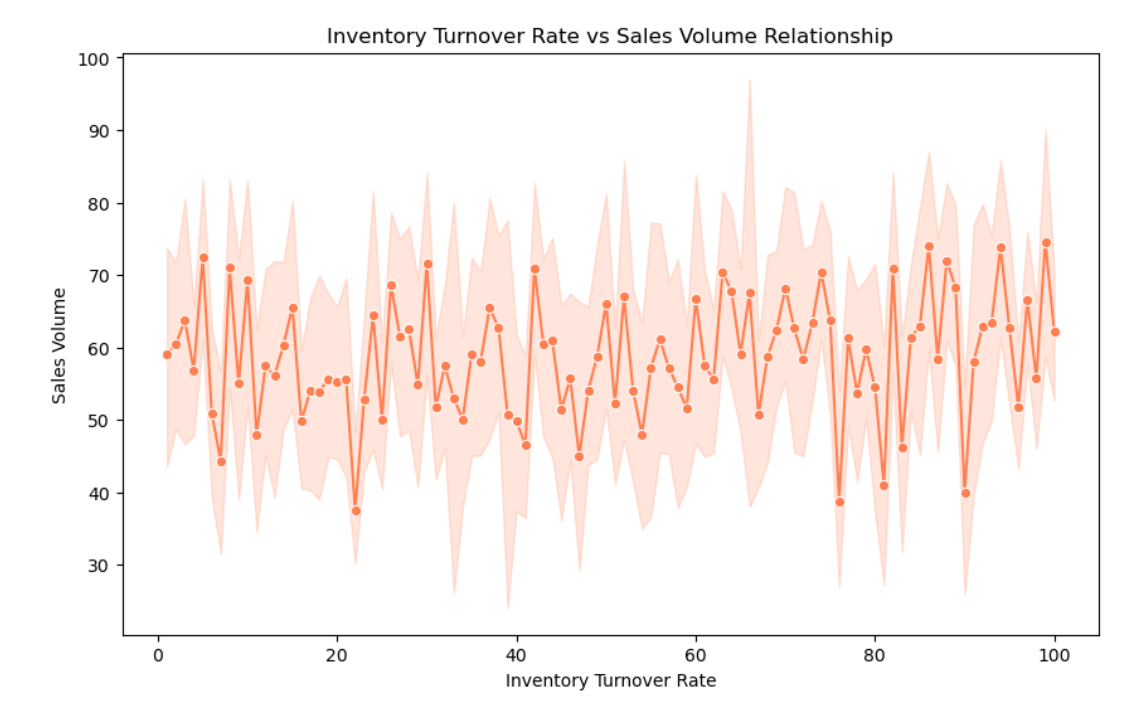
4.3 产品类别与库存周转率关系
plt.figure(figsize=(12, 6))
category_turnover = df.groupby('Catagory')['Inventory_Turnover_Rate'].mean().reset_index()
sns.barplot(x='Catagory', y='Inventory_Turnover_Rate', data=category_turnover)
plt.title('Average Inventory Turnover Rate by Category')
plt.xlabel('Category')
plt.ylabel('Average Inventory Turnover Rate')
plt.xticks(rotation=45)
plt.show()
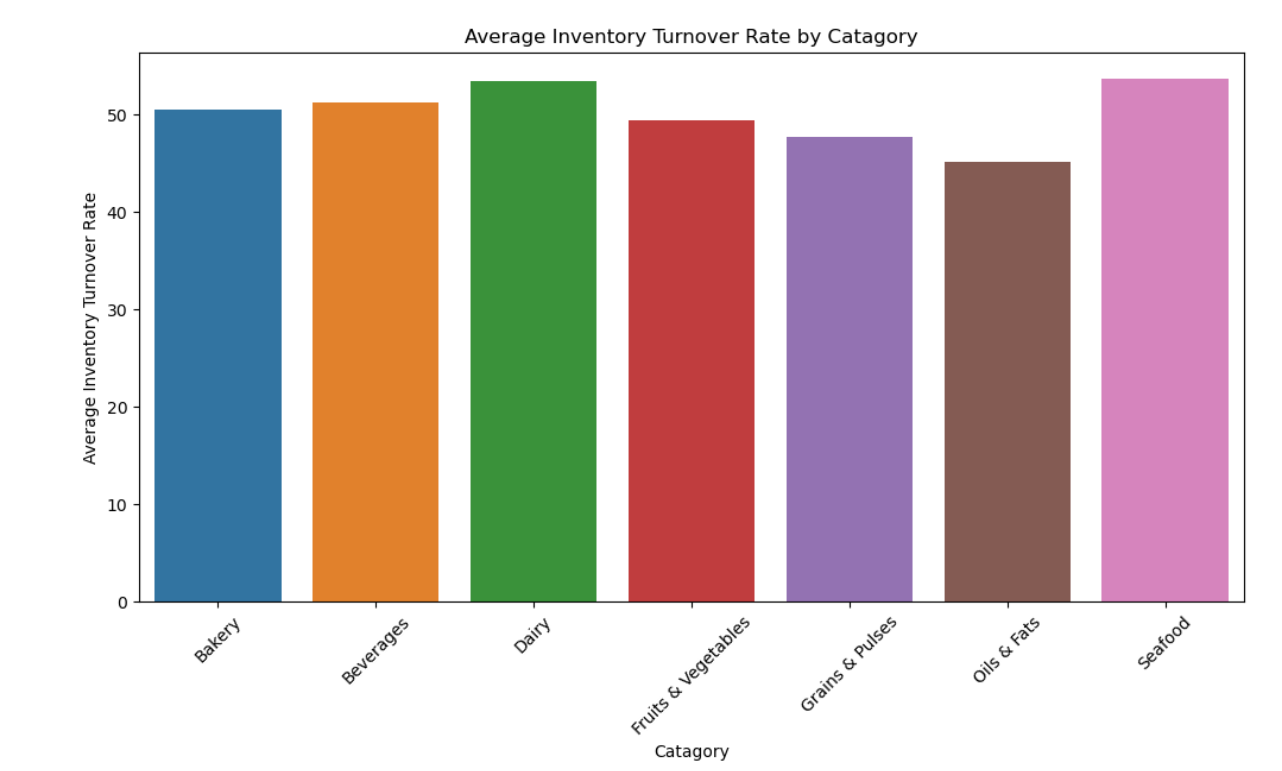
4.4 供应商与库存数量关系
plt.figure(figsize=(12, 6))
supplier_stock = df.groupby('Supplier_Name')['Stock_Quantity'].sum().reset_index()
supplier_stock = supplier_stock.sort_values('Stock_Quantity', ascending=False).head(10)
sns.barplot(x='Supplier_Name', y='Stock_Quantity', data=supplier_stock)
plt.title('Top 10 Suppliers by Stock Quantity')
plt.xlabel('Supplier Name')
plt.ylabel('Total Stock Quantity')
plt.xticks(rotation=45)
plt.show()
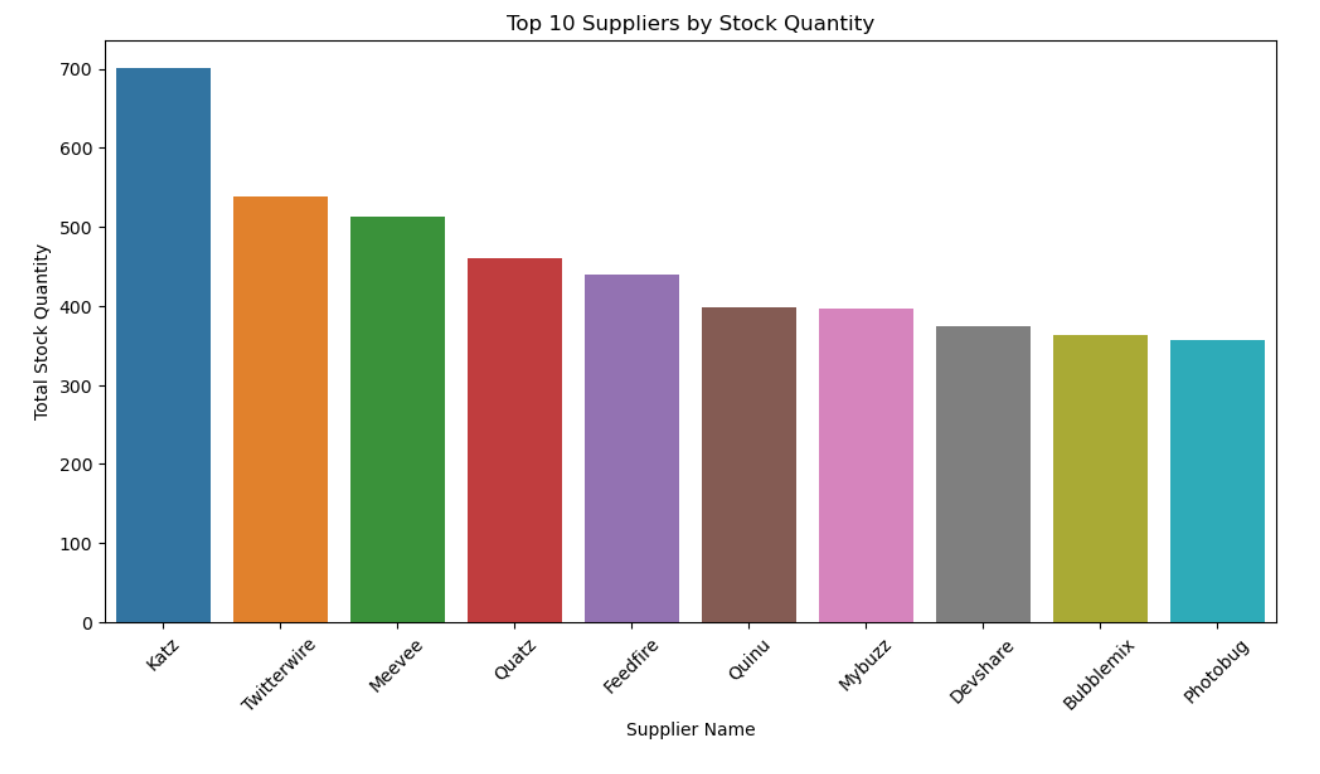
4.5 多维度组合分析(类别、状态与库存数量)
plt.figure(figsize=(12, 6))
sns.boxplot(x='Category', y='Stock_Quantity', hue='Status', data=df)
plt.title('Stock Quantity Variation by Category and Status')
plt.xlabel('Category')
plt.ylabel('Stock Quantity')
plt.xticks(rotation=45)
plt.show()
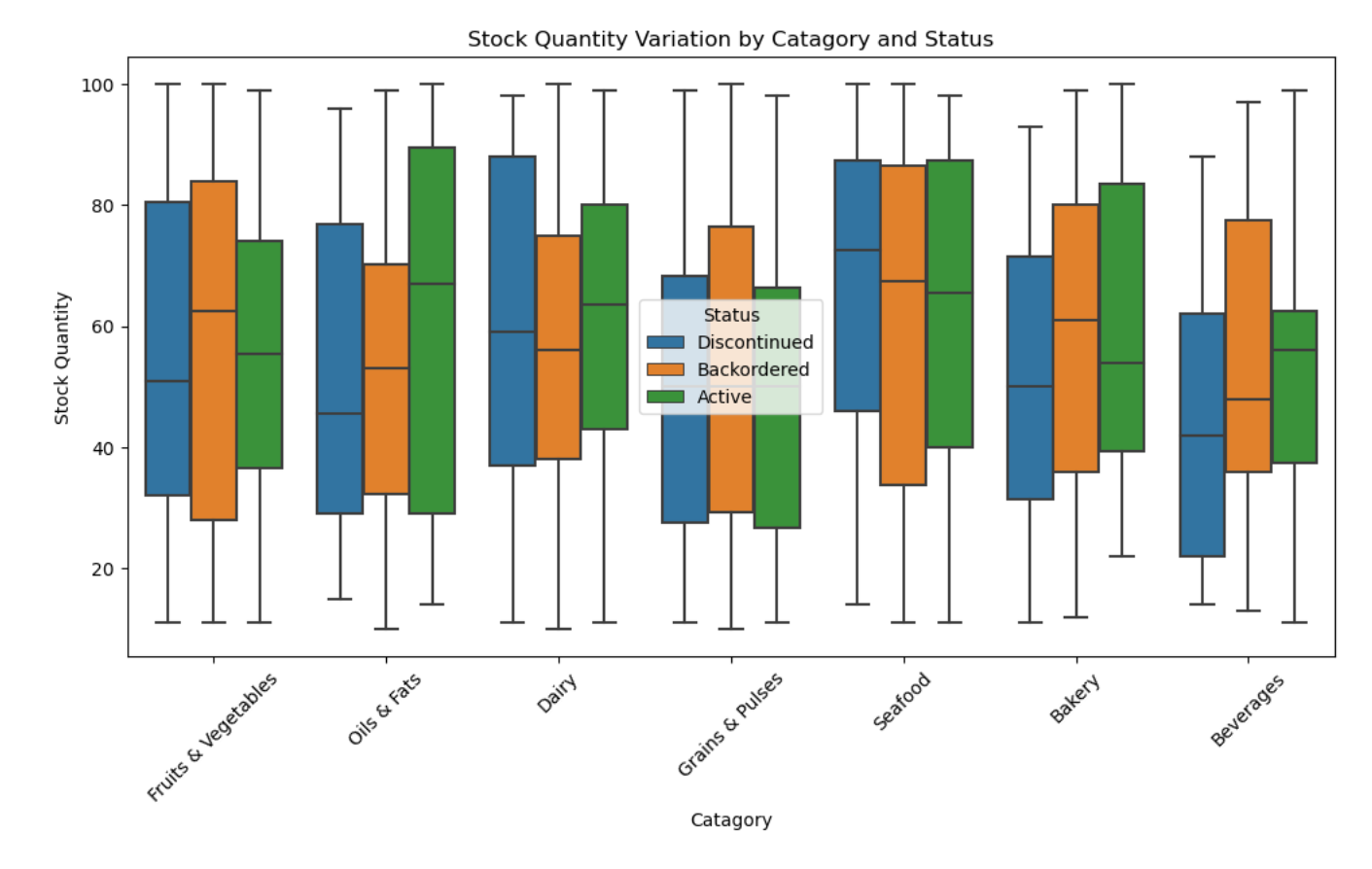
从以上可视化分析可以看出:
- 产品类别分布:不同类别产品在库存中占比差异显著。
- 库存状态分布:多数产品处于有效状态,但存在一定数量的延期交货和已停产产品。
- 库存数量分布:库存数量呈现右偏分布,少数产品占据较大库存。
- 库存数量与销售量关系:存在一定负相关关系,高库存产品销售量较低,可能为滞销品。
- 库存周转率与销售量关系:存在一定正相关关系,高周转率产品销售量较高。
- 产品类别与库存周转率:不同类别产品周转率差异明显,快消品通常周转率较高。
- 供应商与库存数量:少数供应商贡献了大部分库存,反映了供应商的重要性差异。
以上分析为优化库存管理、提升销售效率和供应链运营提供了多维度视角,帮助企业更好地做出数据驱动的决策。
五、完整代码
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns# 加载数据
df = pd.read_csv('Grocery_Inventory new v1.csv') # 请替换为实际文件路径
# 查看数据基本信息
print(df.info())plt.figure(figsize=(10, 6))
sns.countplot(y='Catagory', data=df)
plt.title('Product Category Distribution')
plt.xlabel('Count')
plt.ylabel('Category')
plt.show()plt.figure(figsize=(8, 6))
sns.countplot(x='Status', data=df)
plt.title('Product Status Distribution')
plt.xlabel('Status')
plt.ylabel('Count')
plt.show()plt.figure(figsize=(10, 6))
sns.histplot(df['Stock_Quantity'], bins=30, kde=True, color='skyblue')
plt.title('Stock Quantity Distribution')
plt.xlabel('Stock Quantity')
plt.ylabel('Count')
plt.show()plt.figure(figsize=(10, 6))
sns.scatterplot(x='Stock_Quantity', y='Sales_Volume', data=df, hue='Status', palette='Set1')
plt.title('Stock Quantity vs Sales Volume Relationship')
plt.xlabel('Stock Quantity')
plt.ylabel('Sales Volume')
plt.legend(title='Status')
plt.show()plt.figure(figsize=(10, 6))
sns.lineplot(x='Inventory_Turnover_Rate', y='Sales_Volume', data=df, marker='o', color='coral')
plt.title('Inventory Turnover Rate vs Sales Volume Relationship')
plt.xlabel('Inventory Turnover Rate')
plt.ylabel('Sales Volume')
plt.show()plt.figure(figsize=(12, 6))
category_turnover = df.groupby('Catagory')['Inventory_Turnover_Rate'].mean().reset_index()
sns.barplot(x='Catagory', y='Inventory_Turnover_Rate', data=category_turnover)
plt.title('Average Inventory Turnover Rate by Catagory')
plt.xlabel('Catagory')
plt.ylabel('Average Inventory Turnover Rate')
plt.xticks(rotation=45)
plt.show()plt.figure(figsize=(12, 6))
supplier_stock = df.groupby('Supplier_Name')['Stock_Quantity'].sum().reset_index()
supplier_stock = supplier_stock.sort_values('Stock_Quantity', ascending=False).head(10)
sns.barplot(x='Supplier_Name', y='Stock_Quantity', data=supplier_stock)
plt.title('Top 10 Suppliers by Stock Quantity')
plt.xlabel('Supplier Name')
plt.ylabel('Total Stock Quantity')
plt.xticks(rotation=45)
plt.show()plt.figure(figsize=(12, 6))
sns.boxplot(x='Category', y='Stock_Quantity', hue='Status', data=df)
plt.title('Stock Quantity Variation by Category and Status')
plt.xlabel('Category')
plt.ylabel('Stock Quantity')
plt.xticks(rotation=45)
plt.show()
如果您在后续分析中有其他问题或需要进一步的帮助,欢迎随时交流探讨!