大模型学习笔记------Llama 3模型架构之分组查询注意力(GQA)
大模型学习笔记------Llama 3模型架构之分组查询注意力(GQA)
- 1、分组查询注意力(GQA)的动机
- 2、 多头注意力(Multi-Head Attention, MHA)
- 3、 多查询注意力 (Multi-Query Attention,MQA)
- 4、 分组查询注意力(Grouped-Query Attention, GQA)
- 5、 多头注意力 (MHA) 、多查询注意力 (MQA)、分组查询注意力 (GQA)对比
上文简单介绍了 Llama 3模型架构的旋转位置编码(Rotary Position Embedding,RoPE)。本文介绍Llama 3模型的最后一个网络结构相关知识:Llama 3模型架构之分组查询注意力(Grouped-Query Attention, GQA)。实际上。在Llama 2就已经使用GQA注意力机制了。GQA是Transformer模型注意力机制的重要改进,旨在平衡计算效率与模型表现。其核心设计理念可概括为:“分组共享键值对,独立保留查询向量”。
1、分组查询注意力(GQA)的动机
Llama 3为什么采用GQA注意力机制呢?其实道理很简单,在大模型训练与推理过程中需要在保障准确率的基础上尽可能的减少计算量,减少参数数量,提高效率。这个怎样理解呢?论文里其实也提到了这个问题。主要是对比了多头注意力(Multi-Head Attention, MHA)和多查询注意力 (Multi-Query Attention,MQA)。具体三中方式的结构如下图所示:

2、 多头注意力(Multi-Head Attention, MHA)
多头注意力(Multi-Head Attention, MHA)是一种在Transformer架构中广泛使用的注意力机制,具体结构如上图A。它通过并行地使用多个注意力头来捕捉输入序列中不同的特征,增强模型的表达能力。多头注意力的基本思想是将输入的查询(Query,Q)、键(Key,K)和值(Value,V)向量通过多个注意力头进行并行处理,然后将结果拼接在一起,得到最终的输出。每个注意力头在不同的子空间中学习数据的不同特征,使得模型能够更好地理解复杂的输入。具体原理如下所示:
1)查询(Query,Q)、键(Key,K)和值(Value,V)的向量表示:

其中, 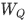 、
、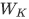 和
和 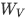 分别是查询、键和值的投影矩阵。
分别是查询、键和值的投影矩阵。
2)自注意力计算:

其中, 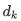 为查询和键向量的维度。
为查询和键向量的维度。
3)多头组合:


通过多个注意力头并行处理,MHA能够从不同角度关注输入数据中的信息,捕捉到更丰富的上下文关系。MHA的设计使得可以在硬件加速上,同时计算多个关注头,提高了计算效率。
3、 多查询注意力 (Multi-Query Attention,MQA)
多查询注意力(Multi-Query Attention, MQA)旨在提高注意力的效率并降低计算复杂度。相较于传统的多头注意力(Multi-Head Attention, MHA),MQA的设计采用了多个查询头,但共享相同的键和值,这使得计算更为高效,具体结构如上图B。具体计算原理如下步骤:
1)查询向量:

2)共享的键和值向量:

3)自注意力计算:

4)组合:

4、 分组查询注意力(Grouped-Query Attention, GQA)
分组查询注意力(Grouped-Query Attention, GQA)旨在通过将查询分组来提升计算效率并增强模型的能力。与多头注意力和多查询注意力相比,GQA通过将查询分成多个组并为每组独立计算注意力来优化注意力计算过程。具体结构如上图C,计算步骤如下所示:
1)查询向量:

2)分组的键和值向量:
将总计N个注意力头划分为G组,每组共享相同的键和值投影:

3)组内自注意力计算:

4)组合:

5、 多头注意力 (MHA) 、多查询注意力 (MQA)、分组查询注意力 (GQA)对比
这几种注意力机制有各自的特点,具体如下所示:
| 维度 | 多头注意力 (MHA) | 多查询注意力 (MQA) | 分组查询注意力 (GQA) |
|---|---|---|---|
| 查询数量 | 多个独立的查询 | 多个共享查询 | 分组查询,部分独立 |
| 键和值 | 每个头独立的键和值 | 共享相同的键和值 | 共享或独立的键值 |
| 计算复杂度 | 较高 | 较低 | 灵活调节,适中 |
| 应用场景 | 广泛 | 小查询任务 | 大规模模型优化 |